简单GDB
之前学习了 ptrace 系统调用,看了别人写的各种 demo 和简单调试器
我想自己尝试写一个简单的 GDB
目前实现的功能如下:
- 单步执行(步入)
- 显示寄存器
- 显示内存
- 打断点
- 显示断点
代码如下:
1 |
|
简单GDB
之前学习了 ptrace 系统调用,看了别人写的各种 demo 和简单调试器
我想自己尝试写一个简单的 GDB
目前实现的功能如下:
代码如下:
1 |
|
1 | protocol: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, BuildID[sha1]=805aff424a7691b51b56996dad2d4c386ab3b31e, for GNU/Linux 3.2.0, stripped |
逆向出来没有符号,不过搜索到一个关键的字符串:
1 | sub_43ADCC(v7, 3LL, "/usr/local/include/google/protobuf/metadata_lite.h", 0x4ALL); |
然后在 IDA 中搜索其版本信息
1 | v5 = sub_43A79E(v4, " of the Protocol Buffer runtime library, but the installed version is "); |
1 | v4 = a2 / 1000000; |
环境搭建
先编译 protobuf:
1 | cd protobuf-3.21.8/ |
1 | sudo vim /etc/profile |
1 | sudo vim ~/.profile |
1 | sudo vim /etc/ld.so.conf |
1 | ➜ protocol protoc --version |
在 /protobuf-3.21.8/examples/ 中有 Cpp 的测试案例(记得在 Makefile 加上 “-g -static”)
1 | make cpp -j8 |
使用 Bindiff 修复一下符号:(虽然修不了 STL 但至少可以标识一下)
我们还需要下载 python protobuf,然后用如下命令进行安装:(写 exp 脚本时会用到)
1 | sudo python3 setup.py build |
1 | ➜ python python3 |
漏洞分析
1 | char buf[256]; // [rsp+140h] [rbp-140h] MAPDST BYREF |
j_strcpy_ifunc 造成栈溢出入侵思路
想要与 protobuf 程序进行交互,必须先找到 protobuf 的格式,以下 Github 项目可以完成这个工作:
1 | ➜ protocol ./pbtk/extractors/from_binary.py protocol |
ctf.proto 文件中就可以找到答案:1 | ➜ protocol cat ctf.proto |
然后参考 protobuf-3.21.8/examples 中的 python 使用案例,把 ctf.proto 文件处理为 python 可以识别的形式:
1 | ➜ protocol protoc --python_out=. ctf.proto |
ctf_pb2.py,这就是我们需要的目标库入侵的思路比较简单,就是利用栈溢出写入一个 ROP(这是 statically 文件,只能打 syscall)
只有一个问题比较烦人:j_strcpy_ifunc 会被 “\x00” 截断
解决的办法也比较暴力,分批次从下往上写 ROP 链,每次写入时前面的字符都填入“b”(需要利用 j_strcpy_ifunc 末尾补“\x00”的特性来写入“\x00”)
完整 exp:
1 | import ctf_pb2 |
1 | GNU C Library (Ubuntu GLIBC 2.27-3ubuntu1.6) stable release version 2.27 |
1 | bitheap: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=e08d4e4d4446d75cea81e7c8527abcfe54cc8768, stripped |
漏洞分析
1 | if ( num <= 0xF && chunk_list[num] ) |
1 | len = __read_chk(0LL, buf, size, 0x1008LL); |
入侵思路
比赛时我的思路很简单:
后来发现 one_gadget 打不通远程,于是把它换成 system,但还是打不通(但可以执行 puts,当时以为服务器上的文件开了沙盒)
之后打算用 ORW:
结果还是打不通远程,当时就以为是题目文件名不是“flag”,但回显信息说明 write 函数根本就没有执行(libc_base 是正确的,程序地址应该也没有问题),这就很郁闷
我当时的 exp 如下:
1 | from signal import pause |
我的队友把 exp 给我改了一下,改后的 exp 如下:
1 | #! /usr/bin/env python3 |
经过调试,有一个很明显的不同就是最后 free 的对象:
1 | *RDI 0x7f4b34e148e8 (__free_hook) —▸ 0x7f4b34a79085 (setcontext+53) ◂— mov rsp, qword ptr [rdi + 0xa0] |
1 | *RDI 0x55bf7fe49e30 ◂— 0x67616c662f2e /* './flag' */ |
其实我习惯于释放 free_hook ,感觉这个应该问题不大(因为本地已经出 flag 了),另一种可能就是我的“描述信息”不完整:
1 | arch = 64 |
1 | GNU C Library (Ubuntu GLIBC 2.27-3ubuntu1.6) stable release version 2.27 |
1 | sandbox: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=c27ca36e8af1c678abff1e5ec09e7d2979285761, stripped |
入侵思路
这题前面的过程都和 bitheap 一样,只是开了 ptrace 沙盒:
1 | if ( LODWORD(regs.orig_rax) <= 0x2710 && list[SLODWORD(regs.orig_rax)] ) |
list[SLODWORD(regs.orig_rax)] 中所指示的值:1 | __int64 __fastcall set(char a1) |
sys_execve-59 不可能位于白名单中sys_read-0 sys_write-1 sys_open-2 可以同时处于白名单中(需要两个 if 同时成立)sys_mprotect-10 也在白名单中1 | case 0x2710LL: |
rax=0x2710 rdi=0x3 就可以绕过沙盒于是我们需要对原来的 exp 进行修改,利用 sys_mprotect 使堆获取执行权限,然后再堆上执行 shellcode 来调整 rax rdi,然后执行 ORW 的过程
shellcode 如下:
1 | section .text |
1 | ➜ sandboxheap nasm -f elf64 sh.s -o sh.o |
剩下的工作就有些繁琐,需要以题目规定的格式写入 shellcode
在执行 ORW 之前会先执行以下这段 syscall:
1 | ► 0x56322a58cf40 syscall <SYS_<unk_10000>> |
完整 exp 如下:
1 | #! /usr/bin/env python3 |
1 | GNU C Library (Ubuntu GLIBC 2.27-3ubuntu1.6) stable release version 2.27 |
1 | unexploitable: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=5d66afeabecb7b7190cfbdbc4bb6b5846c896e2a, stripped |
入侵思路
1 | ssize_t pwn() |
只有一个栈溢出,没法泄露,没有后门
先进行调试,断点到 pwn 返回之前:
1 | 00:0000│ rsp 0x7ffc641e9d38 —▸ 0x564dcdc0070a ◂— add byte ptr [rax - 0x7b], cl |
__libc_start_main 为 one_gadget__libc_start_main 前面还有两个地址,我们不能覆盖有一个方法可以不破坏栈,并且修改 __libc_start_main:
pwn 中的溢出覆盖 pwn 的返回地址为 pwn,这样就相当于 pop 掉了一个地址__libc_start_main4*4 bit,最后 3*4 bit 位恒定,每次都有 1/16 的概率可以命中__libc_start_main 的 3*4 bit,每次都有 1/4096 的概率可以命中八字硬点还是可以拿到 flag 的
完整 exp:
1 | from signal import pause |
散列表(Hash Table,也叫哈希表),是根据关键码值(Key,Value)直接进行访问的数据结构
散列表的基本思想就是“链表的数组”:
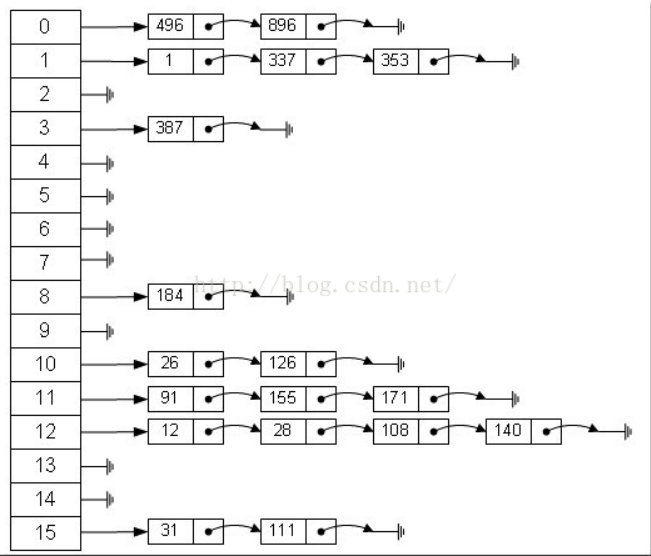
运用流程如下:
相比于正常的链表,散列表在插链之前先对链表的各个节点进行了“分组”(依赖哈希函数的无规律分组),在之后的查找/脱链过程中,程序只需要遍历对应的链表,而不是从头开始把所有的节点都遍历一遍
将目标编码转变为数组下标的方法就是散列法,常见的散列法如下:
index = value % 16index = (value * value) >> 28(value的类型为int,乘法的结果不会超过32位)value 本身当作乘数index = (value * 2654435769) >> 28散列表的优缺点如下:
XArray 是一种抽象的数据类型,其行为类似于一个非常大的指针数组,它满足了与散列或常规可调整大小的数组相同的许多需求
XArray 其实是根据基数树 Radix Tree 修改而来的:保持基数树的数据结构不变,将结构更改为数组
先对比一下 XArray 和 Radix Tree 的创建函数:
1 | static void *xas_create(struct xa_state *xas) |
1 | static int __radix_tree_create(struct radix_tree_root *root, |
两个函数之间,不管是函数名称还是执行流程,都有一些比较类似的地方,在条件符合时,两者可以互相替代
一些高版本的 kernel 开始使用 XArray 来替代原来的基数树:
address_space->i_pages 使用基数树1 | struct address_space { |
address_space->i_pages 使用 XArray 1 | struct address_space { |
TCP/IP 协议栈简述
TCP/IP 协议栈是一系列网络协议的总和,是构成网络通信的核心骨架,采用4层结构,分别是:
梳理一下每层模型的职责:
网络协议的注册/注销
协议在内核中用 packet_type 来表示,其拥有不同的容器:
ptype_base 中,其中哈希表中的每个元素都是一个双向链表:1 | struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly; /* 保存所有支持的3层协议(网际协议)处理函数的地方 */ |
ptype_all,它直接就是一个双向链表:1 | struct list_head ptype_all; /* 保存所有协议处理回调的地方(设备无关) */ |
struct net_device 中的一个条目,也是一个双向链表:1 | struct net_device { |
添加协议的 API 如下:
1 | void dev_add_pack(struct packet_type *pt) |
其中需要传入的 packet_type 结构体用于描述一个协议:
1 | struct packet_type { |
type:协议代码,表明了协议类型 dev:设备,指明了在哪个设备上使能该协议(dev 将 NULL 视为通配符,表示任意设备)func:对应协议的 Handler(处理程序,例如:在网卡收到数据后,netif_receive_skb 将会根据 skb->protocol 来调用相应的 func 来处理 skb)af_packet_priv:为 PF_PACKET 类型的 socket 使用,指向该 packet_type 的创建者相关的 sock 数据结构 list:协议链表头因此,协议的注册由两步完成:
packet_type 进行初始化dev_add_pack 把目标协议加入到 ptype_base相应的,协议的注销需要调用如下 API:
1 | void dev_remove_pack(struct packet_type *pt) |
数据包的处理流程
对于 ptype_base 和 ptype_all 两个类型的协议 Container(容器),协议 Handler 的调用方法是相似的:
packet_typedeliver_skb 间接调用 packet_type->funcpacket_type->funcptype_base 和 ptype_all 的不同之处在于:
ptype_all 本身就是一个双向链表,可以直接遍历ptype_base 则是一个包含了双向链表的哈希表, 在遍历之前需要根据 skb->protocol 来计算找到待遍历的双向链表当网卡收到数据包后,它会将数据包从网卡硬件缓存转移到服务器内存中(具体为 sk_buffer),然后触发一个中断来通知内核进行处理
内核会执行如下函数来处理 sk_buffer 中的数据包:
1 | int netif_receive_skb(struct sk_buff *skb) |
1 | static int netif_receive_skb_internal(struct sk_buff *skb) |
netif_receive_skb_internal 只是对数据包进行了 RPS(增加服务器的负载均衡,优化吞吐率)的处理,然后调用 __netif_receive_skb1 | static int __netif_receive_skb(struct sk_buff *skb) |
__netif_receive_skb_one_core:1 | static int __netif_receive_skb_one_core(struct sk_buff *skb, bool pfmemalloc) |
__netif_receive_skb_core,返回对应的 packet_type 并调用 packet_type->func__netif_receive_skb_core 的源码如下:1 | static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc, |
__netif_receive_skb_core 函数主要有几个处理:
ptype_all 处理(例如:抓包程序,raw socket 等)ptype_base 处理,并交给协议栈(例如:ip、arp,rarp 等)其中我们只需要关注与有关 ptype_base 的部分,这里才是对网络协议的处理:
skb->protocol 找到 ptype_base 中对应的双向链表packet_type->type == sk_buff->protocolpacket_type->func 完成对数据包的处理Linux 系统调用 - ptrace
ptrace 是 Linux 中的一个系统调用,可以让父进程控制子进程运行,并可以检查和改变子进程的核心 image 的功能
其基本原理是:
ptrace 在用户态的定义如下:
1 | long int |
1 |
|
ptrace 在内核中的接口如下:
1 | SYSCALL_DEFINE4(ptrace, long, request, long, pid, unsigned long, addr, |
常见 ptrace 命令如下:
1 | /* Type of the REQUEST argument to `ptrace.' */ |
ptrace 的使用 - 调试
Linux 调试工具 GDB 的底层就是使用了 ptrace,主要是 PTRACE_ATTACH 功能
在使用 ptrace 之前需要在两个进程间建立追踪关系:(追踪者 tracer 和被追踪者 tracee)
其中会用到4个 ptrace 命令:
ORIG_RAX 计算 RAX 的偏移,从而获取将要执行的系统调用号user_regs_struct 进行保存使用 ptrace 的编程案例如下:
1 |
|
被测试的文件:
1 | int main(){ |
结果:
1 | ➜ exp ./test |
execve-59 构建进程上下文到调用 write-1 的全过程ptrace 的使用 - 反调试
ptrace 反调试的核心就在于主动执行 PTRACE_TRACEME:
测试案例如下:
1 |
|
正常执行结果:
1 | ➜ exp ./test |
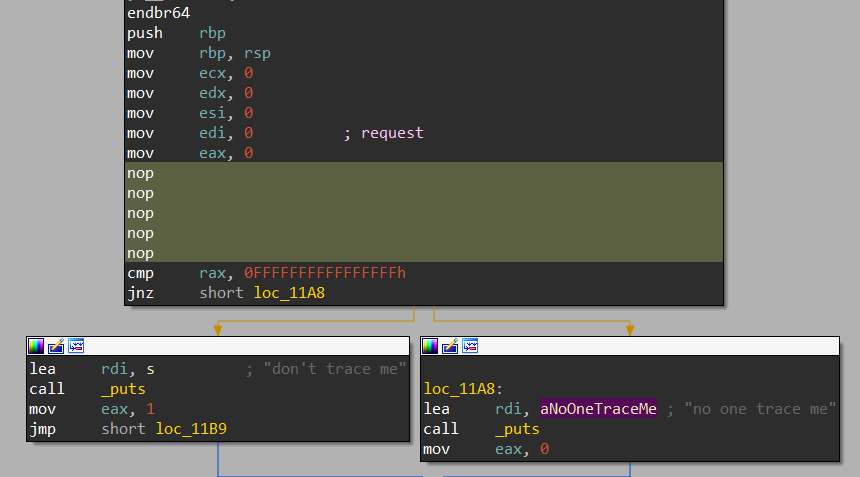
调试结果:
1 | c |
绕过的方式很简单,只要把相关的地方给 nop 掉就好:
可以直接查看符号表来确定是否存在 prtace:
1 | ➜ exp objdump -t test | grep ptrace |
ptrace 的使用 - 代码注入
ptrace 可以对进程的追踪,并进行流程控制:
需要用到的 ptrace 命令如下:
下面程序用于在 tracee 中注入一段 shellcode:
1 |
|
其中的 shellcode 就是 execve(/bin/sh),汇编如下:
1 | section .text |
1 | ➜ exp nasm -f elf64 sh.s -o sh.o |
1 | ➜ exp objdump --disassemble ./sh |
测试文件如下:
1 |
|
hackme
1 | ! /bin/sh |
漏洞分析
1 | if ( cmd == 0x30002 ) // HACK_WRITE |
1 | else if ( cmd == 0x30003 ) // HACK_READ |
userdata.offset 是符号数,并且没有限制其必须为正数userdata.offset 为负数就可以在 kheap_ptr[userdata.offset] 中向上溢出入侵思路 - Tty_struct Attack
tty_struct attack 可以用于泄露 kernel_base,如果想用它来提权,则需要泄露 heap_addr
本题目的溢出可以轻松泄露空闲块的 next 指针,然后泄露出 heap_addr
1 | kcreate(2,buf,0x100); |
1 | pwndbg> x/20xg 0xffffa1f380179400 |
0x400 0x600 0x700 都是 free 状态由于系统开启了 smap,内核需要使用 copy_from_user 才能访问用户态数据,于是我们利用 kcreate 把 fake_tty_operations 指针和 rop 指针保存到内核的堆里:
1 | kcreate(2,(char *)rop,0x100); |
对于 tty_struct attack,还需要一个关键的 gadget,其目的是为了栈迁移(把 RAX 中的数据转移到 RSP 中):
mov rax, rsppush rax + pop rsp剩下的操作就比较套路化了,可以当做是 tty_struct attack 的模板,注意控制一下 CR4 寄存器就好
完整 exp:
1 |
|
pop rsp 的 gadget 重定位到一个文件中,然后再这个文件中搜索 push rax)入侵思路 - Modprobe_path Attack
modprobe_path 是用于在 Linux 内核中添加可加载的内核模块,当我们在 Linux 内核中安装或卸载新模块时,就会执行 modprobe_path 指向的程序
因此我们需要劫持 modprobe_path,劫持的方法就是利用 Slab 空闲块的 next 指针
1 | /home/pwn |
modprobe_path 的偏移如果通过劫持 next 指针实现 WAA,就需要注意一个细节:
system 中出现错误(因为 system 也会利用 Slab 来分配内存)system 前需要先 kfree 一些内存块,使 system 优先申请这些合法的内存块,从而避免报错完整 exp:
1 |
|
入侵思路 - Cred Attack
cred attack 的思路特别简单,扫描到 cred 然后将其修改
扫描的过程中,通常有两种定位方法:
task_struct 中,通过 *real_cred 和 *cred 下方的字符串间接定位到 *cred,然后利用该指针获取 cred 的地址1 | const struct cred __rcu *real_cred; |
cred 中,通过以下8个字段都等于 UID 来直接定位 cred(UID 通常为 1000)1 | kuid_t uid; /* real UID of the task */ |
定位到 cred 以后,就可以把 [uid] - [fsgid] 这8个字段全部置空,然后把置空后的数据返回给内核
在这个过程中,唯一的问题就是需要的空间太大,在用户态必须用 mmap 进行分配,而 copy_from_user 在检测到 mmap 分配空间后就会报错
其实 Double Fetch 中的 userfaultfd 机制早就解决了这个问题,因为我们不需要使用它进行条件竞争,于是我们在 handler 里进行 sleep 就好
完整 exp:
1 |
|
RCU 简述
RCU(Read-Copy Update),是 Linux 中比较重要的一种同步机制,特点如下:
复制后更新是 Linux 内核实现的一种针对“读多写少”的共享数据的同步机制:
延迟回收内存是为了防止已经被销毁的数据被其他线程使用:
RCU 作用
RCU 的一个典型的应用场景是链表,主要解决以下问题:
RCU API
添加链表项:
1 |
|
rcu_assign_pointer 函数,其他地方和普通的 __list_add 没什么不同,该函数的底层应该是一个内存屏障(防止 CPU 优化执行顺序),以避免在新指针 new 准备好之前,就被引用了删除链表项:
1 | static inline void list_del_rcu(struct list_head *entry) |
list_del 相比,list_del_rcu 只对 entry->prev 进行了处理(目前不知道原因) 更新链表:
1 | static inline void list_replace_rcu(struct list_head *old, |
old->prev 进行了处理访问链表:
1 | rcu_read_lock(); /* 声明了一个读端的临界区(read-side critical sections) */ |
rcu_read_lock 和 rcu_read_unlock 用来标识 RCU read side 临界区(其作用就是帮助检测宽限期是否结束)RCU 机制
宽限期:(Grace period)
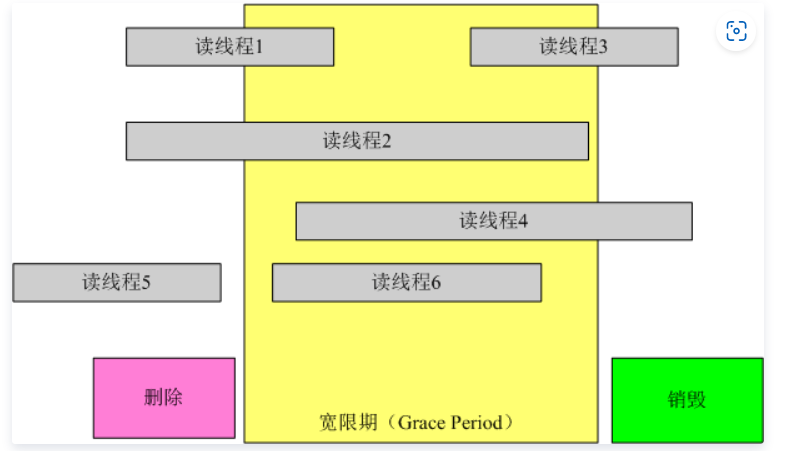
1 | void synchronize_rcu(void) |
rcu_read_lock 和 rcu_read_unlock 所标记的区域进行判断发布-订阅机制:(Publish-Subscribe Mechanism)
1 | static inline void __list_add_rcu(struct list_head *new, |
rcu_assign_pointer 函数的使用,用于解决优化导致的 CPU 执行顺序问题1 |
复制更新机制:(Copy Update)
1 | p = /* 将要被替换的对象 */ |
synchronize_rcu 可以防止在 list_replace_rcu 之后,kfree 之前,有读线程使用了正在进行更新的链表节点kfree 就不会引发安全问题了RCU 案例
Reader 正在遍历查找链表节点:
1 | int search(long key, int *result) { |
Writer 正在遍历删除链表节点:
1 | int delete(long key) { |
假设一个线程执行 Reader,另一个线程执行 Writer:
synchronize_rcu 上等待持有旧指针的 Reader 执行完毕,只是牺牲了 Writer 的效率就避免了安全问题参考:
procfs 被称为 “进程文件系统” 或 “伪文件系统”,它是一个控制中心,可以通过更改其中某些文件改变内核运行状态,它也是内核提空给我们的查询中心,用户可以通过它查看系统硬件及当前运行的进程信息
procfs 为 Linux 中的许多命令提供了信息,例如:lsmod 的命令和 cat /proc/modules
1 | ➜ ~ lsmod |
1 | ➜ ~ cat /proc/modules |
procfs 通过 VFS 把内核的抽象文件作为常规文件映射到一个目录树中:
1 | ➜ ~ ls /proc |
sysfs 包括系统所有的硬件信息以及内核模块等信息(为设备驱动服务)
Linux-2.6-kernel 中增加了一个引人注目的新特性:统一设备模型 device model
统一设备模型的核心部分就是设备驱动模型 kobject,它就是 device model 拓扑树中的各个节点
而 sysfs 为我们提供 kobject 对象层次结构的视图,帮助用户可以以一个简单文件系统的方式来观察各种设备的拓扑结构:
1 | ➜ / ls sys |
devfs 被称为设备文件系统
devfs 将所有系统中的设备以动态文件系统命名空间呈现,devfs 也可以通过内核设备驱动直接管理这些命名空间和接口,以此来提供智能的设备管理(包括设备入口注册/注销)
因此,当我们需要操控某个设备的时候,需要使用对应的 API 来进行注册/注销:
1 | int register_chrdev_region(dev_t first, unsigned int count, char *name); |
1 | int register_blkdev(unsigned int, const char *); |
/dev 目录中生成一个对应的文件knote 复现
1 | !/bin/sh |
1 | !/bin/sh |
1 | / $ cat /proc/version |
模块分析
1 | int __cdecl note_init() |
misc_device 是特殊的字符设备,注册驱动程序时采用 misc_register 函数注册 漏洞分析
1 | void __cdecl edit() |
myarg.buf 为全局变量,有条件竞争漏洞Double Fetch
Double Fetch 从漏洞原理上属于条件竞争漏洞,是一种内核态与用户态之间的数据访问竞争
copy_from_user 等拷贝函数将用户数据拷贝至内核空间进行校验及相关处理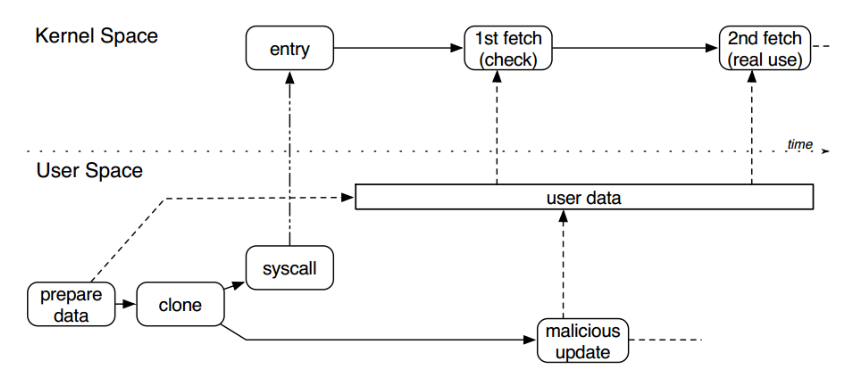
Double Fetch 需要使用 userfaultfd 机制:
现在来看一个详细的例子:
1 | if (ptr) { |
user_buf 是一块 mmap 映射的未初始化区域,此时就会触发缺页错误 copy_from_user 将暂停执行tty_struct)copy_from_user 恢复执行,然而 ptr 此时指向的是 tty_struct 结构,那么就能对 tty_struct 结构进行修改了(当然也可以是其他的结构体)模板如下:
1 | void userfault(void *fault_page,void *handler) |
处理函数 handler 的模板如下:
1 | void* handler(void *arg) |
Modprobe_path Attack
modprobe_path 是用于在 Linux 内核中添加可加载的内核模块,当我们在 Linux 内核中安装或卸载新模块时,就会执行 modprobe_path 指向的程序
他的路径是一个内核全局变量,默认为 /sbin/modprobe,源码如下:
1 | /* modprobe_path is set via /proc/sys */ |
1 | ➜ ~ cat /proc/sys/kernel/modprobe |
modprobe 命令(在 sbin 目录中,说明该程序拥有 Root 权限)modprobe_path 在内核中且具有可写权限(普通权限即可修改该值)而当内核运行一个错误格式的文件(或未知文件类型的文件)的时候,内核调用 call_modprobe 函数执行 modprobe_path 指向的文件:
call_modprobe 函数拥有 Root 权限modprobe_path,指向我们提权的脚本,然后 system 一个非法文件,就能触发提权脚本的执行1 | do_execve() -> do_execveat_common() -> __do_execve_file() -> exec_binprm() -> search_binary_handler() -> request_module() -> call_modprobe() -> call_usermodehelper_exec() |
使用案例如下:
1 | system("echo '#!/bin/sh' > /tmp/shell.sh"); |
modprobe_path 修改为了 /tmp/shell.sh(提权脚本)/tmp/fake 不可执行时,就会通过 call_modprobe 来调用 modprobe_path 所指向的命令/tmp/shell.sh 完成提权Slab Heap
Linux 内核使用的是 slab/slub 分配器,以内存池的形式分配内存(大小相同的堆靠在一起,8K的内存池专门管理8K的堆空间,16字节的内存池专门管理16字节的堆空间),使用如下命令可以查看 slab 内存池:
1 | ➜ ~ sudo cat /proc/slabinfo |
slab 为了提高效率实现了一个机制:
kfree 后,原用户数据区的前8字节会有指向下一个空闲块的指针 nextmalloc 的大小在空闲的堆块里有满足要求的,则直接取出有一个比较容易利用的就是,伪造空闲块的 next 指针,则可以很容易分配到我们想要读写的地方(不像 ptmalloc2 还需要伪造堆结构,这里只需要更改 next 指针即可)
入侵思路
利用 Double Fetch 可以在内核全局变量中写入一个 tty_struct
但是 5.0 版本以上的内核很难 ROP 到用户态(通过修改 tty_struct->tty_operations 为 gadget,ROP 到用户态的办法失效了)
此时需要另一个入侵技巧 modprobe_path attack,通过伪造空闲堆的 next 指针,实现任意地址处分配,把 modprobe_path 分配到可控区域,然后进行修改
最后就是 modprobe_path attack 的攻击流程了
完整 exp:
1 |
|
memcpy 复制了一个内核地址到 page,那么把该 page 的内容打印出来就是 0xffffffc0(实际上是正确的数据),不知道这是不是内核的保护机制小结:
学到了 Double Fetch 和 modprobe_path attack:
Double Fetch:如果 copy_user 系列函数使用的是全局变量并且没有加锁,就可以使用这个方法modprobe_path attack:对于 5.0 版本以上的内核很难使用 ROP 来绕过 smep,这种攻击算一种替代名,还可以利用 mov cr4,xxx 使得 CR4 寄存器的第21/22位为“0”,即可关闭 smap/smep现在对这个利用还不熟,只能用用模板,感觉 userfaultfd 机制有点难理解(还不清楚为什么模板要这么写),之后抽时间了解一下
Struct address_space
1 | struct page { |
page 中有一个特殊的成员 mapping,指向地址空间描述的结构指针file 和结构体 inode 中都有一个结构体 address_space 指针(file->f_mapping 是由 inode->i_mapping 初始化而来)1 | struct address_space { |
address_space->i_pages 的作用就是用于存储文件的 Page Cacheaddress_space 与一个偏移量能够确定一个 page cache 或 swap cache 中的一个页面Page Cache
所以为了避免每次读写文件时,都需要对硬盘进行读写操作,Linux 内核使用页缓存(Page Cache)机制来对文件中的数据进行缓存
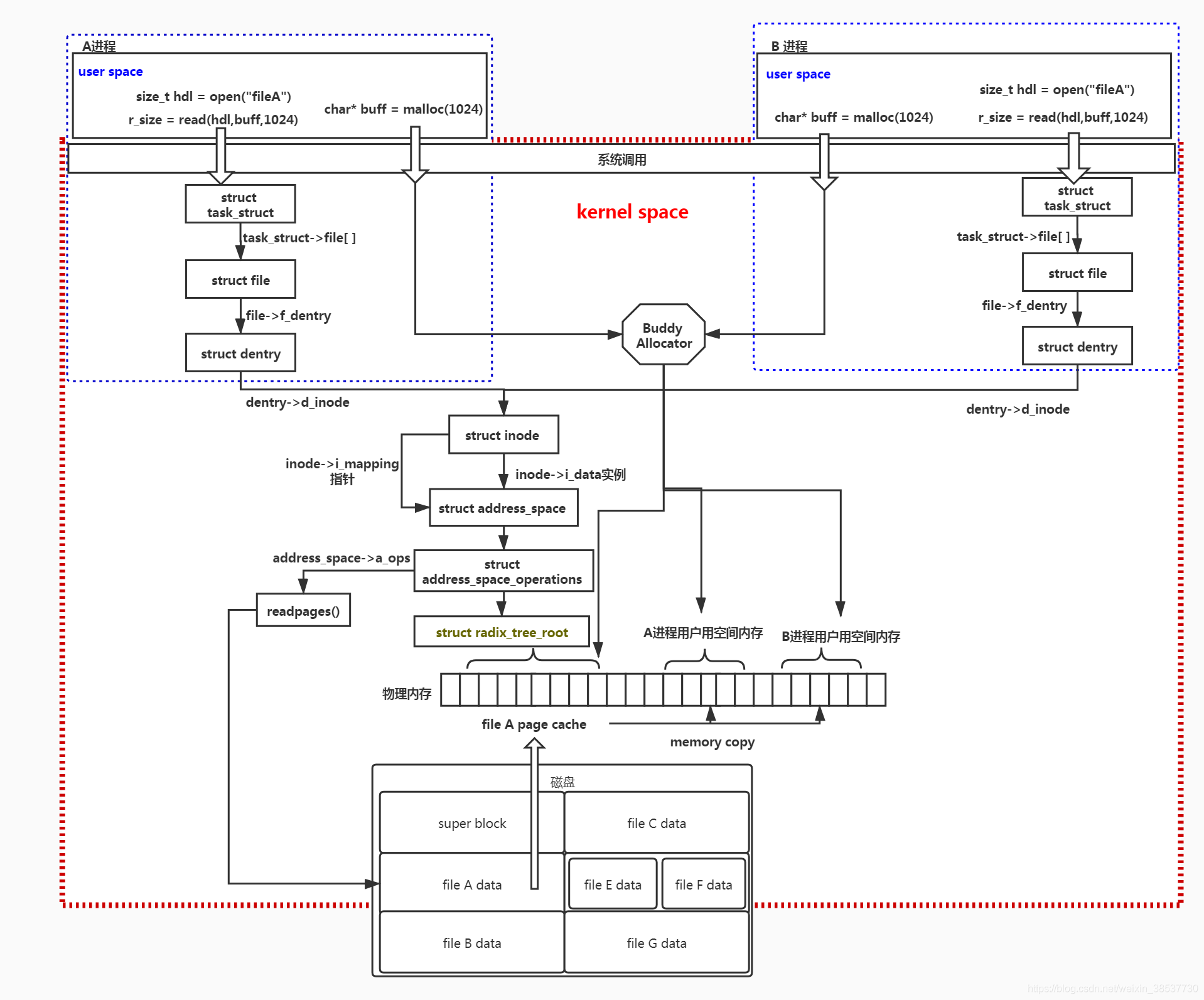
如果进程需要 page 而 free page 严重短缺的时候,进程可以唤醒这些内核线程来回收缓存的页面,一方面缓存,一方面回收达到一种平衡,同时改善了系统的性能
Swap
在 Linux 下,当物理内存不足时,拿出部分硬盘空间当 Swap 分区(也被称为“虚拟内存”,从硬盘中划分出的一个分区),从而解决内存容量不足的情况
Swap Cache
Swap Cache 就是 Swap 的缓存,它的作用不是说要加快磁盘的I/O效率
page,比如用户进程通过 malloc 申请的内存页(函数 mmap 也可以申请匿名页)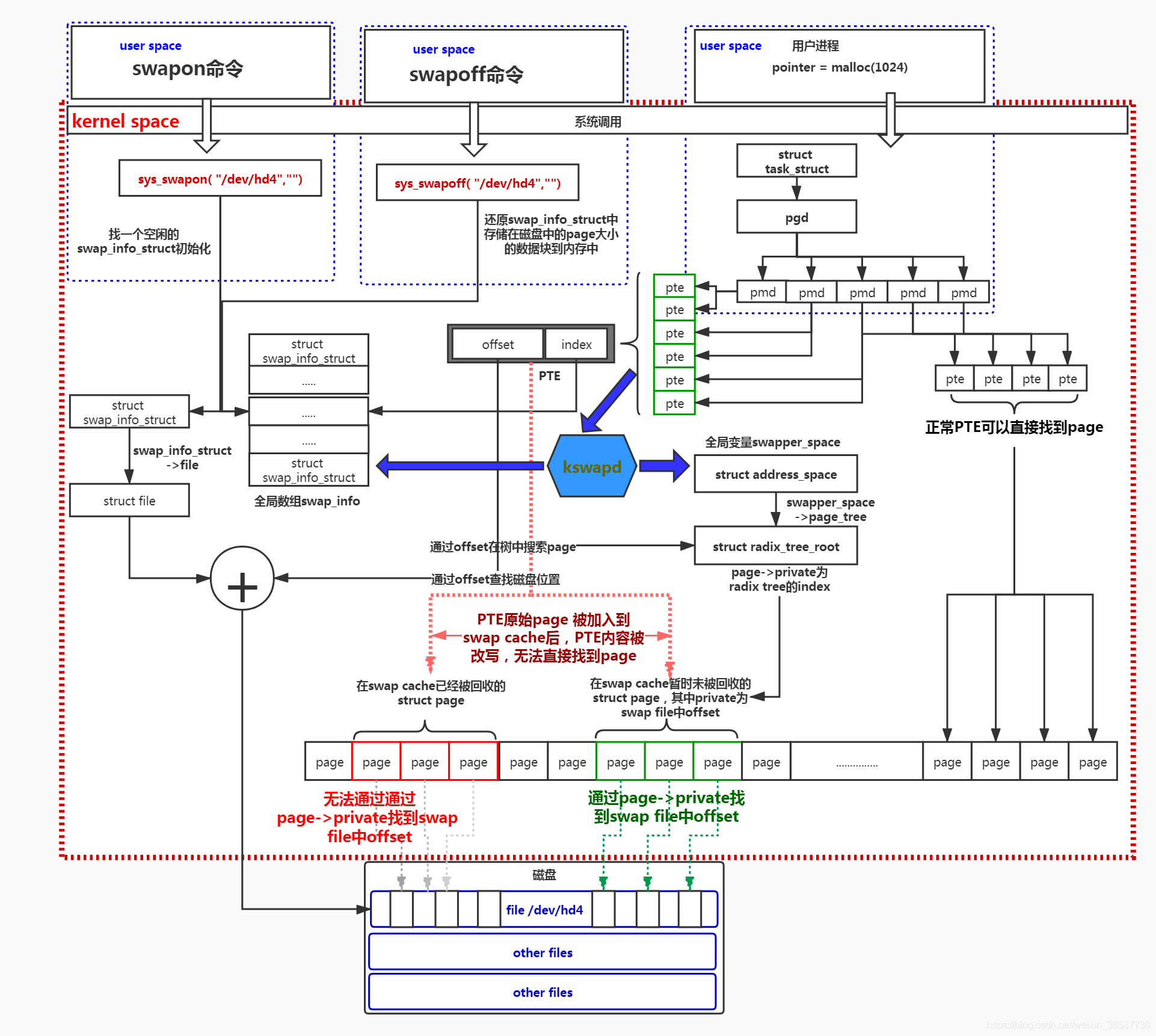
Swap Cache 主要是为了防止页面在 Swap In 和 Swap Out 时进程的同步问题
page frame 是在 swap cachepage frame 进行访问,那么 swap cache 才会释放 page frame,将其交给 buddy systempage 完全放入磁盘之后它就会从 Swap Cache 中删除(毕竟 Swap Out 的目的就是为了腾出空闲内存)