x86-32
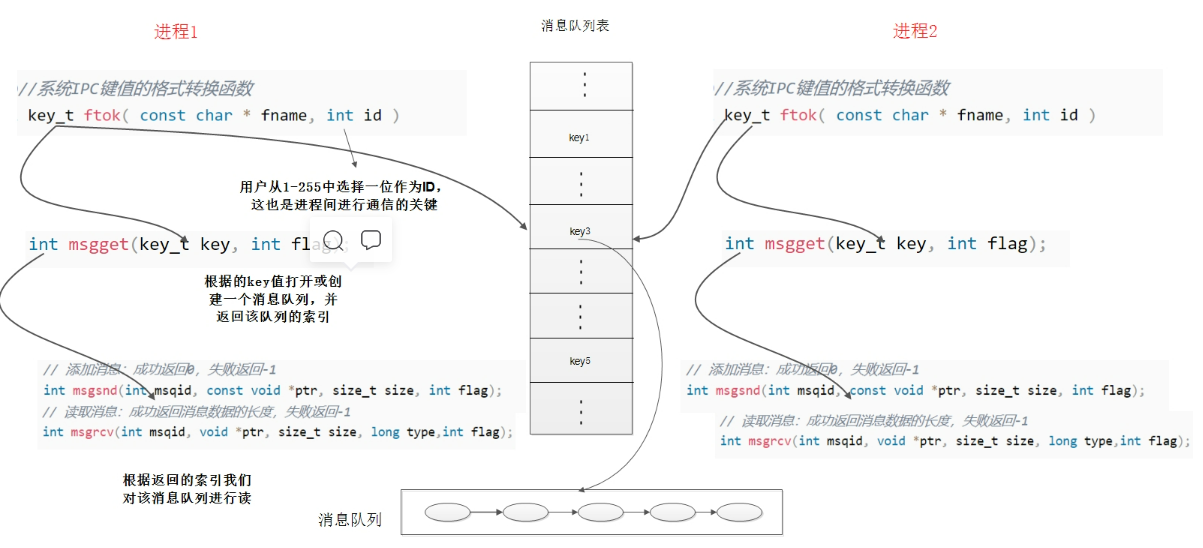
在32位时代,x86 的 operating mode 有3种:
- 实模式(Real Mode)
- 保护模式(Protected Mode)
- 虚拟8086模式(Virtual 8086 Mode)
实模式(Real Mode)
8086的CPU是16位的,为其可以索引更大的内存地址空间,内核采用了分段机制(shift-and-add segmentation)
- 即一个逻辑地址由 segment 加上 offset 组成
基于分段机制(shift-and-add segmentation)的寻址过程:
- 获取对应的段寄存器
- 通过公式
linear address = segment << 4 + offset 计算逻辑地址
保护模式(Protected Mode)
80286 的CPU是32位的(寻址范围为4G),它也使用分段机制(table-based segmentation)
- 但它的段寄存器 segment register 存的不再是 segment 的起始地址,而是一个段选择子 segment selector
- 通过这个 segment selector 查找全局标识符表GDT表获得段描述符 segment descriptor
- segment descriptor 存的才是 segment 的起始地址
段寄存器 segment register 中存放的就是16位的数据结构-段选择子
段选择子 segment selector 的结构如下:

- Index:CPU 将索引号乘8再加上GDT或者LDT的基地址,就可以找到目标段描述符
- TL:其值为“0”查找 GDT 表,其值为“1”查找 LDT 表
- RPL:请求特权级别(可以用于判断当前代码是否处于内核态)
在保护模式下,对一个段的描述则包括3方面因素:[Base Address, Limit, Access],它们加在一起被放在一个64-bit长的数据结构中,被称为段描述符
段描述符 segment descriptor 的结构如下:
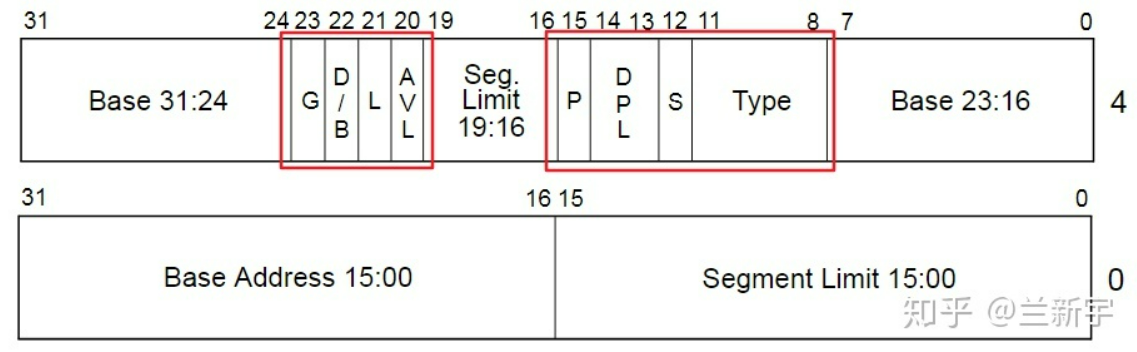
- G - Granularity 粒度(byte 或者 page),因为段的最大长度 limit 占20位
- 如果粒度为 byte,则该 segment 的寻址范围是 1MB
- 如果粒度为 page-4KB,则该 segment 的寻址范围是 4GB
- 一个 segment 的 size 是由 limit 和G位共同确定的
- D/B - Default Size/Bound
- 为“1”表示在32位模式下运行
- 为“0”在16位模式下运行
- L - 仅在64位系统中有效
- 为“1”表示在64位长模式下运行(64-Bit Mode)
- 为“0”表示在64位兼容模式下运行(Compatibility Mode)
- AVL - Available for software,留给软件用的,但在 linux 里是被忽略的
- P - Present,用于指明表项对地址转换是否有效
- P = 1:表示有效
- P = 0:表示无效
- 在页转换过程中,如果说涉及的页目录或页表的表项无效,则会导致一个异常
- DPL - Descriptor Privledge Level,表示可以访问 segment 的最低级别
- x86处理器的特权级别从
ring 0 到 ring 3,数字越小,级别越高
- 通常用户空间运行于
ring3,内核空间运行于 ring0
- 假设 DPL 为“1”,则只有当前特权级别为“0”或者“1”时,才可以访问该 decriptor 指向的 segment
- Type - 目标段拥有的权限
- 对于 task segment 是没有意义的
- 对于 code segment 和 data segment 主要是关于 Writable,Executable 的属性
- Base Address - 基地址
基于分段机制(table-based segmentation)的寻址过程:
- 内核提供了一个寄存器GDTR用来存放GDT的入口地址
- 通过段选择子 segment selector 找到对应 GDT 条目-段描述符 segment descriptor
- 通过段描述符 segment descriptor 找到基地址
GDT&LDT 的使用条件:
- GDT 能完成被多个任务共享的内存区
- LDT 通常情况下是与任务的数量保持对等(LDT放在GDT中)
虚拟8086模式(Virtual 8086 Mode)
利用一种硬件虚拟化技术,在i386的芯片上模拟出多个8086芯片
当处理器进入保护模式后,基于实模式的应用就不能直接运行了,采用虚拟8086模式,则可以让这些实模式的应用运行在基于保护模式的操作系统上,因此这种模式也被称为 Virtual Real Mode
x86-64
进入64位的x64处理器时代后(64位CPU的寻址已经不会受到限制,可以不使用分段机制),产生了一种新的运行模式,叫 Long Mode,传统的三种模式则被统称为传统模式(Legacy Mode)
Long Mode 又分为2种子模式:
- 64位长模式(64-Bit Mode):应用程序必须也得是64位的
- 64位兼容模式(Compatibility Mode):32位应用程序也可以运行
置位 EFER 寄存器的 LME 位可以开启 Long Mode
- 由于 Long Mode 要求 paging 必须开启,所以在进入 Long Mode 之前,还需要置位CR0寄存器的PG位
- 置位 code segment 的L位可在 64-Bit Mode 和 Compatibility Mode 之间切换
四级分页机制
如果不开启分页机制,那么线性地址就等同于物理地址,这要求物理地址必须是连续的
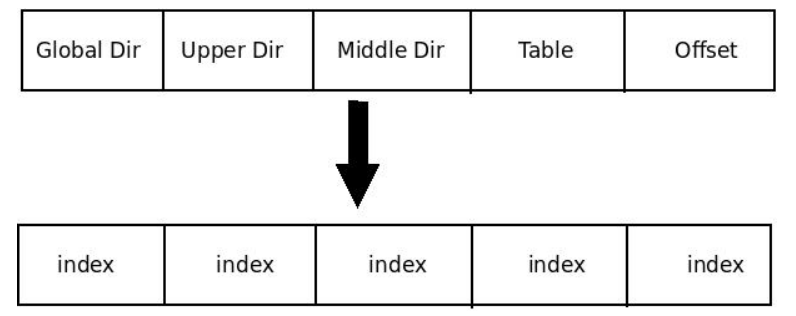
前面我们提到 Linux 内核仅使用了较少的分段机制,但是却对分页机制的依赖性很强,其使用一种适合32位和64位结构的通用分页模型,该模型使用四级分页机制:
- 页全局目录(Page Global Directory)
- 页上级目录(Page Upper Directory)
- 页中间目录(Page Middle Directory)
- 页表(Page Table)
因此线性地址因此被分成五个部分,通过各个部分索引到对应的表,而每一部分的大小与具体的计算机体系结构有关
相关结构类型:
- Linux 分别采用
pgd_t pmd_t pud_t pte_t 四种数据结构来表示页全局目录项、页上级目录项、页中间目录项和页表项(这四种数据结构本质上都是无符号长整型 unsigned long)
PAGE - 页表 (Page Table):
| 字段 |
描述 |
| PAGE_SHIFT |
指定Offset字段的位数 |
| PAGE_SIZE |
页的大小 |
| PAGE_MASK |
用以屏蔽Offset字段的所有位 |
PMD - 页目录 (Page Middle Directory):
| 字段 |
描述 |
| PMD_SHIFT |
指定线性地址的Offset和Table字段的总位数,换句话说,是页中间目录项可以映射的区域大小的对数 |
| PMD_SIZE |
用于计算由页中间目录的一个单独表项所映射的区域大小,也就是一个页表的大小 |
| PMD_MASK |
用于屏蔽Offset字段与Table字段的所有位 |
PUD_SHIFT - 页上级目录 (Page Upper Directory):
| 字段 |
描述 |
| PUD_SHIFT |
确定页上级目录项能映射的区域大小的位数 |
| PUD_SIZE |
用于计算页全局目录中的一个单独表项所能映射的区域大小 |
| PUD_MASK |
用于屏蔽Offset字段,Table字段,Middle Air字段和Upper Air字段的所有位 |
PGDIR_SHIFT - 页全局目录 (Page Global Directory):
| 字段 |
描述 |
| PGDIR_SHIFT |
确定页全局页目录项能映射的区域大小的位数 |
| PGDIR_SIZE |
用于计算页全局目录中一个单独表项所能映射区域的大小 |
| PGDIR_MASK |
用于屏蔽Offset, Table,Middle Air及Upper Air的所有位 |
基于分页机制(paging)的寻址过程:
- 从CR3寄存器中读取页目录所在物理页面的基址(即所谓的页目录基址),从线性地址的第一部分获取页目录项的索引,两者相加得到页目录项的物理地址
- 第一次读取内存得到 pgd_t 结构的目录项,从中取出物理页基址取出(具体位数与平台相关,如果是32系统,则为20位),即页上级页目录的物理基地址
- 从线性地址的第二部分中取出页上级目录项的索引,与页上级目录基地址相加得到页上级目录项的物理地址
- 第二次读取内存得到 pud_t 结构的目录项,从中取出页中间目录的物理基地址
- 从线性地址的第三部分中取出页中间目录项的索引,与页中间目录基址相加得到页中间目录项的物理地址
- 第三次读取内存得到 pmd_t 结构的目录项,从中取出页表的物理基地址
- 从线性地址的第四部分中取出页表项的索引,与页表基址相加得到页表项的物理地址
- 第四次读取内存得到 pte_t 结构的目录项,从中取出物理页的基地址
- 从线性地址的第五部分中取出物理页内偏移量,与物理页基址相加得到最终的物理地址
- 第五次读取内存得到最终要访问的数据
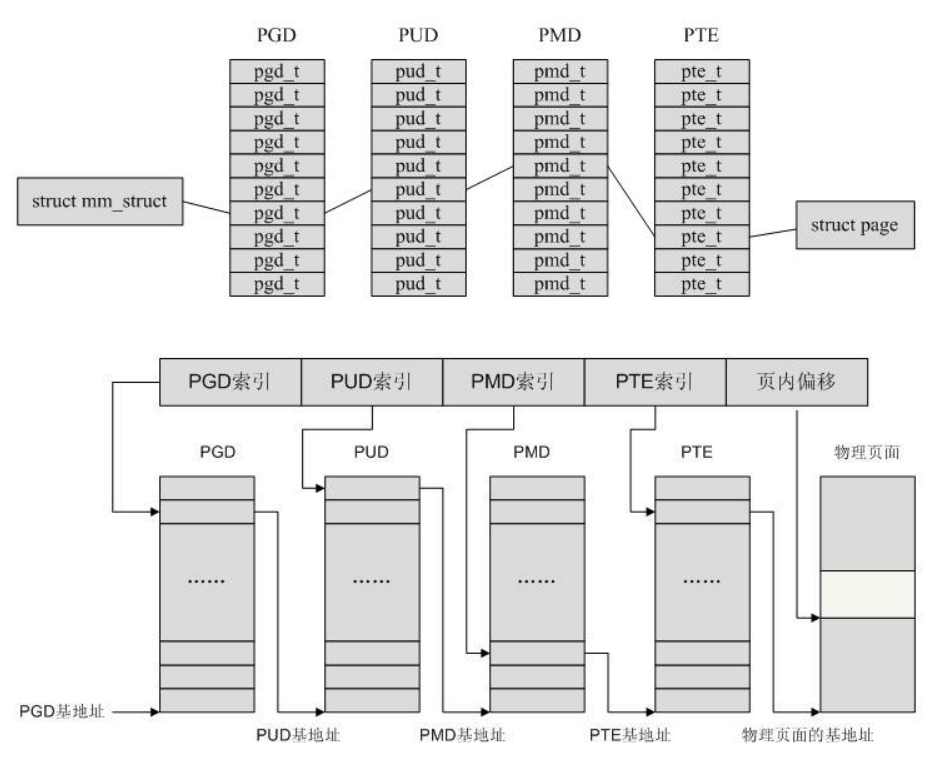
- 程序的线性地址将作为各级页表索引
- 因此内核会给用户程序提供一个抽象:虚拟地址
- 虚拟地址到线性地址的转换则依靠分段机制
其他差异
在 Legay Mode 中,用户空间可通过 SYSENTER 指令进入内核空间,内核空间则通过 SYSEXIT 指令返回用户空间,在此过程中,由于发生了 segment 切换,所以需要进行 segmentation 的各种检测,比较影响效率
在 Long Mode 中,伴随着 segmentation 的弱化和 flat momery model(平坦内存模型)的使用,SYSENTER/SYSEXIT 这2个指令不再被支持,取而代之的不需要 segmentation 检测的 SYSCALL 和 SYSRET 指令
此外,Legacy Mode 还提供了一种叫 task-state segment (TSS) 的硬件机制,可以在发生 task switch 时,自动保存 task 的状态信息,可理解为硬件辅助的进程切换,由于主流操作系统很少用到这一机制,在 Long Mode 中已经不再支持 TSS