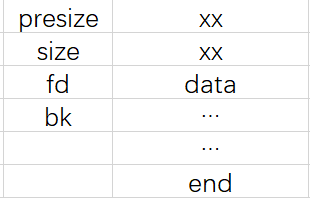
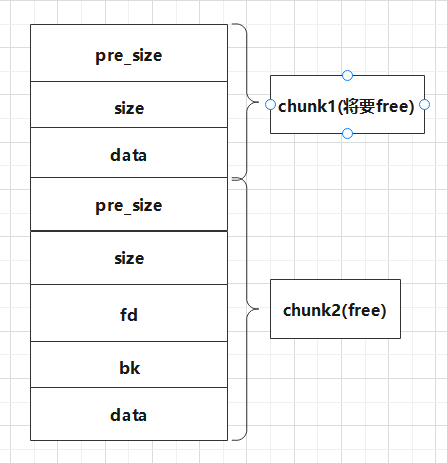
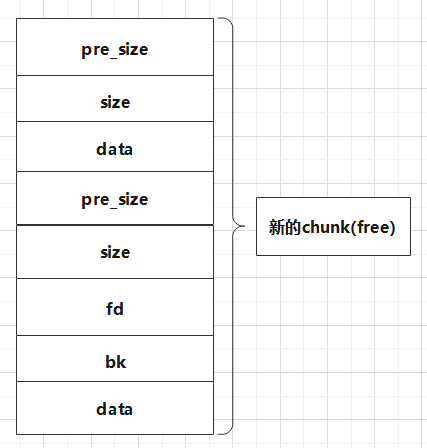
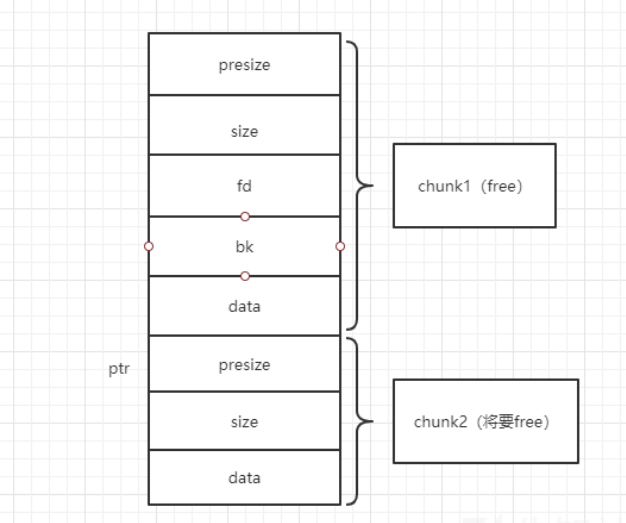
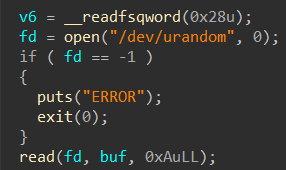
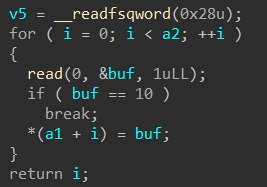
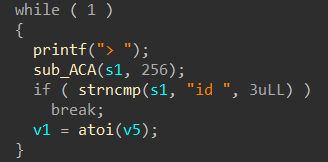
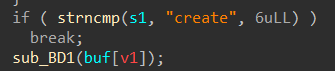
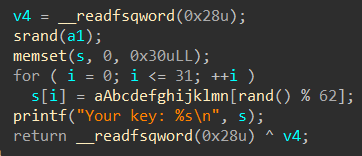
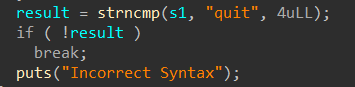
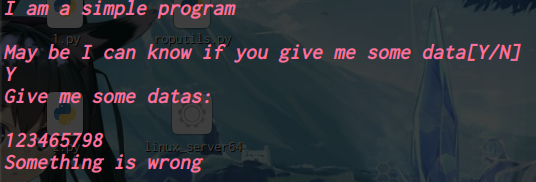
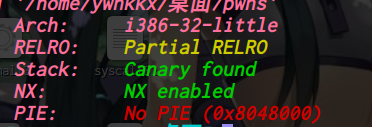
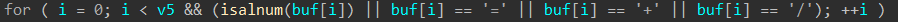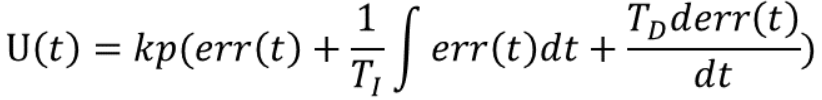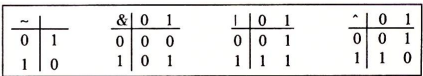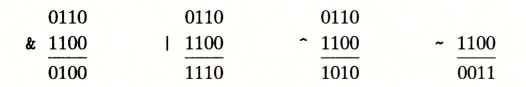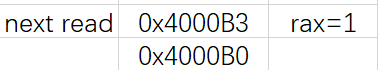从CSapp中收获的知识 CSapp 是一本很好的书,它像极了一本“技术字典”,知识十分全面但又不深入,对学习计算机有着引领性的作用
我学习CSapp 已经有一段时间了,有些章节可以调起我的兴趣,使我在网络上进行了知识扩充,但有些章节用大段大段的文字来劝退我,甚至还有一些章节玩起了“高数”,搞得我很懵逼
CSapp 上的知识太杂,太广,我感觉好多知识我都没法利用上(或许以后用得上),我害怕搞忘了这些知识,于是我也做过章节总结,但是我发现这样做的效率并不高,所以我打算不以章节为单位进行总结,而是把知识拆分为小块,逐一记录
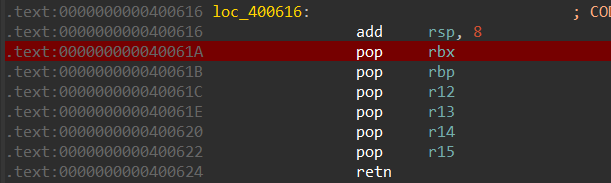
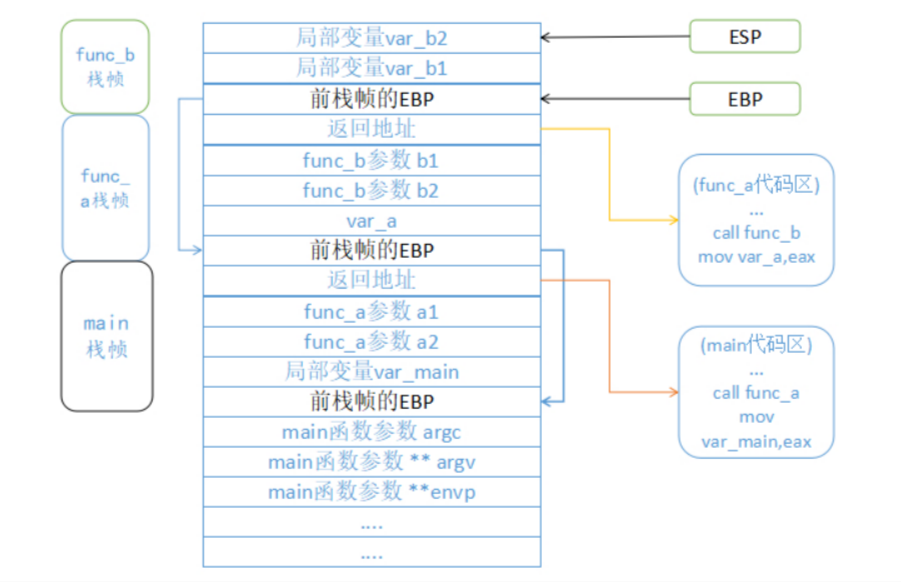
栈帧 程序执行流程 文字版本如下:
编译器驱动程序 编译器驱动程序的工作:调用语言预处理器,编译器,汇编器,链接器
详细过程:
预处理阶段 :预处理器(cpp)根据以字符 “#” 开头的命令,修改原始的 C 程序(比如 hello.c 中第 1 行的#include命令告诉预处理器读取系统头文件 stdio.h 的内容)并把它直接插入程序文本中,结果就得到了另一个 C 程序
通常是以 .i 作为文件扩展名
所谓的头文件,里面装的其实就是函数声明(libc库中的函数:scanf,printf 等)
编译阶段 :编译器(ccl)将文本文件 hello.i 翻译成文本文件 hello.s,它包含一个汇编语言程序
汇编阶段 :汇编器(as)将 hello.s 翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序(relocatable object program)的格式,并将结果保存在目标文件 hello.o 中
hello.o 文件是一个二进制文件,它包含的 17 个字节是函数 main 的指令编码
如果我们在文本编辑器中打开 hello.o文件,将看到一堆乱码(二进制)
链接阶段 :链接器(ld)就负责处理合并各个 hello.o 文件,结果就得到 hello 文件,它是一个可执行目标文件(或者简称为可执行文件),可以被加载到内存中,由系统执行
请注意,hello 程序调用了 printf 函数,它是每个 C 编译器都提供的标准 C 库中的一个函数
printf 函数存在于一个名为 printf.o 的单独的预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的 hello.o 程序中
通过修改 hello.o 可以影响最终文件 hello 的效果
抽象 抽象是从众多的事物中抽取出共同的、本质性的特征
指令集架构 是对 实际处理器硬件 的抽象
文件 是对 I/O设备 的抽象
虚拟内存 是对 程序存储器 的抽象
虚拟机 是对 整个计算机 的抽象
缓存 缓存 (cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器,通常它不像系统主存那样使用 [DRAM]技术 ,而使用昂贵但较快速的 [SRAM]技术 ,缓存的设置是所有现代计算机系统发挥高性能的重要因素之一
缓存的工作原理是当CPU要读取一个数据时,首先从CPU缓存中查找,找到就立即读取并送给CPU处理,没有找到,就从速率相对较慢的内存中读取并送给CPU处理
缓存命中
但程序需要在第 n 层中查找数据时:它会首先在第 n-1 层中查找, 如果数据刚好就在第 n-1 层中,就直接使用第 n-1 层中的数据,称为缓存命中
从第 n-1 层中读取,要比从第 n 层中读取更快
缓存不命中
另一方面,如果程序没有在第 n-1 层中查找到数据,那么它便会在第 n 层中查找,称为缓存不命中 ,同时会把第 n 层的数据写入第 n-1 层
内存阶层 速度快的存储器往往容量小,容量大的储存器往往速度慢
所以综合存储器的优劣,内存阶层的机制出现了
核心思想为:上一层(更快更小)为下一层(更大更慢)的缓存
内存阶层是在电脑架构下储存系统阶层的排列顺序,每一层于下一层相比都拥有较高的速度和较低延迟性,以及较小的容量(也有少量例外)
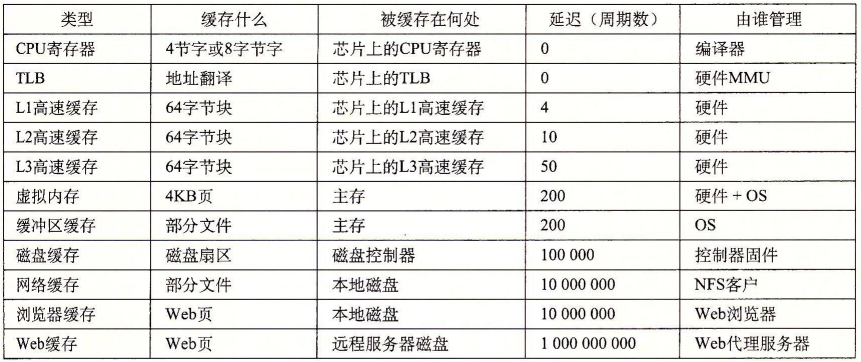
类型
位于哪里 存储容量 访问时间
CPU寄存器
位于CPU执行单元中
CPU寄存器通常只有几个到几十个,每个寄存器的容量取决于CPU的字长,所以一共只有几十到几百字节
寄存器是访问速度最快的存储器,典型的访问时间是几纳秒
Cache
和MMU一样位于CPU核中
Cache通常分为几级,最典型的是如上图所示的两级Cache,一级Cache更靠近CPU执行单元,二级Cache更靠近物理内存,通常一级Cache有几十到几百KB,二级Cache有几百KB到几MB
典型的访问时间是几十纳秒
内存
位于CPU外的芯片,与CPU通过地址和数据总线相连
典型的存储容量是几百MB到几GB
典型的访问时间是几百纳秒
硬盘
位于设备总线上,并不直接和CPU相连,CPU通过设备总线的控制器访问硬盘
典型的存储容量是几百GB
典型的访问时间是几毫秒,是寄存器的“10的6次方”倍
管理单元 计算机常用“扇区”,“簇”,“块”,“页”等概念,这些都是管理单元
扇区: (Sector)
扇区,顾名思义,每个磁盘有多条同心圆似的磁道,磁道被分割成多个部分,每部分的弧长加上到圆心的两个半径,恰好形成一个扇形,所以叫做扇区
扇区是磁盘中最小的物理存储单位(每个扇区的大小是512字节,通常4096字节)
块: (Block)
块是操作系统中最小的逻辑存储单元(例如内存块的基本组成单元:chunk)
簇:
簇是微软操作系统(DOS、WINDOWS等)中磁盘文件存储管理的最小单位
块和簇的关系:
在Windows下如NTFS等文件系统中叫做簇
在Linux下如Ext4等文件系统中叫做块
每个簇或者块可以包括2、4、8、16、32、64… “2的n次方” 个扇区
页: (page)
页是内存的最小存储单位,页的大小通常为磁盘块大小的 “2的n次方” 倍,是内存操作的基本单位
操作系统 操作系统有两目的:
1.防止硬件被失控的应用滥用
2.向应用程序提供简单一致的机制来控制复杂的低级硬件
操作系统通过几个基本的抽象 概念来实现这两个功能:
1.文件 是对 I/O设备 的抽象
2.虚拟内存 是对 程序存储器 的抽象
3.进程 是对 处理器,内存,I/O设备 的抽象
程序计数器(PC) 程序计数器(PC)是CPU控制部件中的一种,用于存放指令的地址
程序计数器是一个概念上的说法,不同的机型把不同的存储器当成程序计数器
8086:IP寄存器
i386:EIP寄存器
amd64:RIP寄存器
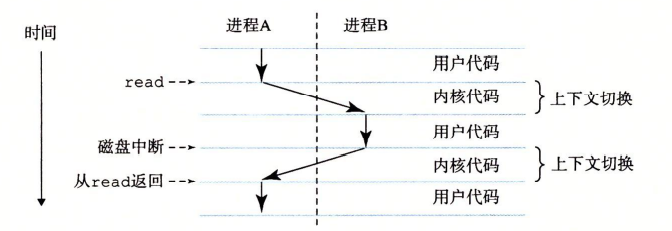
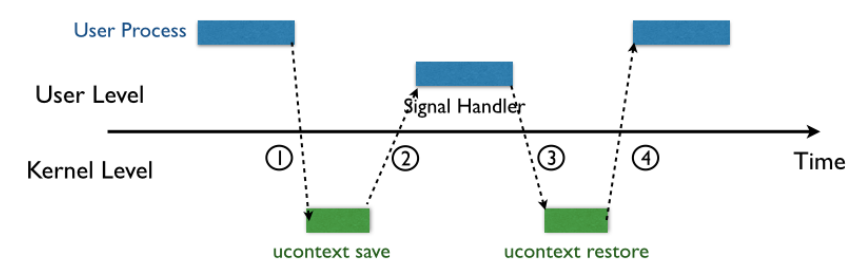
上下文切换 内核可以决定抢占当前进程,并重新开始一个被抢占的进程,这种决策叫做调度 ,是由内核中被称为“调度器”的代码处理的
上下文切换机制 用于:保存“被调度进程”的数据
进程 当程序在系统上运行时,操作系统会提供一种 假象 ,就好像系统上只有这个程序在运行一样,程序看上去是在 独占 处理器(该程序是系统资源中唯一的对象)
这些 假象 是通过 进程 这个概念来实现的
//在系统中,各种程序交替执行,而 进程 把不同功能的程序 区分 开来
在单处理器系统中:
程序想要“并发处理多个进程”时,必须要先保存当前进程的 上下文 ,然后创建新进程的 上下文
比如“hello”执行的过程就涉及到两个进程:1.shell 2.hello
系统中的每个程序都运行在某个进程的上下文中,上下文就是程序正确运行所需要的状态(包括:存放在内存中的代码和数据,栈和通用寄存器中的内容,程序计数器,环境变量,打开文件描述符的集合)
进程将会提供给应用程序两个关键的抽象:
逻辑控制流 实际上:系统中的进程是交错运行 的,每个进程执行它流的一部分,然后被抢占(暂时挂起),接着轮到其他进程
进程提供的假象:好像每个程序都在单独地 使用处理器
这种假象就是:逻辑控制流,它仿佛可以控制程序的逻辑行为,一步一步的流向,可以使用流程图 来表现这种行为的流动,方便了调试人员对程序执行流程的把控
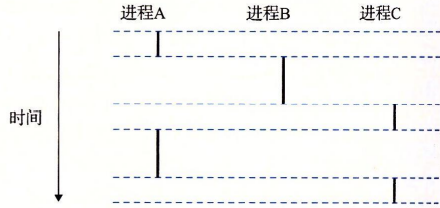
并发流 系统中的逻辑流有多种不同的形式:异常处理,进程,信号处理,线程,java进程……
并发流:在时间上,一个逻辑流和另一个逻辑流冲突,这两个流并发运行
并发:多条流在同时执行的一般现象
多任务(时间分片):多个进程流量执行的现象
私有地址空间 私有地址空间也是进程提供的假象,好像程序在单独地使用系统地址空间一样
// 私有地址空间是虚拟内存的子集
每个进程都会为所对应的程序提供一份“私有地址空间”,每个“私有地址空间”完全一致,并且只能被所对应的程序访问
进程控制 Unix提供了大量从C程序中操作进程的系统调用
僵死进程 当一个进程因为某种原因终止后,内核并不会马上把它清除,而是等待它的父进程把它回收
一个终止了但是还没有被回收的进程被称为僵死进程
如果一个进程的父进程终止了,内核会安排“init进程”成为它的“养父”(代替父进程回收子进程)
// “init进程”的PID为“1”,“调度进程”(系统进程)的PID为“0”
PID算法 PID,就是“比例(proportional)、积分(integral)、微分(derivative)”
PID控制应该算是应用非常广泛的控制算法,小到控制一个元件的温度,大到控制无人机的飞行姿态和飞行速度等等,都可以使用PID控制。这里我们从原理上来理解PID控制
线程 线程(英语:thread)是操作系统能够进行运算调度 的最小单位
线程被包含在进程之中,是进程中的实际运作单位
// 多线程 比 多进程 跟高效
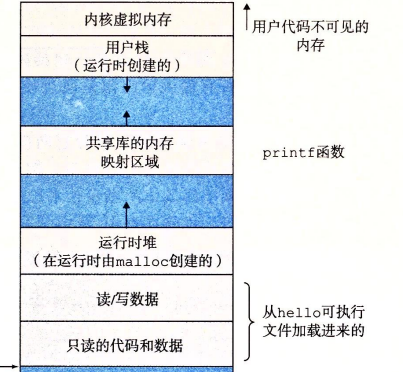
虚拟内存 虚拟内存为每个进程提供了一个假象
就好像每个进程在单独占用 内存空间一样,每个进程中看到的内存是一样的(虚拟地址空间)
即:该进程是系统资源中唯一的对象
物理内存是不连续的,但是操作系统完成了“使内存看起来是连续的”这样一份抽象,创造了 虚拟内存 ,并且为虚拟内存中的各个空间进行了编号
虚拟内存用户空间 每个进程各一份
虚拟内存内核空间 所有进程共享一份
虚拟内存 mmap 段中的动态链接库 仅在物理内存中装载一份
虚拟内存的作用
硬件只能识别“物理地址”,而“物理地址”是不连续的并且不方便显示,这就给调试程序带来了巨大的影响
所以操作系统抽象出了“虚拟内存”,把硬件中的数据映射到“虚拟内存”中,方便了调试
虚拟内存作为缓存工具 VM系统(虚拟程序系统)将虚拟内存分割成块,这些块被称为虚拟页
每个虚拟页的大小为“P = 2的p次方”字节,类似地,物理内存被分割为物理页,大小也为P字节(物理页也被称为“页帧”)
在任意时刻,虚拟页面的集合都分为3个不相交的子集:
未分配的:VM系统还未分配的页,没有数据和它们相关,不占用磁盘空间
缓存的:当前已缓存在物理内存中的已分配页
未缓存的:当前未缓存在物理内存中的已分配页
Proc文件系统 Proc文件系统是一个伪文件系统,它只存在于内存中(不占用外存空间),允许“用户模式进程”访问“内核数据结构”的内容
Proc文件系统将许多“内核数据结构”的内容输出为一个用户程序可以读的“文本文件”
Unix I/O 一个 Linux 文件就是一个 m 个字节的序列,所有的 I/O 设备(例如网络、磁盘和终端)都被模型化为文件,而所有的输入和输出都被当作对相应文件的读和写来执行
这种将设备优雅地映射为文件的方式,允许 Linux 内核引出一个简单、低级的应用接口,称为 Unix I/O,这使得所有的输入和输出都能以一种统一且一致的方式来执行:
打开文件 :一个应用程序通过要求内核打开相应的文件,来宣告它想要访问一个 I/O 设备,内核返回一个小的非负整数,叫做 描述符 ,它在后续对此文件的所有操作中标识这个文件,内核记录有关这个打开文件的所有信息,应用程序只需记住这个描述符改变当前的文件位置 :对于 每个打开的文件 ,内核保持着一个 文件位置 (符号为 k),初始为 0,这个文件位置是 从文件开头起始的字节偏移量(相当于“指向”内存中文件末尾的一个标记,也可以用来记录该文件在内存中的大小) ,应用程序能够通过执行 seek 操作,显式地设置文件的当前位置为 k读写文件 :一个读操作就是 从文件复制 n > 0 个字节到内存(从当前文件位置 k 开始,然后将 k 增加到 k+n) ,假设给定一个大小为 m 字节的文件,当 k>=m 时(文件被完全读入内存)会触发一个称为 end-of-file(EOF)的条件,应用程序能检测到这个条件,在文件结尾处并没有明确的“EOF符号”,类似地,写操作就是 从内存复制 n > 0 个字节到一个文件)从当前文件位置 k 开始,然后更新 k) 关闭文件 :当应用完成了对文件的访问之后,它就通知内核关闭这个文件,作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池中 ,无论一个进程因为何种原因终止时,内核都会关闭所有打开的文件并释放它们的内存资源
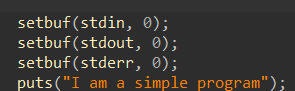
Linux shell 创建的每个进程开始时都有三个打开的文件:标准输入 (描述符为 0)、标准输出 (描述符为 1)和 标准错误 (描述符为 2),头文件 定义了常量 STDIN_FILENO、STDOUT_FILENO 和 STDERR_FILENO,它们可用来代替显式的描述符值
文件 文件就是 字节序列
系统中所有的输入输出都是通过使用 Unix I/O 的 系统函数 来实现的,文件向应用程序提供了一个 统一的视图 ,来看待系统中可能含有的各种形式的 I/O设备 ,在linux操作系统中有一个思想“一切皆文件”,即使是内存中的进程都可以被当成文件输出
每个 Linux 文件都有一个 类型 (type)来表明它在系统中的角色:
普通文件 (regular file):包含任意数据,应用程序常常要区分 文本文件 和 二进制文件 ,文本文件是只含有 ASCII 或 Unicode 字符的普通文件,二进制文件是所有其他的文件
对内核而言,文本文件和二进制文件没有区别
Linux 文本文件包含了一个 文本行 (text line)序列,其中每一行都是一个字符序列,以一个新行符(“\n”)结束
新行符与 ASCII 的换行符(LF)是一样的,其数字值为 0x0a
目录 (directory):是包含一组 链接 的文件,其中每个链接都将一个 文件名 映射到一个文件,这个文件可能是另一个目录
每个目录至少含有两个条目:是到该目录自身的链接,以及是到目录层次结构中 父目录 的链接
你可以用 mkdir 命令创建一个目录,用 Is 查看其内容,用 rmdir 删除该目录
套接字 (socket):是用来与另一个进程进行跨网络通信的文件
其他文件类型包含 命名通道 (named pipe)、 符号链接 (symbolic link),以及 字符和块设备 (character and block device)
RIO-健壮地读写 我们会讲述一个 I/O 包,称为 RIO(Robust I/O,健壮的 I/O)包,它会自动为你处理上文中所述的不足值,在像网络程序这样容易出现不足值的应用中,RIO 包提供了方便、健壮和高效的 I/O
RIO 提供了两类不同的函数:
无缓冲的输入输出函数 :这些函数直接在内存和文件之间传送数据,没有应用级缓冲,它们对将二进制数据读写到网络和从网络读写二进制数据尤其有用带缓冲的输入函数 :这些函数允许你高效地从文件中读取文本行和二进制数据,这些文件的内容缓存在应用级缓冲区内,类似于为 printf 这样的标准 I/O 函数提供的缓冲区
与【110】中讲述的带缓冲的 I/O 例程不同,带缓冲的 RIO 输入函数是线程安全的,它在同一个描述符上可以被交错地调用
例如,你可以从一个描述符中读一些文本行,然后读取一些二进制数据,接着再多读取一些文本行
共享文件 可以用许多不同的方式来共享 Linux 文件,内核用三个相关的数据结构来表示打开的文件:
描述符表 (descriptor table):每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个表项文件表 (file table):打开文件的集合是由一张文件表来表示的,所有的进程共享这张表,每个文件表的表项组成:
包括当前的 文件位置 、引用计数 (reference count)(即当前指向该表项的描述符表项数),以及一个 指向 v-node 表 中对应表项的指针
关闭一个描述符会减少相应的文件表表项中的引用计数
内核不会删除这个文件表表项,直到它的引用计数为零
v-node 表 (v-node table):同文件表一样,所有的进程共享这张 v-node 表,每个表项包含 stat 结构中的大多数信息,包括 st_mode 和 st_size 成员
网络 系统并不是由 孤立的 硬件和软件组成的结合体,而是可以通过 网络 相互通信
对于一个单独的系统而言,网络可以认为是一个I/O设备 (输入或输出数据到本机)
并发和并行 计算机的发展始终围绕两个目的:1.更多 2.更快
并发 :指一个同时具有多活动的系统
并行 :指使用 并发 来使一个系统运行得更快
并行可以在计算机系统的多个 抽象层次 中运用,其中最主要的有3个:
1.线程级并发
构建在进程这个抽象之上,我们可以设计出有多个 “程序执行工具” 的系统,这导致了 并行
这个“程序执行工具”就是线程,使用线程,我们甚至可以在一个进程中执行多个 控制流
2.指令级并行
构建在较低的抽象层次上,使处理器可以同时执行 多条指令
3.单指令,多数据并行
构建在较最的抽象层次上,允许一条指令可以产生多个“并行执行” 的操作
//即SIMD 并行
指令集架构 指令集架构(InstructionSetArchitecture)
描述:指的是CPU机器码所使用的指令的集合以及其背后的寄存器体系、总线设计等逻辑框架 ,也是规定的一系列CPU与其他硬件电路相配合的指令系统
作用:定义 机器级程序 的格式和行为,它定义了 处理器状态 , 指令的格式 ,以及 每条指令的影响
行为:每条指令顺序执行 ,一条指令完成后,另一条指令开始
//不同进程中的指令会被CPU并发 处理,但是就一个进程而言,它的指令是“顺序执行” 的
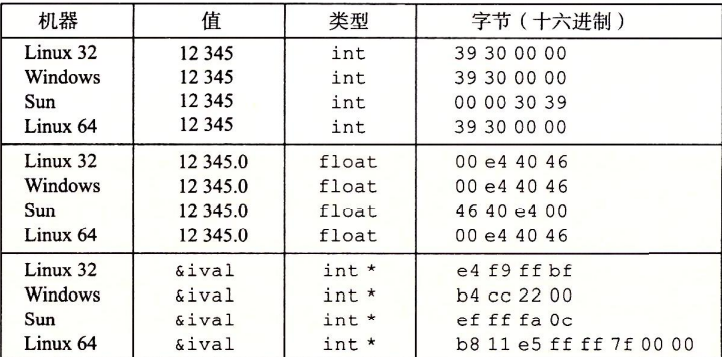
字节序 大端序:符合人类的认知(低地址存低位,高地址存高位)
小端序:利用机器的运算(低地址存高位,高地址存低位)
为了方便阅读程序,我们通常把低地址写在上面,把高地址写在下面
// 这样小端序就“符合人类的认知”
不同的系统采用不同的字节序
1 2 3 4 5 6 7 8 9 void test_show_bytes (int val) int ival = val; float fval = (float ) ival; int *pval = &ival; show_int(ival); show_fload(fval); show_pointer(pval); }
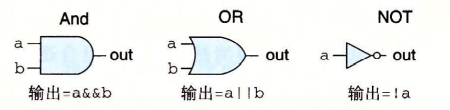
布尔代数 将逻辑值True和False用二进制值“1”和“0”表示,设计出了一种代数
基础逻辑运算:“ ~ ”(非),“ & ”(或),“ | ”(与),“ ^ ”(异或)
过程 过程是软件中一种很重要的抽象,它提供了一种 封装 代码的方式,用一组 指定的参数 和一个 可选择的返回值 实现了某种功能,而程序可以在任何一个位置引用这种功能
设计良好的软件用 过程 作为抽象机制,隐藏某个行为的具体表现,同时又提供清晰简洁的 接口定义 ,说明需要计算的是哪些值,过程会对程序状态产生什么影响
过程在不同的编译语言 中有不同的名称:函数(Function),方法(method),子例程,处理函数
嵌套数组&变长数组 嵌套数组:(多维数组)
1 2 3 4 int A[5 ][3 ]------------------------ typedef int row3_[3 ];row3_t A[5 ];
两者是等价的
变长数组:
变长数组既数组大小待定的数组, C语言中结构体的最后一个元素可以是大小未知的数组,也就是所谓的0长度,所以我们可以用结构体来创建变长数组
1 2 3 4 typedef struct { int len; int array []; }SoftArray;
异质的数据结构 c语言提供了两种不同类型的对象组合到一起创建数据类型的机制:
1.结构(structure) 2.联合(union)
structure可以将多个对象集合到一个单位中
union可以用几种不同的类型来引用一个对象
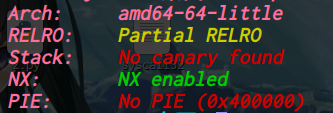
缓存区保护 1.栈随机化
使栈在每一次加载时都会发生变化
对抗:空操作雪橇,在shellcode前面插入相等长度的“nop”,只要有一个地址命中“nop”就行
//汇编指令“nop”让IP指针+1,没有其他作用
2.栈破坏机制
Canary(金丝雀)是系统生成的一个随机数,如果它被破坏,系统就会强行终止程序
3.限制可执行权限
伪指令 以“ . ”开头的指令就是 伪指令 ,它们告诉汇编器调整地址 ,以便在那里产生代码或插入一些数据
例如:伪指令“.pos 0”告诉汇编器应该从地址“0”开始产生代码
控制语言(HCL) 大多数现代的电路技术都是用信号线上的高低电压 来表示不同的值
//逻辑1用1.0伏特的高电压,逻辑0用0.0伏特的低电压
为了方便编程,硬件描述语言HDL (Hardware Description Language)诞生了
HDL是一种文本表示,和编程语言类似,但是它是用来描述 硬件结构 而不是 程序行为 的
HCL语言只表达硬件设计的控制逻辑 部分,只有有限的操作集合(控制逻辑是处理器中最困难的)
逻辑门 逻辑门是数字电路的基本计算单元,它们的产生和输出,等于它们输入位数的某个布尔函数
组合电路 将很多的逻辑门组合成一个网,就可以构建出一个计算块 (computational block),称为组合电路
优化编译器的能力 这两个函数有相同的功能,但CPU读写效率却有不同:
第一个函数需要:2次读 xp,2次读 yp,2次写 *xp
第二个函数需要:1次读 xp,1次读 yp,1次写 *xp
程序性能的表示 我们引入度量标准:每元素的周期数 (Cycles Per Element),作为一种表示程序性能并指引我们改进代码的方法
处理器活动的顺序是由时钟控制的,时钟提供了某个频率的规律信号,通常用千兆赫兹 ,十亿周期每秒来表示
例如:一个系统有“4GHz”处理器,表示这个系统的处理器时钟运行频率为4 * 10的9次方 /每秒
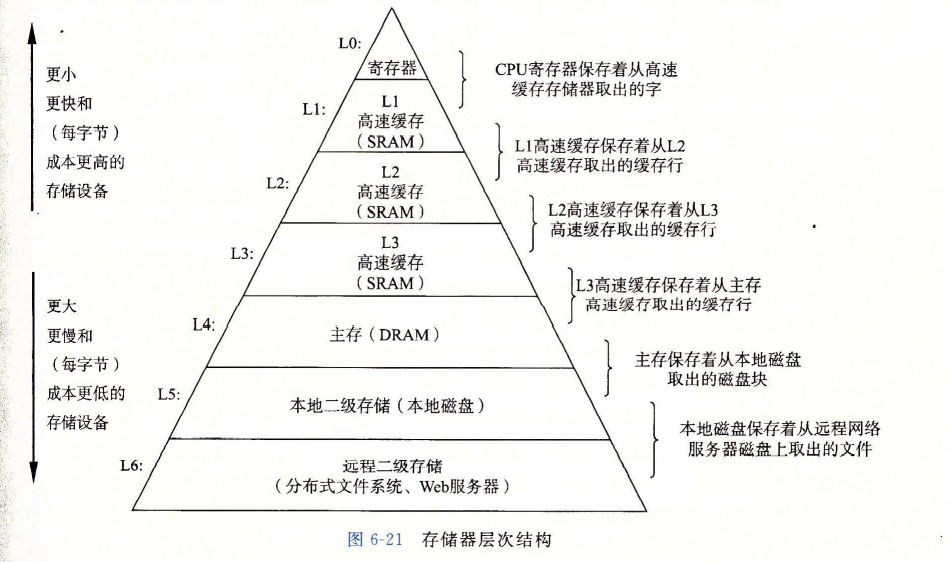
存储器系统 存储器系统是一个具有不同容量,成本,访问时间 的存储设备层次结构
靠近CPU的,小的,快速的,称为高速缓存存储器
这个思想围绕着计算机程序的一种称为 局部性 的基本属性,具有良好局部性的程序倾向于一次又一次地访问相同的 数据项集合 ,或是倾向访问邻近的 数据项集合 ,并且更多的倾向于从存储器层次结构中较高层次处访问 数据项集合 ,这些操作都可以使程序运行得更快
局部性 简述
原指处理器在访问某些数据时短时间内存在重复访问,某些数据或者位置访问的 概率极大 ,大多数时间只访问局部的数据(随着优化技术的提升,局部性的概念也得到了扩充)
其实就是概率的不均等,这个宇宙中,很多东西都不是平均分布的,平均分布是概率论中几何分布的一种特殊形式,非常简单,但世界就是没这么简单。我们更长听到的发布叫做高斯发布,同时也被称为正态分布,因为它就是正常状态下的概率发布,起概率图如下 :
时间局部性(Temporal locality):
如果某个信息这次被访问,那它有可能在不久的未来被多次访问
时间局部性是空间局部性访问地址一样时的一种特殊情况,这种情况下,可以把常用的数据加cache (缓存)来优化访存
空间局部性(Spatial locality):
如果某个位置的信息被访问,那和它相邻的信息也很有可能被访问到
这个也很好理解,我们大部分情况下代码都是顺序执行,数据也是顺序访问的
内存局部性(Memory locality):
访问内存时,大概率会访问连续的块,而不是单一的内存地址,其实就是 空间局部性在内存上 的体现
目前计算机设计中,都是以块/页为单位管理调度存储,其实就是在利用空间局部性来优化性能
分支局部性(Branch locality)
这个又被称为顺序局部性,计算机中大部分指令是顺序执行,即便有if这种选择分支,其实大多数情况下某个分支都是被大概率选中的
于是就有了CPU的分支预测优化,设计CPU优先选择 概率较大 的if分支
等距局部性(Equidistant locality)
等距局部性是指如果某个位置被访问,那和它 相邻等距离的连续地址 极有可能会被访问到,它位于空间局部性和分支局部性之间
举个例子,比如多个相同格式的数据数组,你只取其中每个数据的一部分字段,那么他们可能在内存中地址距离是等距的,这个可以通过简单的线性预测就预测是未来访问的位置
步长对局部性的影响
步长:连续序列号的差值
两个函数只是交互了循环的次序,但程序的性能却截然不同
第一个程序:步长为“4”(int类型) [ 4 - 0 ]
第二个程序:步长为“12”(int类型 * 3)[ 12 - 0 ]
第一个程序的性能远高于第二个程序(步长越长,性能越差)
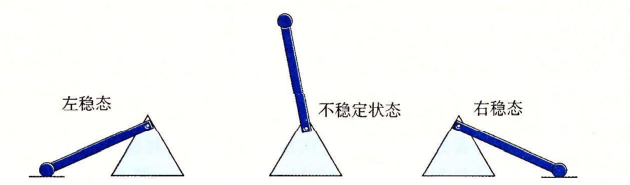
存储技术 静态RAM (SRAM)
SRAM将每个位 存储在一个 双稳态 的存储器单元中(每个单元通常是用一个 6晶体管电路 来实现的)
这个电路有这样一个属性:它可以无限期地保持 “两个不同的电压配置” 中的一个
这个双稳态 的存储器单元就像图中的钟摆一样,除了左右稳态以外的任何区域都是不稳定的
只要有电,它就会永远保持它的值,即使有外界干扰也会马上回复
动态RAM (DRAM)
DRAM将每个位 存储为一个 电容的充电 (每个单元由一个 电容 和一个 访问晶体管 组成)
和SRAM有着较强的稳定性不同,DRAM对干扰非常敏感,电容电压被扰乱以后就不会恢复了
DRAM芯片被封装在内存模块中
内存模块 (Memory Module)是指一个 印刷电路板 表面上有镶嵌数个 记忆体 , 芯片chips (碎片),而这 内存芯片 通常是 DRAM芯片
增强型DRAM
快页模式DRAM(FPM DRAM)
扩展数据DRAM(EDO DRAM)
同步DRAM(SDRAM)
双倍数据速率同步DRAM(DDR SDRAM)
视频RAM(VRAM)
只读存储器ROM (ROM是一种非易失性存储器)
如果计算机突然断电,DRAM和SRAM都会失去它们的数据,所以它们是易失的
在失去电源的情况下,数据也不会丢失的存储器就是非易失性存储器
最开始的ROM是真的“只读”的,但是随着技术的发展,ROM也慢慢“可读”了起来
可编程ROM (PROM)
PROM只能每编程一次(PROM的每个存储器单元都有一种熔丝(fuse),只能被高温熔断一次)
可擦写可编程ROM (EPROM)
EPROM有一个透明的石英窗口,允许光线到达存储单元,当紫外线射过窗口时,EPROM单元会被清除为“0”,对EPROM的编程需要通过特殊设备(把“1”写入EPROM),EPROM总共可以擦除重编程的次数为:10的3次方
电子可擦除PROM (EEPROM)
EEPROM和EPROM类似,只不过不用特殊设备就可以对它进行编程,可以直接在印制电路卡上进行编程,EEPROM总共可以被编程的次数为:10的5次方
闪存 (flash memory)
闪存基于EEPROM,是一种重要的存储技术(U盘就是利用Flash实现的)
与前面的PROM,EPROM,EEPROM以 位 为单位不同,Flash以 块 为单位(128kb,256kb)
Flash的基本构成单位为浮栅场效应管 (这是一个三端器件,分别为:源极,漏极,栅极)
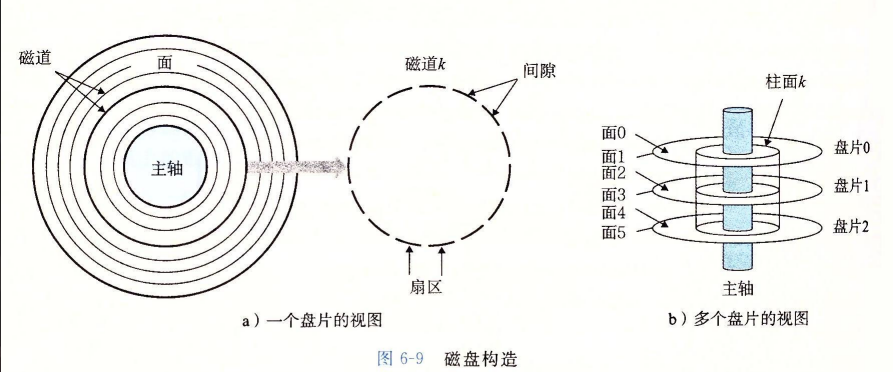
磁盘
磁盘是用于大量存储数据的存储设备,存储数据的数量级可以达到几千千兆字节,但从磁盘上读取数据的时间为毫秒级,比DRAM慢了10万倍,比SRAM慢了100万倍
磁盘由多个重叠在一起的盘片组成,它们被封装在一个密封的包装中
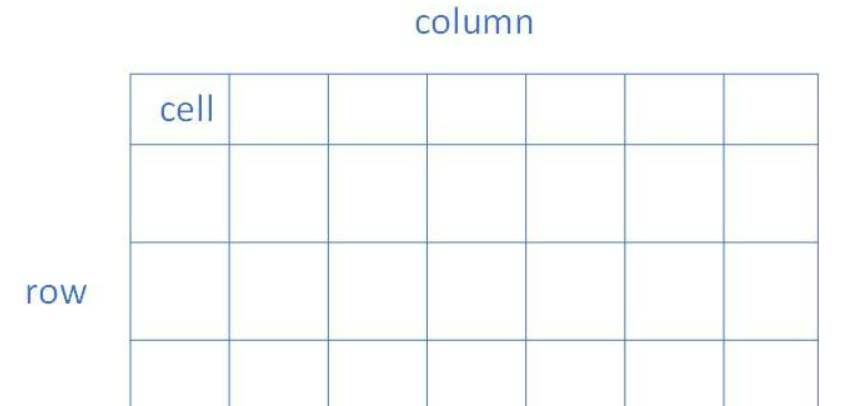
内存结构 在内存调试时,经常需要用到rank、bank等参数,可以看到电脑的内存条中,有很多一片一片的芯片,这就是内存芯片,也是叫内存颗粒
内存的基本单元称为 cell ,cell按行( row )、列( column )分布组成一个 bank
一颗内存颗粒由多个 bank 组成,现在的内存颗粒一般是8个bank,每个bank对于内存来说是平等的关系,因为内存控制器的原因,每个时钟周期只能对一个bank进行操作
所有在内存容量关系中:颗粒 > bank > row , column > cell
IO桥接器 数据通过总线进行流通,每次CPU和主存之间的数据传输都是通过一系列步骤完成的,这些步骤被称为总线事务
读事务:把数据从主存传输到CPU
写事务:把数据从CPU传输到主存
而现代计算机中IO是通过 共享一条总线 的方式来实现的,这就是 IO总线 (I/O bus)
而IO桥接器 则是一组芯片组(其中包括内存控制器)
CPU芯片,IO桥接器,DRAM内存模块
系统总线(system bus)连接了CPU和IO桥接器
内存总线(memory bus)连接IO桥接器和主存
系统总线和内存总线都通过IO桥接器连接到IO总线上,这就实现了各个硬件之间的交互
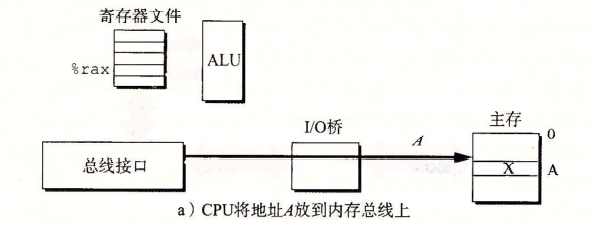
在这个过程中:CPU上被称为总线接口 的电路会在总线上发起“读事务”
//交换“A”和“%rax”位置,则会发起“写事务”
CPU会把A放到系统总线上,IO桥接器将信号传递到内存总线,传输到主存
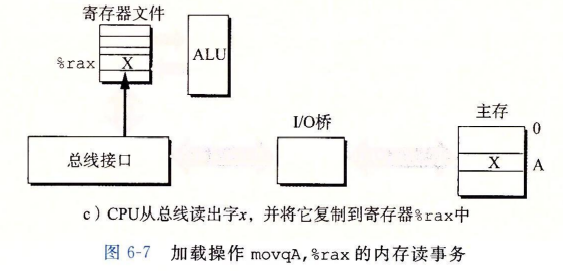
接下来主存会识别内存总线上的地址信号,从内存总线中读取地址,从DRAM中取出数据字,并将数据写入内存总线通过IO桥又写入系统总线,传输到CPU
最后CPU会读取系统总线上的数据,赋值给寄存器rax
链接器 链接(linking)是将 各种代码 和 数据片段 收集并组合成一个单一文件的过程
负责链接工作的程序被称为“链接器”
链接器的出现使我们不用将一个应用组织为一个庞大的文件,而是可以分割为更小的模块
静态链接 静态链接的链接器必须完成两个任务:符号解析,重定位
符号解析:解析目标文件的符号,把 符号引用 和 符号定义 关联起来
重定位:通过把 符号定义 和 内存位置 关联起来,来重定位这些节片段,然后修改对这些符号的引用,使它们指向对应的内存位置
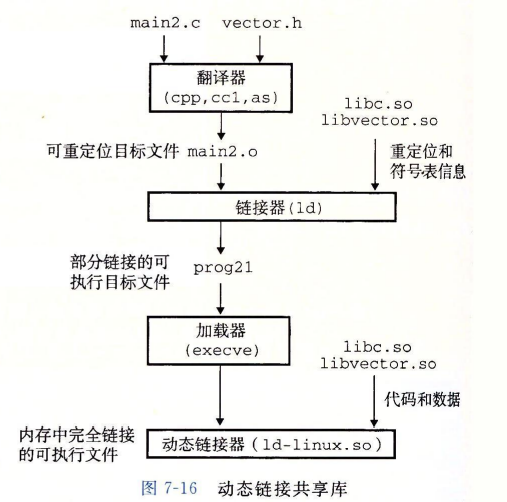
动态链接 在创建可执行文件时,静态执行一些链接
在程序加载时,动态完成链接
动态链接器通过执行下面的重定位来完成链接任务:
重定位 libc.so 的文本和数据到某个内存段
重定位 libvector.so 的文本和数据到另一个内存段
重定位 prog21 中所有的 “由 libc.so 和 libvector.so(存档文件) 定义的” 符号的引用
存档文件 存档文件(libvector.so)是一种文件格式,用于存储一组文件以及与这些文件有关的信息(元数据),创建存档文件的目的是将多个文件存储在一起,通常采用压缩格式,这样可以提高可移植性,同时节省磁盘上的存储空间
目标文件 目标文件分为3种:
1.可重定位目标文件:包含二进制代码和数据,可以在编译时与其他可重定位目标文件合并,创建一个可执行目标文件
2.可执行目标文件:包含二进制代码和数据,可以直接放入内存执行(就是可执行文件)
3.共享目标文件:一种特殊的可重定位目标文件,可以在加载或者运行时被 动态 地加载进内存并进行连接
编译器和汇编器生成:可重定位目标文件
链接器生成:可执行目标文件
各个系统目标文件的格式不同:Unix系统,采用a.out格式;Windows系统,采用PE格式;MacOS系统,采用Mach-O格式
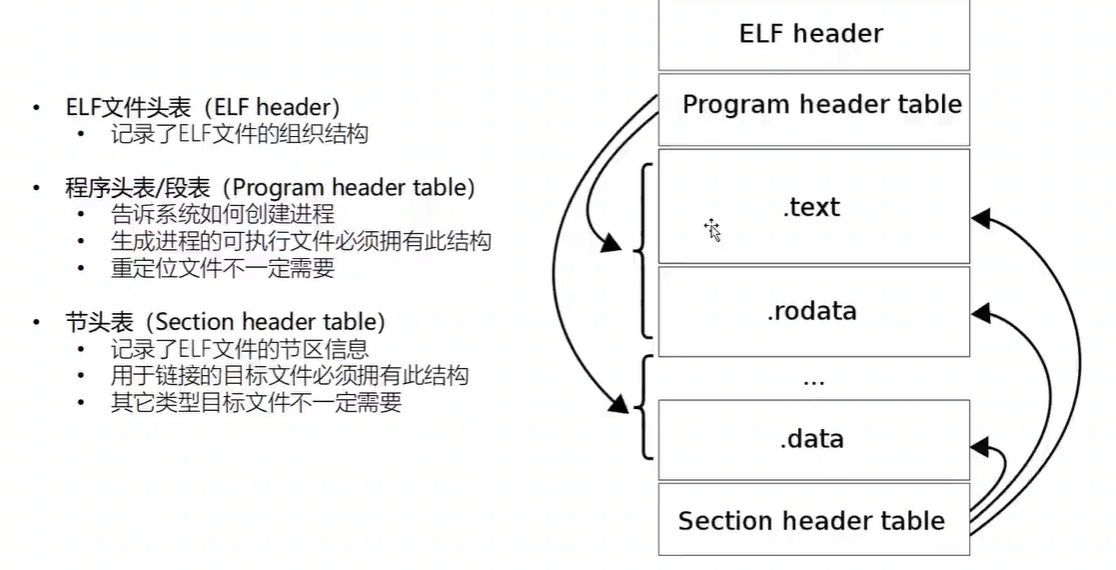
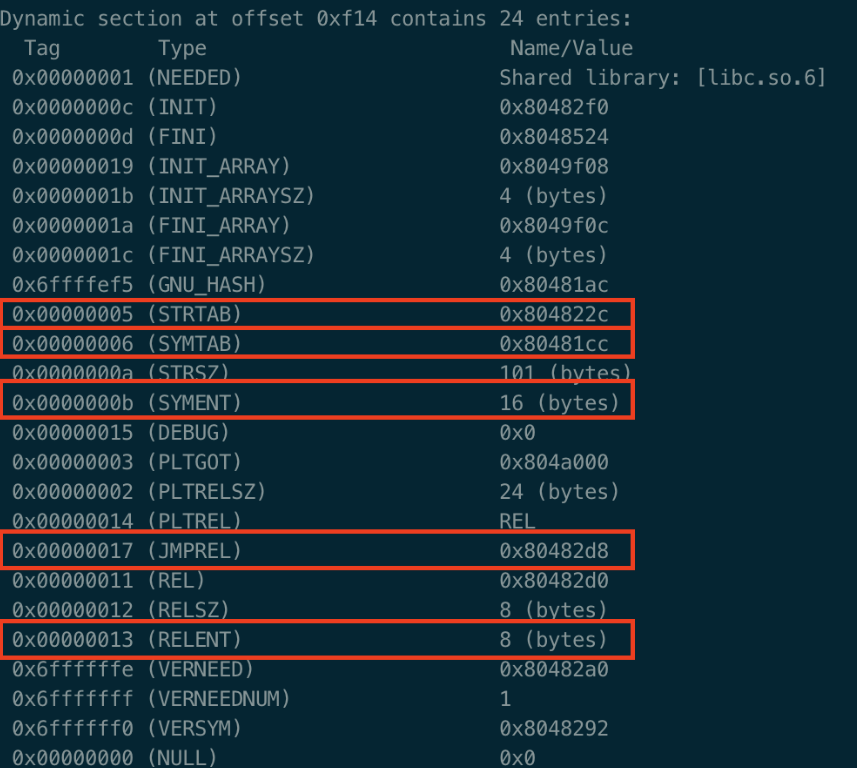
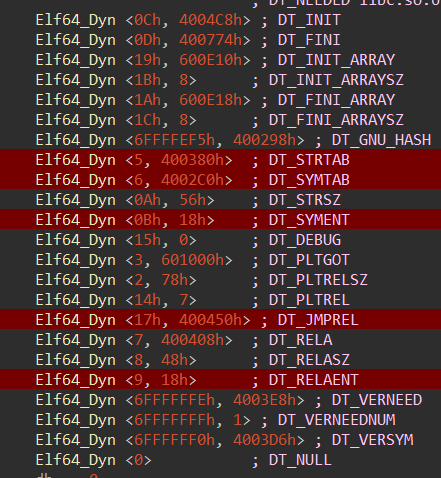
可重定位目标文件 这个就是可重定位目标文件的格式,ELF头描述了产生该文件的系统的 字的大小 和 字节序
ELF头剩下的部分包含:帮助链接器进行 语法分析 和 解释目标文件 的信息
不同节的位置大小是由 “节头部” 决定的,其中目标文件的每个节都有一个固定大小的条目(entry),夹在“ELF头”和“节头部表”之间的都是节
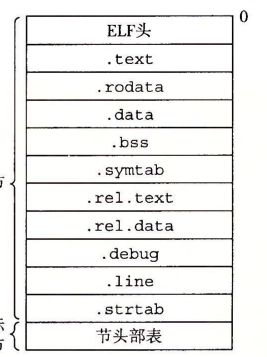
一个经典的ELF可重定位目标文件包含下面几个节:
.text:已经编译的程序机器代码
.rodata:只读数据
.data:已经初始化的 全局变量 和 静态变量(局部变量保存在栈中)
.bss:未初始化的 全局变量 和 静态变量(被初始化为“0”的变量也会保存在这里)
.symtab:符号表,用于存放程序中定义或引用的 “函数和全局变量” 的信息
.rel.text:“.text节”的重定位信息,用于重新修改代码段的指令中的地址信息
.debug:调试符号表
.line:原始C源程序中的行号 和 “.text节”中机器指令之间的映射
.strtab:字符串表(包含“.symtab”和“.debug”中的符号名和节名)
符号及其相关 符号(symbol)
函数名,变量名,数组名,结构体名都可以称之为符号
在链接器的上下文中一共有3中不同的符号:
Global symbols(模块内部定义的全局符号)
由模块m定义并能被其他模块引用的符号(非static函数,非static全局变量)
External symbols(外部定义的全局符号)
Local symbols(本模块的局部符号)
仅由模块m定义和引用的本地符号(带有static的函数和全局变量)
注意:局部变量不会在过程外被引用(分配在栈中),因此不是符号定义
符号表(symtab)
符号表是由汇编器构造的,包含一个条目的数组,每个条目都是一个结构体
1 2 3 4 5 6 7 8 9 typedef struct { Elf32_Word st_name; Elf32_Word st_value; Elf32_Word st_size; unsigned char type: 4 , binding: 4 ; unsigned char st_other; Elf32_Section st_shndx; }Elf32_Sym;
1 2 3 4 5 6 7 8 9 typedef struct { Elf64_Word st_name; unsigned char st_info; unsigned char st_other; Elf64_Addr st_value; Elf64_Xword st_size; }Elf64_Sym;
st_name:对应字符串表的偏移
st_value:距离目标符号地址的偏移
st_size:目标的大小
st_info:高字节为type,低字节为binding
type:表示符号类型(要么是数据,要么是函数)
binding:表示符号是本地的,还是全局的
符号和节
每个符号都会被分配到目标文件的某个节,由 section 字段表示,改字段也是一个到节头部表的索引 ,但是存在3个 伪节 ,它们在节头部表中是没有条目的
ABS:代表不应该被重定位的符号
UNDEF:代表未定义的符号,就是在本目标模块中被引用,但是却在其他地方定义的符号
COMMON:代表未被分配位置的未初始化数据的目录
// 只有在可重定位目标文件中才有这些伪节,可执行目标文件是没有的
COMMON和bss节的区别很细微:
符号解析
链接器从左往右按照它们在编译器驱动程序命令行上出现的顺序,来扫描可重定位目标文件和存档文件,在这次扫描中,链接器会维护:
一个 可重定位目标文件的集合E (将会被合并为可执行目标文件)
一个 未解析符号集合U (引用了但是未定义)
一个 在前面输入文件中已经定义的符号集合D (自己定义的符号也会被装入)
符号解析的工作流程如下:
在命令行上输入文件F,链接器会判断文件F是一个目标文件,还是一个存档文件
如果是目标文件,则添加到E,并且修改U和D来反应F中的 符号定义 和 引用
如果F是一个存档文件,那么链接会尝试匹配 未解析符号集合U 和 存档文件成员定义的符号 ,假设存档文件中有个成员 m,定义了一个符号来解析U中的一个引用,那么就将 m 添加到E中,并且链接器修改U和D来反映 m 中的 符号定义 和 引用
扫描完成以后,集合U非空,链接器就会输出一个错误并终止,以表明有符号未定义
扫描完成以后,集合U为空,那么链接器就会合并集合E中的目标文件,构建可执行文件
// 当D被新填入时,对应的U会减少
符号变量
自动变量(动态局部变量):auto
离开函数,值就消失
不写 static 就默认是 auto
静态局部变量:static
离开函数,值任然保留
变量的值只在函数内部生效
带有 static 的变量只会初始化一次(数据存储在 data 段)
当上一级函数多次调用本函数时,带有 static 的变量数值不变(并且不会进行初始化)
寄存器变量:register
全局变量:在 main 之外
允许 main 中所有函数访问
允许外部其他文件访问
静态全局变量:在 main 之外,static
允许 main 中所有函数访问
变量的值只在文件内部生效
节 使用目标文件的节头表,可以定位文件的所有节,节头表是 Elf32_Shdr 或 Elf64_Shdr 结构的数组
节头
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 typedef struct { elf32_Word sh_name; Elf32_Word sh_type; Elf32_Word sh_flags; Elf32_Addr sh_addr; Elf32_Off sh_offset; Elf32_Word sh_size; Elf32_Word sh_link; Elf32_Word sh_info; Elf32_Word sh_addralign; Elf32_Word sh_entsize; } Elf32_Shdr; typedef struct { Elf64_Word sh_name; Elf64_Word sh_type; Elf64_Xword sh_flags; Elf64_Addr sh_addr; Elf64_Off sh_offset; Elf64_Xword sh_size; Elf64_Word sh_link; Elf64_Word sh_info; Elf64_Xword sh_addralign; Elf64_Xword sh_entsize; } Elf64_Shdr;
节分配
节简述
ELF头:包括16字节的标识信息,文件类型(.o,exec,.so),机器类型(如Intel 80386),节头表的偏移,节头表的表项大小及表项个数
.text节:编译后的代码部分
.rodata节:只读数据,如 printf 用到的格式串,switch 跳转表等
.data节:已初始化的全局变量和静态变量
.bss节:未初始化全局变量和静态变量,仅是占位符,不占据任何磁盘空间,区分初始化和非初始化是为了空间效率
.symtab节:存放函数和全局变量(符号表)的信息,它不包括局部变量
.rel.text节:.text节的重定位信息,用于重新修改代码段的指令中的地址信息
.debug节:调试用的符号表(gcc -g)
.strtab节:包含 .symtab节和 .debug节 中的符号及节名
示例 (可能会有不同,比如:在我的电脑上 .data 为第4节)
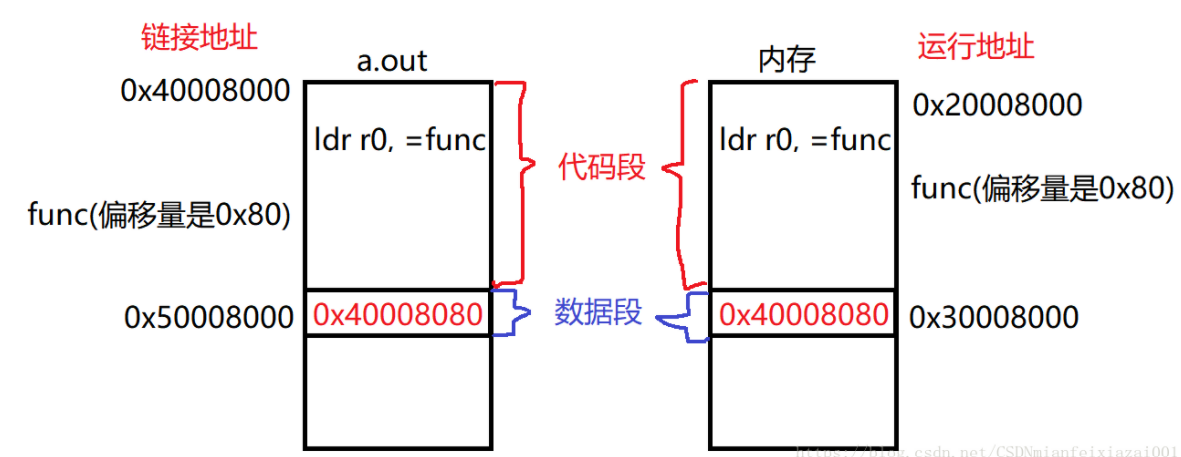
运行&链接&加载&存储地址 运行地址 ~~ 链接地址
链接地址:在程序编译的时候,每个目标文件都是由源代码编译得到,最终多个目标文件链接生成一个最终的可执行文件,而链接地址就是指示链接器,各个目标文件的在可执行程序中的位置
运行地址: 程序实际在内存中运行时候的地址
运行地址是动态的,如果你将程序加载到内存中时,改变存放在内存的地址,那么运行地址也就随之改变了
1 例如上图所示,指令ldr r0, =func就是一条位置相关指令,在编译的时候,编译器根据链接地址(链接地址入口是 0x40008000 )将其翻译成:ldr r0, [pc, #0x80 ],也就是将func标号等价于地址 0x40008080 ,然后将 0x40008080 这个地址数值放在a.out文件中链接地址 0x50008000 的位置。当程序运行时,a.out会被加载到内存中运行,如果程序运行的地址和链接的地址都是 0x40008000 ,那么程序运行时,没有任何问题,因为读取的func的地址是 0x40008080 ,实际跳转的时候,跳转到 0x40008080 中存放的也是func对应的代码。但是如果运行的地址和链接地址不一样(运行地址是 0x20008000 ),这时候,func的地址还是编译的时候计算的地址 0x40008080 ,但是实际在内存中,func的地址是 0x20008080 ,那么当你跳转执行func的时候,取出来的是 0x40008080 ,跳转的地址也是 0x40008080 ,而 0x40008080 中存放的是什么代码我们不确定,但是一定不是func的代码(func存放在 0x20008080 中)。这个就是位置相关的概念
加载地址 ~~ 存储地址
加载地址:每一个程序一开始都是存放在flash中的,而运行是在内存中,这个时候就需要从flash中将指令读取到内存中(运行地址),flash的地址就是加载地址
存储地址:指令在flash中存放的存储地址,就是存储地址
参考:链接地址、运行地址、加载地址、存储地址
重定位 但链接器完成符号解析这一步时,就会把代码中的 每个符号引用 和 一个符号定义 关联起来
此时,链接器就知道它输入目标模块的 “代码节” 和 “数据节” 的切确大小
重定位的工作流程如下:
重定位“节”和“符号定义”:链接器会把所有同类型的节合并起来,然后将“运行地址”赋值给 “新的聚合节” , “输入模块中定义的每个节” ,以及 “输入模块中定义的每个符号” ,这一步完成之后,程序中的每条指令和全局变量都有唯一的“运行地址”
重定位“节”中的“符号引用”:链接器会修改 代码节 和 数据节 中对应 每个符号的引用 ,使得它们指向 正确的运行地址 (链接器需要依赖“重定位条目relocation entry”完成此操作)
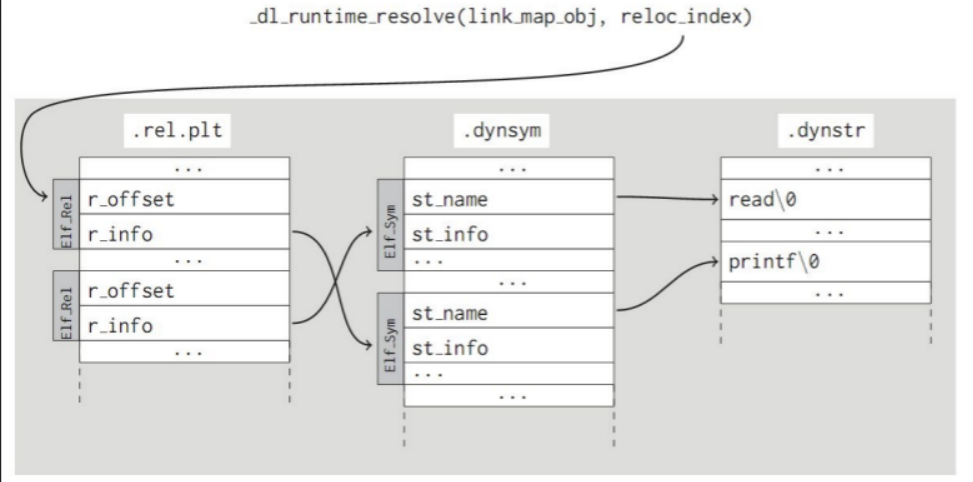
重定位条目 代码的重定位条目存放于“.rel.text”中
已初始化数据的重定位条目存放于“.rel.data”中
1 2 3 4 typedef struct { Elf32_Addr r_offset; Elf32_Word r_info; } Elf32_Rel;
1 2 3 4 5 6 typedef struct { Elf64_Addr r_offset; Elf64_Word r_info; Elf64_Word r_addend; } Elf64_Rel;
r_offset:需要 “被修改引用” 的节偏移
r_info:高字节为type,低字节为symbol
type:告知链接器如何修改新的引用
symbol:标识 “被修改引用” 应该指向的符号
r_addend:一个符号常数,一些类型的重定位要使用它进行调整
ELF文件定义了32种不同的重定位类型,其中最基本的两种为:
R_X86_64_PC32:使用32位 PC相对地址 的引用(PC相对地址:距离程序计数器(PC)的当前运行值的偏移量),类似于 “jmp xxxx” 等汇编指令,“xxxx” 加上 程序的“SP指针”得到 有效地址 ,PC值通常是下一条指令在内存中的地址
R_X86_64_32:使用32位 绝对地址 ,CPU直接获取 有效地址
文件中的代码和数据总体大小“小于2GB”,使用“R_X86_64_PC32”(小型代码模型)
文件中的代码和数据总体大小“大于2GB”,使用“R_X86_64_32”(中型代码模型,大型代码模型)
GCC默认使用“R_X86_64_PC32”
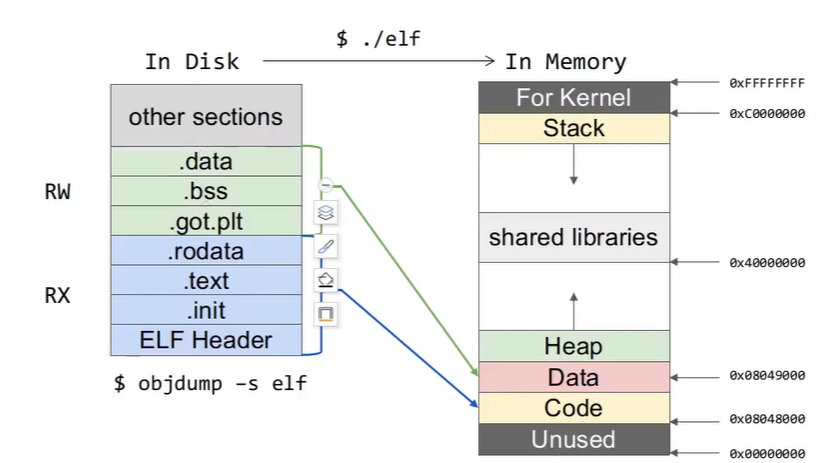
可执行目标文件 段和节
段视图:是用来描述ELF加载到进程中后,来划分“读,写,执行”权限划分的视图
节视图:是ELF存放在磁盘中时,进行不同功能区域划分的视图
在汇编源码中,通常用语法关键字section或segment来表示一段区域,它们是编译器提供的伪指令,作用是相同的,都是在程序中”逻辑地”规划一段区域,此区域便是节
注意,此时所说的section或segment都是汇编语法中的关键字,它们在语法中都表示”节”,不是段,只是不同编译器的关键字不同而已,关键字segment在语法中也被认为与section意义相同
只有ELF文件加载到内存成为进程过后,才有“段”的概念
ELF文件到虚拟内存的映射
// 左边为“节”,右边为“段”
1 2 objdump -s elf cat /proc/pid/maps
加载 当linux系统加载某个文件时,会通过调用某个驻留在存储器中的 加载器 (loader)来运行它,加载器本质上也是一段“操作系统代码”(通过execve函数来调用加载器)
加载器把目标文件的“代码”和“数据”,从磁盘复制到内存中的过程就叫做加载
位置无关代码(PIC) 无需“重定位”就可以加装的代码就是 位置无关代码 (PIC)
位置无关代码无论被加载到哪个地址上都可以正常执行
PIC的数据引用
无论我们在内存何处加装一个目标模块,它的“数据段”和“代码段”的距离总是保持不变的,因此,代码段中 任何指令 和 任何变量 之间的距离都是常量
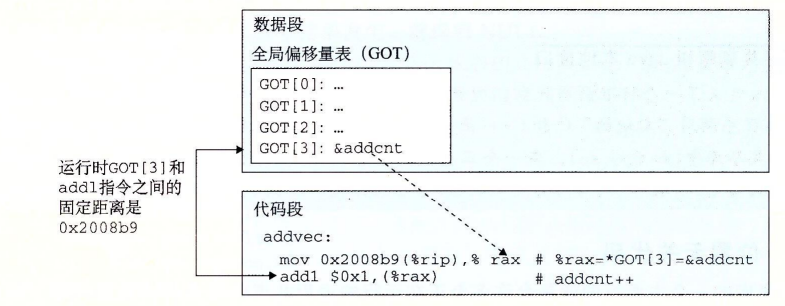
生成全局变量PIC的偏移器利用了这个事实,它在数据段开始的地方创建了一个表,叫做全局偏移量表 (GOT表),在GOT表中,每个被此模块引用的“全局数据”,“过程”,“全局变量”,都有一个8字节条目
加载时,动态链接会重定位GOT表中的每个条目,使其包含目标的绝对地址
PIC的函数调用
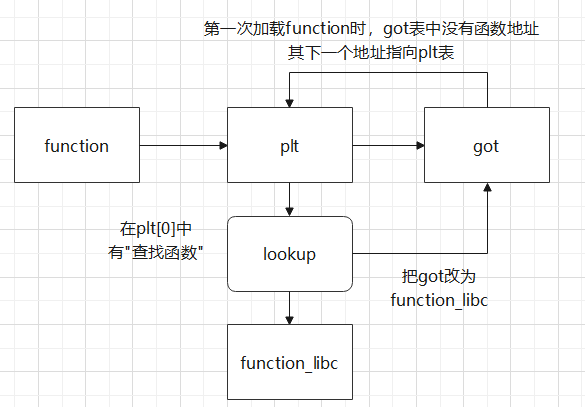
编译器没法直接获取“共享库函数”的绝对地址,所以这里采用了延迟绑定 的方式
延迟绑定技术是通过GOT表(全局偏移量表)和PLT表(过程链接表)的交互完成的
过程链接表(plt):plt是一个数组,每个条目都是16字节的代码,每一个条目负责一个具体的函数,plt[0]是一个特殊条目(它可以跳转 动态链接器 ),plt[1]调用系统启动函数“libc_start_main”,从plt[2]开始的条目依次调用“用户代码中的函数”
全局偏移量表(got):got是一个数组,每个条目都是8字节地址,got[0]和got[1]会包含 动态链接器 在解析函数地址时需要的信息,got[2]是 动态链接器 在“ld-linux.so”模块中的入口点,其余的每一个got表条目都对应一个被调用的函数,每一个条目都有一个对应的plt[n]
第1步:程序进入plt[n](对应被调用函数的plt条目),跳转got[n]
第2步:got[n]没有对应的libc地址,程序跳转回plt[n]
第3步:把偏移压栈,接着跳转plt[0]
第4步:把got[1](link_map)压栈,跳转got[2]
第5步:got[2]中存放的动态链接器 会根据“偏移”和“got[1]”查找libc库中的函数
第6步:找到对应函数后,进入函数,并且把got[n]对应位置写入libc函数的地址
库打桩机制 linux链接器允许用户截获程序对共享库函数的调用,取而代之自己的代码,这种技术被称为“库打桩”
利用“库打桩”,用户可以追踪某个函数的调用次数,验证和追踪它的输入值和输出值,或者把它替换为一个完全不同的实现
基本思想
先给定一个需要打桩的目标函数,创建一个包装函数(它的原型和目标函数一样),使用特殊的打桩机制,可以欺骗程序程序调用包装函数而不是目标函数
假设有程序:
1 2 3 4 5 6 7 8 #include <stdio.h> #include "malloc.h" int main () char *p = malloc (64 ); free (p); return 0 ; }
编译时打桩
1 2 #define malloc(size) mymalloc(size) void *mymalloc (size_t size)
1 2 3 4 5 6 7 8 9 10 11 #ifdef MYMOCK #include <stdio.h> #include <stdlib.h> void *mymalloc (size_t size) void *ptr = malloc (size); printf ("ptr is %p\n" ,ptr); return ptr; } #endif
编译时打桩:主要利用了C预处理机制
1 2 $ gcc -MYMOCK -c mymalloc.c $ gcc -I. -o test test.c mymalloc.o
参数 “- I.” 会告诉C预处理器,在搜索通常的系统目录之前,先在当前目录中查找“malloc.h”
1 2 $ ./main ptr is 0xdbd010
可以发现:“malloc.h”被“mymalloc.o”调包了
链接时打桩
1 2 #define malloc(size) mymalloc(size) void *mymalloc (size_t size)
1 2 3 4 5 6 7 8 9 10 11 12 #ifdef MYMOCK #include <stdio.h> #include <stdlib.h> void *__real_malloc(size_t size);void *__wrap_malloc(size_t size) { void *ptr = __real_malloc(size); printf ("ptr is %p\n" ,ptr); return ptr; } #endif
链接时打桩:linux静态链接器支持用 “—wrap,function”进行打桩
1 2 3 $ gcc -DMYMOCK mymalloc.c $ gcc -c main.c $ gcc -Wl,--wrap,malloc -o test test.o mymalloc.o
“-Wl option”表示把“option”传递给链接器
“—wrap,malloc”告诉静态链接器:
把“malloc”解析为“ __wrap_malloc ”
把“ __real_malloc ”解析为“真正的malloc”
1 2 $ ./main ptr is 0x95f010
可以发现:“malloc”被解析为了“ __wrap_malloc ”
运行时打桩
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #ifdef MYMOCK #define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <dlfcn.h> extern FILE *stdout ;void *malloc (size_t size) static int calltimes; calltimes++; void *(*realMalloc)(size_t size) = NULL ; char *error; realMalloc = dlsym(RTLD_NEXT,"malloc" ); if (NULL == realMalloc) { error = dlerror(); fputs (error,stdout ); return NULL ; } void *ptr = realMalloc(size); if (1 == calltimes) { printf ("ptr is %p\n" ,ptr); } calltimes = 0 ; return ptr; } #endif
运行时打桩:可以通过设置LD_PRELOAD环境变量,达到在你加载一个动态库或者解析一个符号时,先从LD_PRELOAD指定的目录下的库去寻找需要的符号,然后再去其他库中寻找
1 2 3 $ gcc -DMYMOCK -shared -fPIC -o libmymalloc.so mymalloc.c -ldl $ LD_PRELOAD="./libmymalloc.so"
1 2 $ ./main ptr is 0x95f010
可以发现:程序优先从”./libmymalloc.so”找到了“打桩malloc”
异常控制流(ECF) 程序可以使控制流发生“突变”来处理异常情况,这些“突变”就是异常控制流
应用程序可以使用“陷阱(trap)”或者“系统调用(syscall)”的ECF形式,向操作系统请求服务:向磁盘中写数据,从网络中读数据,创建一个新进程,终止当前进程
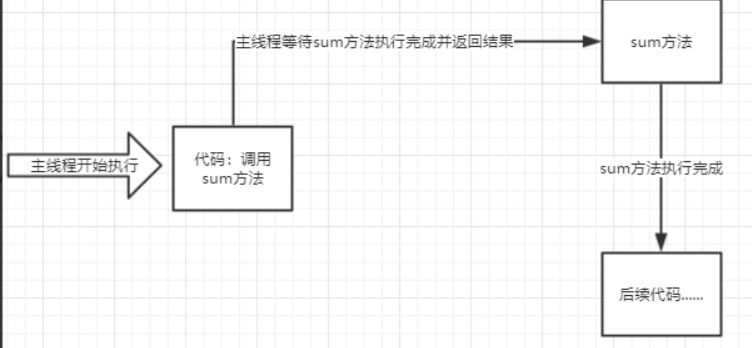
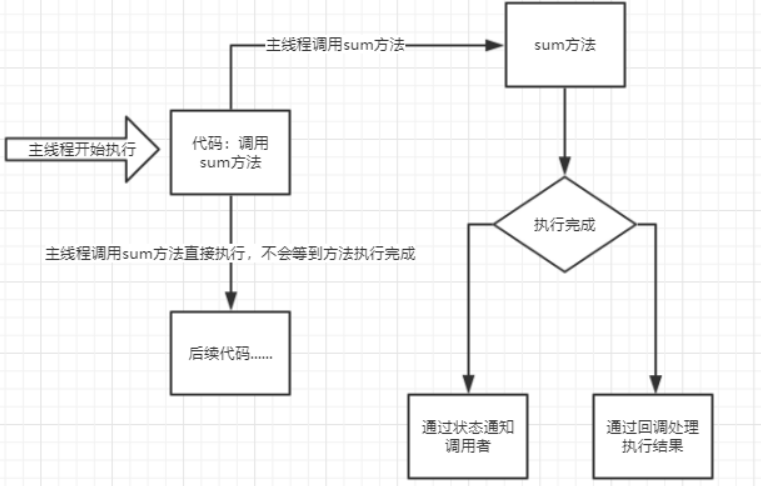
同步&异步 同步,是所有的操作都做完,才返回给用户结果,即写完数据库之后,在相应用户
异步,不用等所有操作等做完,就相应用户请求,即先相应用户请求,然后慢慢去写数据库
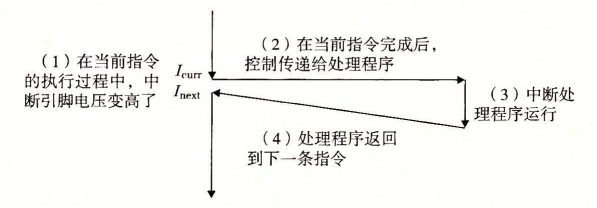
异常 异常是控制流中的一种形式,它一部分由硬件实现,一部分由操作系统实现
CPU检测到flag寄存器中的异常数据
CPU控制IP指针,通过“异常表的跳转表”跳转对应的处理程序
处理完成后,进行相对应的操作(终止进程,继续进程,输出报错信息……)
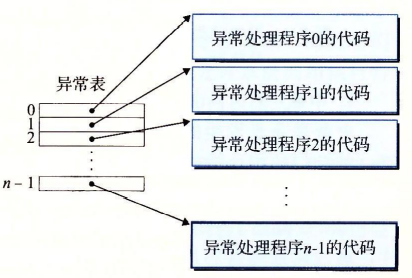
系统把每种类型的异常都分配了一个唯一非负 的异常号
异常表的基址放在一个叫异常表基址寄存器 的特殊CPU寄存器中
异常的类型
异常分为4种:中断(interrupt),陷阱(trap),故障(fault),终止(abort)
类型
原因
异步/同步
返回行为
中断
来自“I/O”设备的信号
同步&异步
总是返回到下一条指令
陷阱
有意的异常
同步
总是返回到下一条指令
故障
潜在可恢复的错误
同步
可能返回到当前指令
终止
不可恢复的错误
同步
不会返回
中断 中断程序信号处理的一种机制
中断分为 内中断 和 外中断
内中断概述
任何一个CPU都有一种能力:
可以在执行完当前指令 后检测到从CPU内部产生的一种特殊信息 ,并立刻进行处理
这种特殊信息就是中断信息
//中断信息要求CPU立马进行处理,并携带了必备的参数
内中断可以使计算机可以处理紧急情况
内中断在程序中有意地产生,所以是主动的,也是“同步” 的
内中断产生
1.除法错误(TF=0)
2.单步执行(TF=1)
3.执行”into”指令(TF=4)
4.执行”int n”指令(TF=n)
对于8086CPU,这4种情况可以产生中断信息
外中断概述
CPU除了进行运算以外,还要有对 I/O 能力(输入/输出),但是外设的输入输出 随时 可能发生,CPU必须要拥有可以 及时处理 这些信息的能力,这就引入了外中断的思想
这种中断发生完全是“异步” 的,根本无法预测到此类中断会在什么时候发生
外中断产生
外设的输入将被存放在端口中,而其输入随时可能到达
信息到达时,外设的相关芯片会给CPU发出相应的中断信息 ,当CPU执行完当前的指令后,一旦检测到该中断信息 ,就会触发外中断,行为上和内中断相似
在PC系统中,外中断源一般有以下两类:
1.可屏蔽中断:
可屏蔽中断是CPU可以不响应 的中断
其到底响不响应,主要是看IF 寄存器(“IF = 1” ——> 响应,“IF = 0” ——> 不响应)
在CPU执行某个中断时,会把IF 设置为“0”,可以暂时屏蔽其他中断
//指令sti:设置“IF=1”,指令cli:设置“IF=0”
2.不可屏蔽中断:
不可屏蔽中断是CPU必须执行的外中断,不可屏蔽中断不需要 中断类型码,立即引发响应
中断向量表
中断向量表中保存了256个中断处理程序的入口
CPU接收到中断类型码后,就会根据中断类型表找到中断处理程序的入口
中断过程
1.CPU获取中断类型码
2.flag寄存器入栈(中断过程会改变flag寄存器)
3.设置flag寄存器的TF 和IF 为“0”
4.CS 寄存器入栈
5.IP 寄存器入栈
6.从中断向量表中读取中断处理程序的入口地址
中断检查
中断信息会被存储在flag寄存器的TF 位中(TF = n:中断类型码为“n”)
CPU读取到此信息后就会开始中断过程
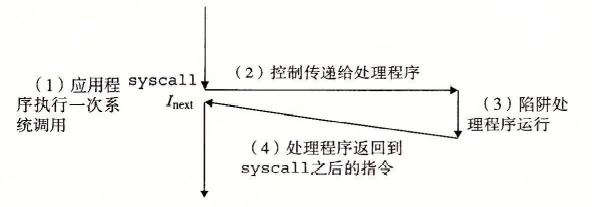
陷阱 陷阱是有意的异常,是执行一条指令的结果
陷阱最重要的用途:在“用户程序”和“内核”之间提供一个一样的接口,称为系统调用
处理器提供了一条特殊的指令:syscall,用于用户请求系统调用
有些基于读写的操作必须要在 “内核模式” 中完成,而系统调用为了实现这些功能而诞生的,它通过提供 有权限限制 的 “内核模式” ,来实现一些 “用户模式” 无法办到的操作
用户程序通过系统调用从用户态(user mode)切换到核心态( kernel mode ),从而可以访问相应的资源。这样做的好处是:
为用户空间提供了一种硬件的抽象接口,使编程更加容易
有利于系统安全
有利于每个进程度运行在虚拟系统中,接口统一有利于移植
当然,中断也可以实现系统调用(“int 80”)
故障 故障是由错误引起的,但是它可能 可以被故障处理程序修正
当发生故障时,处理器会将控制转移给故障处理程序 :如果可以修正故障,那么程序将返回并继续执行,否则,程序将返回内核中的“abort例程”并终止该程序
终止 终止是不可恢复的致命错误的结果,通常是一些硬件错误
终止处理程序将直接终止 目标程序,不会返回任何信息
内核模式 处理器通常是用某个控制寄存器中的模式位 来表示“当前进程的特权”
共两种特权:“用户模式”,“内核模式”
套接字接口 套接字接口 (socket interface)是一组函数,它们和 Unix I/O 函数结合起来,用以创建网络应用
大多数现代系统上都实现套接字接口,包括所有的 Unix 变种、Windows 和 Macintosh 系统
// 从 Linux 内核的角度来看,一个套接字就是 通信的一个端点 ,从 Linux 程序的角度来看,套接字就是一个 有相应描述符的打开文件
因特网的套接字地址存放在所示的类型为 sockaddr_in 的 16 字节结构中(IP 地址和端口号总是以网络字节顺序(大端法)存放的)
下面将介绍套接字接口中的部分函数:
1 2 3 4 int socket (int domain, int type, int protocol)
// 协议族决定了 socket 的地址类型,在通信中必须采用对应的地址
socket 函数 用于来返回一个 套接字描述符 (clientfd)
套接字描述符:用来标定系统为当前的进程划分的一块缓冲空间,类似于文件描述符
文件描述符:是内核为了高效管理已被打开的文件所创建的索引,用于指代被打开的文件,对文件所有 I/O 操作相关的系统调用都需要通过文件描述符(open的返回值fd)
1 2 3 4 int bind (int sockfd, const struct sockaddr *addr, socklen_t addrlen)
bind 函数 告诉内核将 addr 中的服务器套接字地址和套接字描述符 sockfd 联系起来
// bind函数把一个本地协议地址赋予一个套接字
1 2 3 int connect (int clientfd, const struct sockaddr *addr, socklen_t addrlen)
connect 函数 试图与 “套接字地址为 addr 的服务器” 建立一个因特网连接
如果成功,clientfd 描述符现在就准备好可以读写了(最好用 getaddrinfo 来为 connect 提供参数)
1 2 3 int listen (int sockfd, int backlog)
listen 函数 将 sockfd 从一个 主动套接字 转化为一个 监听套接字 (listening socket),该套接字可以接受来自客户端的连接请求
1 2 3 4 int accept (int listenfd, struct sockaddr *addr, int *addrlen)
accept 函数 等待来自客户端的连接请求到达侦听描述符 listenfd,然后在 addr 中填写客户端的套接字地址,并返回一个 已连接描述符
一个服务器通常通常仅仅只创建一个监听socket描述字,内核为每个由服务器进程接受的客户连接创建了一个已连接socket描述字,当服务器完成了对某个客户的服务,相应的已连接socket描述字就被关闭
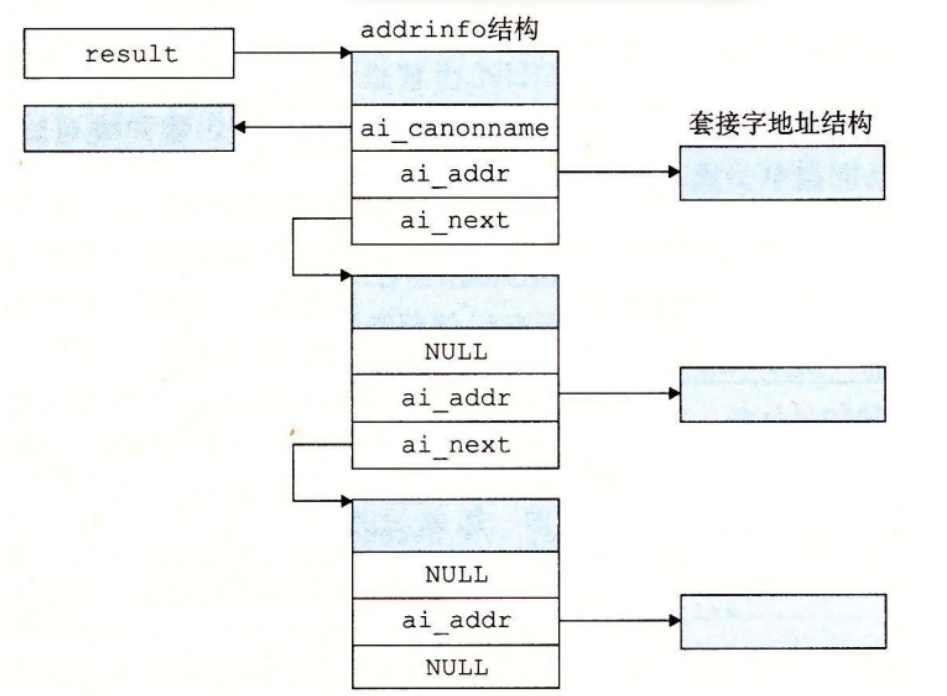
1 2 3 4 5 6 7 8 9 int getaddrinfo (const char *host, const char *service, const struct addrinfo *hints, struct addrinfo **result) void freeaddrinfo (struct addrinfo *result) const char *gai_strerror (int errcode)
getaddrinfo 函数 将主机名、主机地址、服务名和端口号的字符串表示转化成套接字地址结构,它是已弃用的 gethostbyname 和 getservbyname 函数的新的替代品
在客户端调用了 getaddrinfo 之后,会遍历这个列表,依次尝试每个套接字地址,直到调用 socket 和 connect 成功,建立起连接,类似地,服务器会尝试遍历列表中的每个套接字地址,直到调用 socket 和 bind 成功,描述符会被绑定到一个合法的套接字地址,
为了避免内存泄漏,应用程序必须在最后调用 freeaddrinfo,释放该链表
如果 getaddrinfo 返回非零的错误代码,应用程序可以调用 gai_streeror,将该代码转换成消息字符串
1 2 3 4 5 6 7 8 9 10 struct addrinfo { int ai_flags; int ai_family; int ai_socktype; int ai_protocol; char *ai_canonname; size_t ai_addrlen; struct sockaddr *ai_addr ; struct addrinfo *ai_next ; };
1 2 3 4 5 6 7 int getnameinfo (const struct sockaddr *sa, socklen_t salen, char *host, size_t hostlen, char *service, size_t servlen, int flags)
getnameinfo 函数 和 getaddrinfo 是相反的,将一个套接字地址结构转换成相应的主机和服务名字符串,它是已弃用的 gethostbyaddr 和 getservbyport 函数的新的替代品
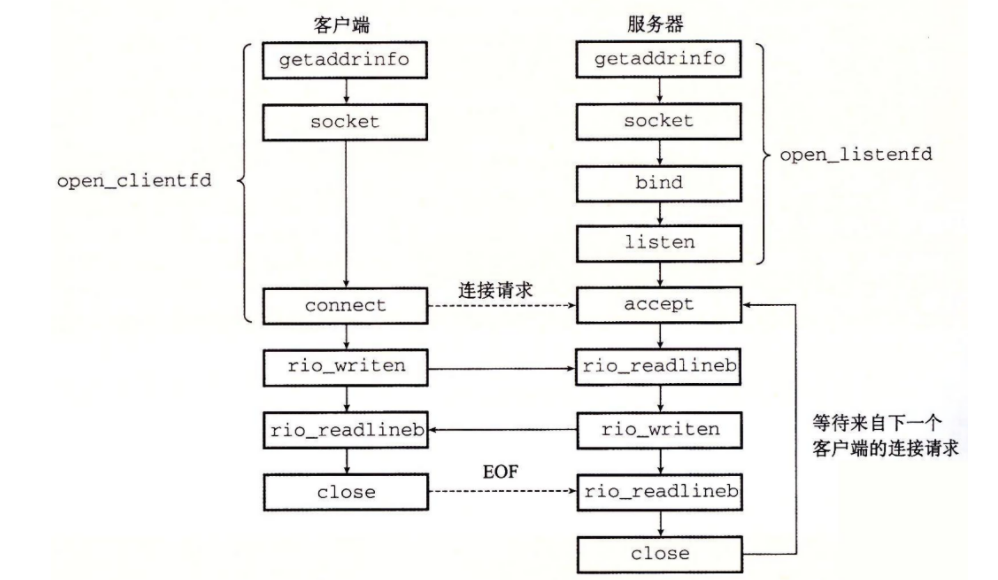
1 2 3 int open_clientfd (char *hostname, char *port)
客户端调用 open_clientfd 建立与服务器的连接
open_clientfd 函数 建立与服务器的连接,该服务器运行在主机 hostname 上,并在端口号 port 上监听连接请求
1 2 int open_listenfd (char *port)
open_listenfd 函数 打开和返回一个监听描述符,这个描述符准备好在端口 port_h 接收连接请求
网络编程中的信号 进程组
进程组就是一系列相互关联的进程集合,系统中的每一个进程也必须从属于某一个进程组,每个进程组中都会有一个唯一的 ID(process group id),简称 PGID,PGID 一般等同于进程组的创建进程的 Process ID,而这个进进程一般也会被称为进程组先导(process group leader),同一进程组中除了进程组先导外的其他进程都是其子进程
进程组的存在,方便了系统对多个相关进程执行某些统一的操作,例如:我们可以一次性发送一个信号量给同一进程组中的所有进程
会话
会话(session)是一个若干进程组的集合,同样的,系统中每一个进程组也都必须从属于某一个会话
一个会话只拥有最多一个控制终端(也可以没有),该终端为会话中所有进程组中的进程所共用
一个会话中前台进程组只会有一个,只有其中的进程才可以和控制终端进行交互,除了前台进程组外的进程组,都是后台进程组
和进程组先导类似,会话中也有会话先导(session leader)的概念,用来表示建立起到控制终端连接的进程,在拥有控制终端的会话中,session leader 也被称为控制进程(controlling process),一般来说控制进程也就是登入系统的 shell 进程(login shell)
带外数据
带外数据用于迅速告知对方本端发生的重要的事件,它比普通的数据(带内数据)拥有更高的优先级, 不论发送缓冲区中是否有排队等待发送的数据,它总是被立即发送 ,带外数据的传输可以使用一条独立的传输层连接,也可以映射到传输普通数据的连接中,
// 实际应用中,带外数据是使用很少见,有 telnet 和 ftp 等远程非活跃程序
UDP没有没有实现带外数据传输,TCP也没有真正的带外数据,不过TCP利用头部的紧急指针标志和紧急指针,为应用程序提供了一种紧急方式,含义和带外数据类似,TCP的紧急方式利用传输普通数据的连接来传输紧急数据
SIGHUP信号 (关闭进程)
SIGHUP 信号在 用户终端连接(正常或非正常)结束 时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业(任务),这时它们与控制终端不再关联
系统对SIGHUP信号的默认处理是:终止收到该信号的进程 ,所以若程序中没有捕捉该信号,当收到该信号时,进程就会退出
SIGHUP会在以下3种情况下被发送给相应的进程:
终端关闭时,该信号被发送到 session 首进程以及作为 job 提交的进程(即用 & 符号提交的进程)
session 首进程退出时,该信号被发送到该 session 中的前台进程组中的每一个进程
若父进程退出导致进程组成为孤儿进程组,且该进程组中有进程处于停止状态(收到SIGSTOP或SIGTSTP信号),该信号会被发送到该进程组中的每一个进程
例如:在我们登录Linux时,系统会分配给登录用户一个终端(Session),在这个终端运行的所有程序,包括前台进程组和后台进程组,一般都属于这个 Session,当用户退出Linux登录时,前台进程组和后台有对终端输出的进程将会收到SIGHUP信号,这个信号的默认操作为终止进程,因此前台进程组和后台有终端输出的进程就会中止
// 晦涩难懂,需要在实例中理解分析
SIGPIPE信号 (告知中断)
当 往一个写端关闭的管道或 socket 连接中连续写入数据时会引发 SIGPIPE 信号 (引发 SIGPIPE 信号的写操作将设置 errno 为EPIPE)
在TCP通信中,当通信的双方中的一方close一个连接时,若另一方接着发数据,根据TCP协议的规定,会收到一个RST(Reset the connection)响应报文,若再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不能再写入数据
即使断开还可以进行一次通信,第二次发送数据时才触发SIGPIPE
可以用相应的 handle 进行处理SIGPIPE,完成想要的操作
网络编程结构体 通用结构体:struct sockaddr,16个字节
1 2 3 4 5 struct sockaddr { uint16_t sa_family; char sa_data[14 ]; };
struct sockaddr 是一个通用地址结构,这是为了统一地址结构的表示方法,统一接口函数,使不同的地址结构可以被bind() , connect() 等函数调用
sockaddr的缺陷:sa_data 把目标地址和端口信息混在一起了
通用结构体:struct sockaddr_storage,128个字节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #if ULONG_MAX > 0xffffffff # define __ss_aligntype __uint64_t #else # define __ss_aligntype __uint32_t #endif #define _SS_SIZE 128 #define _SS_PADSIZE (_SS_SIZE - (2 * sizeof (__ss_aligntype))) struct sockaddr_storage { uint16_t ss_family; __ss_aligntype __ss_align; char __ss_padding[_SS_PADSIZE]; };
struct sockaddr_storage 被设计为同时适合 struct sockaddr_in 和 struct sockaddr_in6
为了避免试图知道要使用的IP版本,可以使用 struct sockaddr_storage,该版本可以保存其中任何一个,后将通过 connect(),bind() 等函数将其类型转换为 struct sockaddr 并以这种方式进行访问
IPv4:struct sockaddr_in,16个字节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct sockaddr_in { uint16_t sin_family; uint16_t sin_port; struct in_addr sin_addr ; unsigned char sin_zero[sizeof (struct sockaddr) - sizeof (sa_family_t ) - sizeof (in_port_t ) - sizeof (struct in_addr)]; }; typedef uint32_t in_addr_t ;struct in_addr { in_addr_t s_addr; };
该结构体解决了 sockaddr 的缺陷,把 port 和 addr 分开储存在两个变量中
IPv6:struct sockaddr_in6,28个字节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct sockaddr_in6 { uint16_t sin6_family; uint16_t sin6_port; uint32_t sin6_flowinfo; struct in6_addr sin6_addr ; uint32_t sin6_scope_id; }; struct in6_addr { union { uint8_t u6_addr8[16 ]; uint16_t u6_addr16[8 ]; uint32_t u6_addr32[4 ]; } in6_u; #define s6_addr in6_u.u6_addr8 #define s6_addr16 in6_u.u6_addr16 #define s6_addr32 in6_u.u6_addr32 };
服务器简析 每个网络应用都是基于客户端—服务器模型的,釆用这个模型,一个应用是由 一个服务器进程 和一个或者多个 客户端 进程组成
个客户端—服务器事务由以下四步组成:
当一个客户端需要服务时,它向服务器发送一个请求,发起一个事务,例如,当 Web 浏览器需要一个文件时,它就发送一个请求给 Web 服务器
服务器收到请求后,解释它,并以适当的方式操作它的资源,例如,当 Web 服务器收到浏览器发出的请求后,它就读一个磁盘文
服务器给客户端发送一个响应,并等待下一个请求,例如,Web 服务器将文件发送回客户端
客户端收到响应并处理它,例如,当 Web 浏览器收到来自服务器的一页后,就在屏幕上显示此页
服务器请求 一般的请求消息如下代码所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 GET /home.html HTTP/1.0 Accept: */* Host: localhost:GET /home.html HTTP/1.0 Accept: */* Host: localhost:GET /home.html HTTP/1.0 Accept: */* Host: localhost: User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3 Connection: close Proxy-Connection: close <html > <head > <title > test</title > </head > <body > <img align ="middle" src ="godzilla.gif" > Dave O'Hallaron </body > </html >
服务器响应 一般的响应如下代码所示:
1 2 3 4 5 6 7 8 9 10 11 12 HTTP/1.0 200 OK Server: Tiny Web Server Content-length: 120 Content-type: text/html <html > <head > <title > test</title > </head > <body > <img align ="middle" src ="godzilla.gif" > Dave O'Hallaron </body > </html >
响应消息行:第一行响应消息为响应消息行
例如:HTTP/1.0 200 OK
HTTP/1.0 为协议版本
200 为响应状态码,常用的响应状态码有40余种,这里我们仅列出几种,详细请看:
200:一切正常
302/307:临时重定向
304:未修改,客户端可以从缓存中读取数据,无需从服务器读取
404:服务器上不存在客户端所请求的资源
500:服务器内部错误
OK 为状态码描述
响应消息头:
Location:指示新的资源的位置通常和302/307一起使用,完成请求重定向
Server:指示服务器的类型
Content-Encoding:服务器发送的数据采用的编码类型
Content-Length:告诉浏览器正文的长度
Content-Language:服务发送的文本的语言
Content-Type:服务器发送的内容的MIME类型
Last-Modified:文件的最后修改时间
Refresh:指示客户端刷新频率,单位是秒
Content-Disposition:指示客户端下载文件
Set-Cookie:服务器端发送的Cookie
Expires:-1
Cache-Control:no-cache (1.1)
Pragma:no-cache (1.0) 表示告诉客户端不要使用缓存
Connection:close/Keep-Alive
Date:请求时间
响应正文:即网页的源代码(F12可查看)