master-of-orw
1 | master-of-orw: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=9ca858a89af65e342074ea6e69e1f20ddba93d11, for GNU/Linux 3.2.0, stripped |
- 64位,dynamically,Full RELRO,NX,PIE
1 | 0000: 0x20 0x00 0x00 0x00000004 A = arch |
漏洞分析
执行 shellcode,但是有沙盒:
1 | code = mmap(0LL, 0x1000uLL, 7, 33, -1, 0LL); |
入侵思路
在 openat 和 open 都被 ban 了的情况下,只能使用 io_uring 来进行 ORW
io_uring(Unified Resource Gestion)是一种 Linux 内核中的新特性,它提供了一种高性能、低延迟的 I/O 调度机制
基于共享内存,io_uring 维护了两个与内核共享的队列:
- submit 队列:用于存储待提交的 I/O 请求
- completion 队列:用于存储 I/O 请求的完成状态
submit 队列中的 I/O 请求与 completion 队列中的 I/O 完成事件之间也没有固定的对应关系,内核会根据 I/O 请求的类型、文件描述符、线程池等信息自动将 I/O 请求分配到合适的队列中
- 由于 submit / completion 队列属于用户态程序与内核的共享空间
- 内核只需要读取 submit 队列中的参数就可以执行相应的内核态函数,不需要执行系统调用
- 当数据执行完毕时,内核又会将返回数据写入 completion 队列
先给出一个 io_uring ORW 的案例:
1 | // gcc -o io_uring io_uring.c -static -luring -fno-stack-protector -no-pie -g |
我们可以进行单步调试,观察并记录上述代码的执行流程
io_uring_queue_init:核心初始化
1 | io_uring_queue_init(1u, &ring, 0); /* 一次sys_unk_425,两次sys_mmap */ |
- sys_unk_425:初始化 io_uring 的系统调用
1 | ► 0x402aca <__io_uring_queue_init_params+90> syscall <SYS_<unk_425>> |
- sys_mmap:创建 submit 队列
1 | ► 0x401235 <io_uring_queue_mmap+149> syscall <SYS_mmap> |
- sys_mmap:创建 completion 队列
1 | ► 0x4012c9 <io_uring_queue_mmap+297> syscall <SYS_mmap> |
io_uring_get_sqe:获取 io_uring_sqe 结构体的指针(该结构体用于描述一个 submit 条目)
1 | sqe = io_uring_get_sqe(&ring); |
io_uring_prep_openat / io_uring_prep_read / io_uring_prep_write:注册 open / read / write
1 | io_uring_prep_openat(sqe, -100, "./flag", 0, 0); |
- 将信息填写入 submit / completion 队列,核心函数为 io_uring_prep_rw
1 | ► 0x402473 <io_uring_prep_rw+35> mov byte ptr [rax], dl |
io_uring_submit:向内核提交注册信息
1 | ret = io_uring_submit(&ring); |
- sys_unk_426:提交注册信息的系统调用
1 | ► 0x40466b <io_uring_submit+123> syscall <SYS_<unk_426>> |
io_uring_wait_cqe:获取 io_uring_cqe 结构体的指针(该结构体用于描述一个 completion 条目)
1 | ret = io_uring_wait_cqe(&ring, &cqe); |
接下来就可以 IDA 分析二进制文件,提取出有效的汇编指令片段:
- shellcode 各个函数的汇编代码尽量和二进制文件一致
- 对于 io_uring_queue_init / io_uring_submit 函数需要保证系统调用的参数一致
- 对于 io_uring_prep_rw 则需要保证填写的数据一致
- 对于 io_uring_get_sqe / io_uring_wait_cqe 只需要提取基本的汇编代码即可
- 函数 io_uring_prep_read 可以被 mmap 替代
完整 exp 如下:
1 | # -*- coding:utf-8 -*- |
blind
本题目没有二进制文件
漏洞分析
本题目实现了一个简单的交互系统:
1 | [a]aaaaa |
- A/D:左移/右移
[],用以选中不同的对象 - W/S:使目标对象的 asicc 值
+1/-1 - 空格:大写字母/小写字母的切换
- 回车:执行程序
程序在 aaaaaa 字符后有一个指针,指向了 aaaaaa 字符的地址,后续的 printf 将会使用该地址来打印数据
程序没有限制 A/D 的范围,导致我们可以将 [] 移动到 aaaaaa 后的地址上,然后使用 W/S 来修改该地址,从而使后续的 printf 输出错误的数据
入侵思路
在比赛时测试的内存结构如下:
1 | aaaaaaaa pointer heap_addr libc_addr stack_addr |
- 经过测试,这个 libc_addr 就是返回地址
泄露的 libc_base 如下:
1 | [+] leak_addr >> 0x7f4a645e2d0a |
查找到的 libc 版本如下:
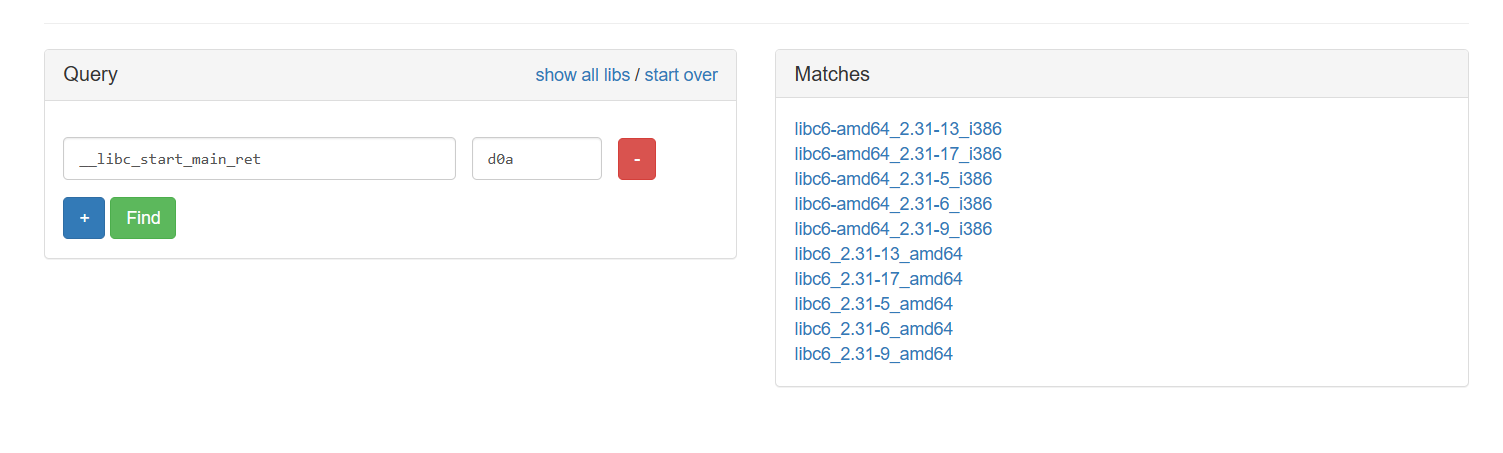
泄露 libc_base 后,我们就可以继续移动 [] 到后续的返回地址处,使用 W/S 来修改返回地址为 ROP 链
最后有一个十分恶心的问题,题目远程 /bin/sh 的偏移和本地 libc 的不同,这里只能尝试将 RDI 设置为某个明显的字符串,然后通过这个字符串的位置来逐步计算 /bin/sh 的偏移
- 比赛时没有找到
/bin/sh,而是找到一个末尾是sh的字符串 - 然后计算
sh的偏移执行system("sh")拿到 shell
完整 exp 如下:
1 | # -*- coding:utf-8 -*- |
qemu playground - 2
第一次打 qemu 逃逸类的题目,先查看 qemu 版本并恢复符号:
1 | QEMU emulator version 8.1.50 (v8.1.0-1639-g63011373ad-dirty) |
下载后使用如下命令进行编译:
1 | ./configure |
利用 bindiff 和有符号的 qemu-system-x86_64 来恢复题目文件的符号
漏洞分析
qemu 逃逸一般在如下4个函数中出现 BUG:
- pmio_read:读设备寄存器的物理地址(使用
in()触发) - pmio_write:写设备寄存器的物理地址(使用
out()触发) - mmio_read:读设备寄存器的虚拟地址(使用 mmap 映射物理内存,读这片区域时触发)
- mmio_write:写设备寄存器的虚拟地址(使用 mmap 映射物理内存,写这片区域时触发)
MMIO:通过 kernel 提供的 sysfs,我们可以直接映射出设备对应的内存,具体方法是打开类似 /sys/devices/pci0000:00/0000:00:04.0/resource0 的文件
1 | int mmio_fd = open("/sys/devices/pci0000:00/0000:00:04.0/resource0", O_RDWR | O_SYNC); |
- 读写 mmio 内存区域就会触发 mmio_read / mmio_write
PMIO:使用特殊的 CPU 指令 in/out 执行 I/O 操作,这些指令可以读/写 1,2,4 个字节(outb, outw, outl),通过 iopl 和 ioperm 这两个系统调用对 port 的权能进行设置
1 | iopl(3); |
- 使用 in/out 指令就会触发 pmio_read / pmio_write
程序限制的边界为 addr <= 0x40,可以覆盖堆指针后4字节:
1 | void __fastcall actf_mmio_write(Node *opaque, unsigned __int64 addr, int val, int size) |
程序有 rwx 段:(不知道是题目设置的还是 qemu 自带的)
1 | 0x7f9bee400000 0x7f9bee401000 ---p 1000 0 [anon_7f9bee400] |
qemu 的调试需要先使用如下命令关闭保护:
1 | sudo sysctl kernel.yama.ptrace_scope=0 |
然后使用 gdb attach pid 进行调试
入侵思路
为了使 opaquet->field_A31 = 1 成立,我们需要先进行逆向:
1 | do |
加密的正向逻辑就是:
1 | def code1(index): |
我们可以直接用 z3 求解:
1 | from z3 import * |
得到解密密钥:
1 | int data[0x10] = {1179927361, 860382075, 828328803, 1232559982, 1113548855, 1601790528, 1752183107, 1415541299, 1601447013, 1365208625, 1599425843, 2033478768, 1968124775, 828335182, 1095065380, 2099345747}; |
之后我尝试在 rwx 段上打断点,发现可以断上:
1 | ► 0x7f9bee4ce000 push rbp |
然后利用堆上遗留的数据就可以很轻松地泄露 heap_base,由于 qemu heap 的偏移有随机化,只能扫描整个内存来尝试查找 rwx 段:
1 | pwndbg> telescope 0x7f9bee4ce000 |
泄露的脚本如下:
1 | for (int i = 0; i < 0x200000; i++) |
最后还要解决一个问题,rwx 段的执行频率很高(差不多每写一次都要执行一次),因此我们先在程序的正常代码后写入 shellcode
写好以后一次性覆盖程序的 ret 为 nop 从而执行 shellcode,下面是生成 shellcode 的代码:
1 | from pwn import * |
- 由于
execve("/bin/sh")没有交互,我这里只能写 ORW
完整 exp 如下:
1 |
|