我学习pwn已经有一段时间了,遇到了一个有意思的题目,再此分析一下
题目链接: 题目 (xctf.org.cn)
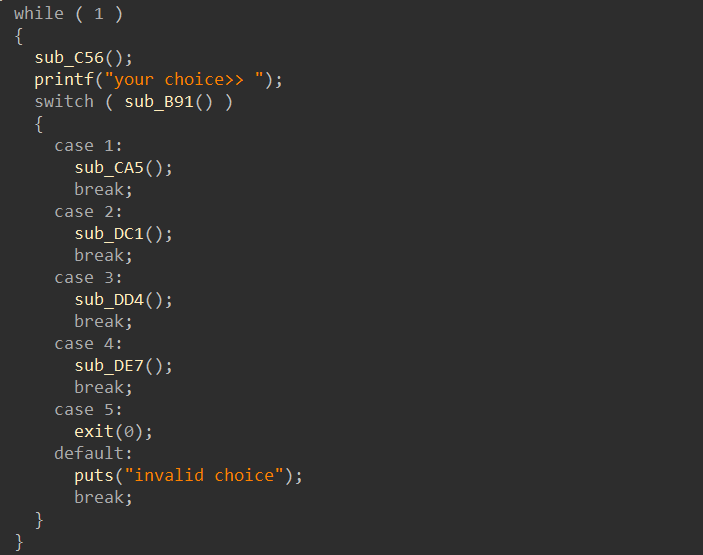
选项一可以申请一片内存空间,位置和大小都可以自己定义(空间大小不超过8字节),并且有一次写入的机会,选项四可以释放某片内存空间,本程序中没有BackDoor
当我第一次分析这个题时,而一眼就注意到了UAF漏洞,没有BackDoor,并且没有开NX,由此可以判断:本程序需要在堆中写入shellcode来获取权限
UAF(Use After Free)
如果程序利用“free”,“delete”等函数释放内存时没有置空指针,就会造成UAF漏洞
先看一段代码:
1 |
|
输出结果:
1 | a addr:6792d2a0,ywhkkx |
申请“a”后,释放“a”,然后申请相同大小的“b”
根据结果来看,“a”和“b”两个指针指向了同一片内存空间,修改“b”,“a”也发生改变
根本原因:
这里涉及到 ptmaoolc 的知识了(一种heap管理算法):
ptmalloc是glibc默认的内存管理器
在ptmalloc内部,内存块采用chunk管理,并且将大小相似的chunk用链表管理,一个链表被称为一个bin。前64个bin里,相邻的bin内的chunk大小相差8字节,称为small bin,后面的是large bin,large bin里的chunk按先大小,再最近使用的顺序排列,每次分配都找一个最小的能够使用的chunk
PS:ptmaoolc算法的行为肯定有利于CPU的运算,具体就不展开了(我也不会)
这里挂两个博客,讲的更详细:
UAF:https://blog.csdn.net/qq_31481187/article/details/73612451
ptmaoolc: ptmalloc总结 - bitError - 博客园 (cnblogs.com)
这里还有一个内存分配策略的总结:
ptmalloc,tcmalloc和jemalloc内存分配策略研究|I’m OWenT
本程序可以无限循环,也就是有多次写入的机会,但是仔细分析代码又会出现问题:

一次申请的空间大小不超过8字节,肯定装不下shellcode,所以要多次申请,并把shellcode分段装入这些堆内存空间中
构造如下shellcode:(涉及到64位系统的传参约定)
1 | mov rdi,xxxx;/bin/sh #字符串的地址 |
构造shellcode片段:
1 | codex=asm("mov rdi,'/bin/sh'") #把‘/bin/sh’装入rdi |
问题:可以发现“codex”的大小明显超过了8字节,这里先放一放
现在需要程序按照这个顺序执行shellcode,但堆与堆之间没有联系,需要用jmp连接
IP控制指令:jmp short
jmp short 目标地址,占用2字节,可以按照相对位置进行寻址跳转
机器码:EB + 8位位移
计算公式:相对偏移地址 = 目标地址 - 当前地址 - 2(为什么要“-2”,后续进行分析)
//当前地址:jmp指令的地址
要理解这个计算公式首先得搞明白CPU执行指令的过程:
1.从CS:IP指向的“内存单元”读取指令,送入指令缓存器
2.(IP)=(IP)+ 所读取指令的长度,从而指向下一条指令
3.执行指令,回到“1”,重复这个过程
案例(“《汇编语言》-王爽 ” 中的例子):


可以发现“jmp short s”和机器码为EB03,而jmp自己的地址为0003
1.CS:IP指向“0003”(EB 03)
2.指令“EB 03”被送入指令缓存器
3.(IP)=(IP)+ 2 = 0005H ,CS:IP 指向 add ax,1
4.CPU执行指令缓存器中的指令“EB 03”
5.指令执行后,(IP)= 0008H ,CS:IP 指向 inc ax
可以发现,指令“EB 03”执行以后,CS:IP立马完成了跳转,IP的变化为“0005H>>>00008H”(差3)
所以jmp中的目的地址是计算出来的:指令执行前IP的指向 + EB后的数值
//因为是先进行2然后再进行4,所以计算公式中的“-2”就是减去“jmp short s”指令的长度
那么EB后面的8位位移该写多少呢?
这里需要先有64位堆结构和内存对齐的知识
完全二叉树特点
1.叶子结点只可能在最大两层出现
2.对于任意一结点,如果其右子树的最大层次为L,则其左子树的最大层次为L+1
//子树左对齐,不管右子树的有无,左子树一定存在(叶子结点除外)
3.度为1的结点只有0或1个
简而言之,完全二叉数就是一个“顺序填充”的过程:
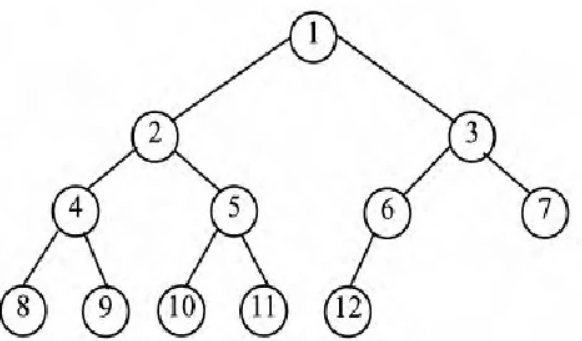
数据会从左往右依次填充,直到某一层填满然后填下一层
64位堆结构
堆总是一棵完全二叉树
linux的堆内存管理分为三个层次,分别为分配区area、堆heap和内存块chunk
每次glibc分配的内存块称为chunk(函数“malloc”分配的内存)
内存块 chunk :
1 | struct malloc_chunk { |
- prev_size:相邻的前一个堆块大小。这个字段只有在前一个堆块(且该堆块为
normal chunk)处于释放状态时才有意义。这个字段最重要(甚至是唯一)的作用就是用于堆块释放时快速和相邻的前一个空闲堆块融合。该字段不计入当前堆块的大小计算。在前一个堆块不处于空闲状态时,数据为前一个堆块中用户写入的数据。libc这么做的原因主要是可以节约4个字节的内存空间,但为了这点空间效率导致了很多安全问题 - size:本堆块的长度。长度计算方式:size字段长度+用户申请的长度+对齐。libc以 size_T 长度 * 2 为粒度对齐。例如 32bit 以 4 2= 8byte 对齐,64bit 以 **8 2=0×10 对齐。因为最少以8字节对齐,所以size一定是8的倍数,故size字段的最后三位恒为0,libc用这三个bit做标志flag。比较关键的是最后一个bit(pre_inuse),用于指示相邻的前一个堆块是alloc还是free。如果正在使用,则 bit=1。libc判断 当前堆块是否处于free状态的方法 就是 判断下一个堆块的 pre_inuse** 是否为 1 。这里也是
double free和null byte offset等漏洞利用的关键 - fd&bk:双向指针,用于组成一个双向空闲链表。故这两个字段只有在堆块free后才有意义。堆块在alloc状态时,这两个字段内容是用户填充的数据。两个字段可以造成内存泄漏(libc的bss地址),Dw shoot等效果
- 值得一提的是,堆块根据大小,libc使用fastbin、chunk等逻辑上的结构代表,但其存储结构上都是malloc_chunk结构,只是各个字段略有区别,如fastbin相对于chunk,不使用bk这个指针,因为fastbin freelist是个单向链表
内存对齐
内存对齐和地址对齐一样,也是一种时空权衡
glibc的堆内存对齐机制:
32位:
最少分配16字节堆,8字节对齐,每次增加8
其中4字节为头部,申请1-12堆,分配16字节堆
64位:
最少分配32字节堆,16字节对齐,每次增加16
其中8字节为头部,申请1-24堆,分配32字节堆
//16个字节头部,包括为数据区的 prev_size
可以参考一下链接:
堆利用: pwn with glibc heap(堆利用手册) - hac425 - 博客园 (cnblogs.com)
64位程序一次性分配的最小堆字节为32

而静态数组“2020A0[v1]”的类型为“qword”(4字,32字节),刚好等于申请堆空间的最小值
所以只要“v1”是连续的,那么申请出来的堆空间就是连续的

在内存块的结构中:fd&bk作为数据区,shellcode和jmp都要写在这里
执行jmp后程序需要跳转到下一个fd&bk(数据区)
计算:EB 8位位移 = 2 + 1 + 8 + 8 + 8 - 2 = 25(0x19)
根据程序输入函数的算法,最后1字节的数据会被强行改为“0”,所以后面8字节的空数据不能使用
所以真正可以利用的空间就只有7字节,除去2字节的jmp,就只剩下5字节了
1 | codex=(asm("mov rdi,'/bin/sh'"+'\x90\x90\xeb\x19')#明显超范围了 |
//这里在“jmp short”处选择右对齐,是为了防止“\x90\x90”干扰8位位移的计算
分析到这里就只剩下两个问题了:
1.codex超过了7字节,会导致execve的第一个参数无效(“/bin/sh”)
2.shellcode没有办法执行
堆不像栈,没有类似于“ret”这样的IP控制指令,想要执行堆中的shellcode片段,必须要CS:IP指针访问这一片堆空间才行,本程序中的shellcode片段已经用jmp进行了连接,所以只要CS:IP指针访问了codex,就等同于执行了shellcode
那么有没有一个办法可以一次性解决这两个问题呢?
仔细分析程序的代码,还可以发现一个漏洞:
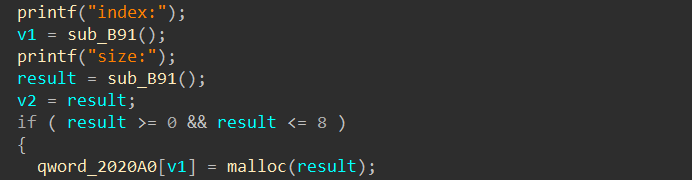
“index”由用户输入并且没有检查其范围,之后就直接作为了静态数组“2020A0”的下标
这就构成了数组越位漏洞

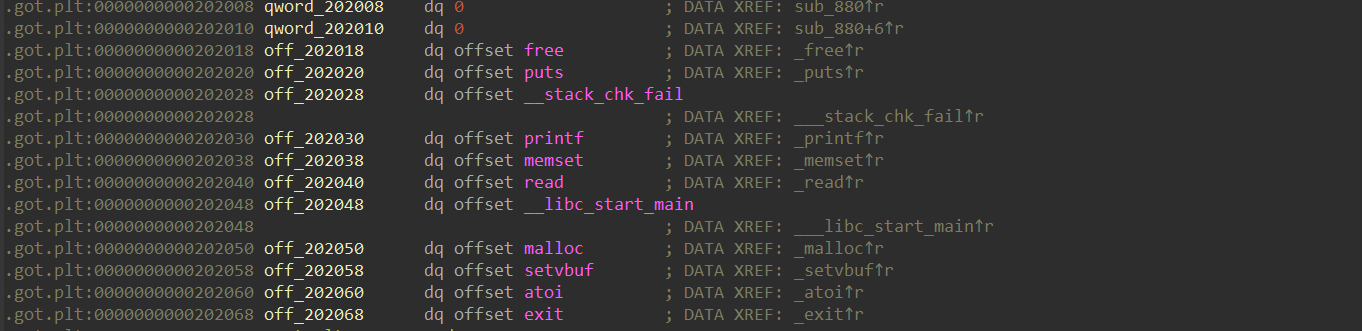
静态数组“2020A0”的上方就是GOT表地址,这里的任何一个函数都可以被数组越位覆盖

而且在plt表中已经控制了CS:IP,所以再此之后覆盖的堆内存会被当做指令
这里选择“atoi”是最正确的:


分析代码就可以知道,“atoi”的参数是“read”读取来的,此处读入“/bin/sh”就可以代替codex了

偏移计算为:(0x2020A0 - 0x202060)/ 8 = [-8]
因为改变“atoi”会导致循环中断,所以 [-8] 的堆空间只能在最后申请,但它又必须第一个执行
这里就需要利用UAF使 [0](第一次申请的空间)和 [-8] 指向同一片内存(“atoi”的GOT表)
具体exp如下:
1 | from pwn import* |