最后还有一个小问题,var i = 0 原本应该分配到栈上,但 go 编译器会自动识别这种情况并将其分配到堆上
1 2 3 4 5 6 7 8 9 10 11 12 13 14
package main
funcincSeq()func()int { var i = 0 returnfunc()int { i++ return i } }
funcmain() { next := incSeq() next() }
1
go build --gcflags=-m test.go
使用 escape analyze
1 2 3 4 5 6 7 8 9
# command-line-arguments ./test.go:3:6: can inline incSeq ./test.go:5:9: can inline incSeq.func1 ./test.go:12:16: inlining call to incSeq ./test.go:5:9: can inline main.func1 ./test.go:13:6: inlining call to main.func1 ./test.go:4:6: moved to heap: i /* 被转移到堆空间 */ ./test.go:5:9: funcliteralescapestoheap ./test.go:12:16: funcliteraldoesnotescape
关键字-go
go 语言支持并发,我们只需要通过 go 关键字来开启 goroutine(协程,轻量级线程)即可
协程:子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行
1 2 3 4 5 6 7 8 9 10 11 12
package main
import"fmt"
funcgotest(a, b, c int)int { fmt.Println(a, b, c) return a + b + c }
type g struct { stack stack // offset known to runtime/cgo /* type stack struct { lo uintptr // 该协程拥有的栈低位 hi uintptr // 该协程拥有的栈高位 } */ stackguard0 uintptr// 检查栈空间是否足够的值,低于这个值会扩张栈 stackguard1 uintptr// 检查栈空间是否足够的值,低于这个值会扩张栈
_panic *_panic // innermost panic - offset known to liblink _defer *_defer // innermost defer m *m // current m; offset known to arm liblink sched gobuf // 用于记录协程切换的上下文 syscallsp uintptr// if status==Gsyscall, syscallsp = sched.sp to use during gc syscallpc uintptr// if status==Gsyscall, syscallpc = sched.pc to use during gc stktopsp uintptr// expected sp at top of stack, to check in traceback // param is a generic pointer parameter field used to pass // values in particular contexts where other storage for the // parameter would be difficult to find. It is currently used // in four ways: // 1. When a channel operation wakes up a blocked goroutine, it sets param to // point to the sudog of the completed blocking operation. // 2. By gcAssistAlloc1 to signal back to its caller that the goroutine completed // the GC cycle. It is unsafe to do so in any other way, because the goroutine's // stack may have moved in the meantime. // 3. By debugCallWrap to pass parameters to a new goroutine because allocating a // closure in the runtime is forbidden. // 4. When a panic is recovered and control returns to the respective frame, // param may point to a savedOpenDeferState. param unsafe.Pointer // 用于传递参数,睡眠时其它goroutine设置param,唤醒时此goroutine可以获取 atomicstatus atomic.Uint32 stackLock uint32// sigprof/scang lock; TODO: fold in to atomicstatus goid uint64// goroutine的id号 schedlink guintptr waitsince int64// approx time when the g become blocked waitreason waitReason // if status==Gwaiting
preempt bool// preemption signal, duplicates stackguard0 = stackpreempt preemptStop bool// transition to _Gpreempted on preemption; otherwise, just deschedule preemptShrink bool// shrink stack at synchronous safe point
// asyncSafePoint is set if g is stopped at an asynchronous // safe point. This means there are frames on the stack // without precise pointer information. asyncSafePoint bool
paniconfault bool// panic (instead of crash) on unexpected fault address gcscandone bool// g has scanned stack; protected by _Gscan bit in status throwsplit bool// must not split stack // activeStackChans indicates that there are unlocked channels // pointing into this goroutine's stack. If true, stack // copying needs to acquire channel locks to protect these // areas of the stack. activeStackChans bool // parkingOnChan indicates that the goroutine is about to // park on a chansend or chanrecv. Used to signal an unsafe point // for stack shrinking. parkingOnChan atomic.Bool // inMarkAssist indicates whether the goroutine is in mark assist. // Used by the execution tracer. inMarkAssist bool coroexit bool// argument to coroswitch_m
raceignore int8// ignore race detection events nocgocallback bool// whether disable callback from C tracking bool// whether we're tracking this G for sched latency statistics trackingSeq uint8// used to decide whether to track this G trackingStamp int64// timestamp of when the G last started being tracked runnableTime int64// the amount of time spent runnable, cleared when running, only used when tracking lockedm muintptr // G被锁定只能在这个M上运行 sig uint32 writebuf []byte sigcode0 uintptr sigcode1 uintptr sigpc uintptr parentGoid uint64// 父类goroutine的goid gopc uintptr// 创建这个goroutine的go表达式的pc ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors) startpc uintptr// pc of goroutine function racectx uintptr waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order cgoCtxt []uintptr// cgo traceback context labels unsafe.Pointer // profiler labels timer *timer // cached timer for time.Sleep sleepWhen int64// when to sleep until selectDone atomic.Uint32 // are we participating in a select and did someone win the race?
coroarg *coro // argument during coroutine transfers
// goroutineProfiled indicates the status of this goroutine's stack for the // current in-progress goroutine profile goroutineProfiled goroutineProfileStateHolder
// Per-G tracer state. trace gTraceState
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of // bytes allocated. If this is positive, then the G has credit // to allocate gcAssistBytes bytes without assisting. If this // is negative, then the G must correct this by performing // scan work. We track this in bytes to make it fast to update // and check for debt in the malloc hot path. The assist ratio // determines how this corresponds to scan work debt. gcAssistBytes int64 }
type m struct { g0 *g // 带有调度栈的goroutine morebuf gobuf // gobuf arg to morestack divmod uint32// div/mod denominator for arm - known to liblink _ uint32// align next field to 8 bytes
// Fields not known to debuggers. procid uint64// for debuggers, but offset not hard-coded gsignal *g // 关联P以执行Go代码 goSigStack gsignalStack // Go-allocated signal handling stack sigmask sigset // storage for saved signal mask tls [tlsSlots]uintptr// thread-local storage (for x86 extern register) mstartfn func() curg *g // M中当前运行的goroutine caughtsig guintptr // goroutine running during fatal signal p puintptr // attached p for executing go code (nil if not executing go code) nextp puintptr oldp puintptr // the p that was attached before executing a syscall id int64 mallocing int32// 状态 throwing throwType preemptoff string// if != "", keep curg running on this m locks int32 dying int32 profilehz int32 spinning bool// m is out of work and is actively looking for work blocked bool// m is blocked on a note newSigstack bool// minit on C thread called sigaltstack printlock int8 incgo bool// m is executing a cgo call isextra bool// m is an extra m isExtraInC bool// m is an extra m that is not executing Go code isExtraInSig bool// m is an extra m in a signal handler freeWait atomic.Uint32 // Whether it is safe to free g0 and delete m (one of freeMRef, freeMStack, freeMWait) needextram bool traceback uint8 ncgocall uint64// number of cgo calls in total ncgo int32// number of cgo calls currently in progress cgoCallersUse atomic.Uint32 // if non-zero, cgoCallers in use temporarily cgoCallers *cgoCallers // cgo traceback if crashing in cgo call park note alllink *m // 用于链接allm schedlink muintptr lockedg guintptr createstack [32]uintptr// stack that created this thread, it's used for StackRecord.Stack0, so it must align with it. lockedExt uint32// tracking for external LockOSThread lockedInt uint32// tracking for internal lockOSThread nextwaitm muintptr // next m waiting for lock
mLockProfile mLockProfile // fields relating to runtime.lock contention
// wait* are used to carry arguments from gopark into park_m, because // there's no stack to put them on. That is their sole purpose. waitunlockf func(*g, unsafe.Pointer)bool waitlock unsafe.Pointer waitTraceBlockReason traceBlockReason waitTraceSkip int
syscalltick uint32 freelink *m // on sched.freem trace mTraceState
// these are here because they are too large to be on the stack // of low-level NOSPLIT functions. libcall libcall libcallpc uintptr// for cpu profiler libcallsp uintptr libcallg guintptr syscall libcall // stores syscall parameters on windows
vdsoSP uintptr// SP for traceback while in VDSO call (0 if not in call) vdsoPC uintptr// PC for traceback while in VDSO call
// preemptGen counts the number of completed preemption // signals. This is used to detect when a preemption is // requested, but fails. preemptGen atomic.Uint32
// Whether this is a pending preemption signal on this M. signalPending atomic.Uint32
// pcvalue lookup cache pcvalueCache pcvalueCache
dlogPerM
mOS
chacha8 chacha8rand.State cheaprand uint64
// Up to 10 locks held by this m, maintained by the lock ranking code. locksHeldLen int locksHeld [10]heldLockInfo }
普通的 goroutine 的栈是在堆上分配的可增长的栈,而 g0 的栈是 M 对应的线程的栈
所有调度相关的代码,会先切换到该 goroutine 的栈中再执行
结构体P
P 是 Processor 逻辑处理器的缩写,每个 P 拥有一个本地队列并为 G 在 M 上的运行提供本地化资源
M 代表 OS 线程,P 代表 go 代码执行时需要的资源,当 M 执行 go 代码时,它需要关联一个 P
type p struct { id int32 status uint32// one of pidle/prunning/... link puintptr schedtick uint32// 每次调度时将它+1 syscalltick uint32// incremented on every system call sysmontick sysmontick // last tick observed by sysmon m muintptr // back-link to associated m (nil if idle) mcache *mcache // 系统线程缓存 pcache pageCache raceprocctx uintptr
deferpool []*_defer // pool of available defer structs (see panic.go) deferpoolbuf [32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. goidcache uint64 goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock. runqhead uint32 runqtail uint32 runq [256]guintptr // runnext, if non-nil, is a runnable G that was ready'd by // the current G and should be run next instead of what's in // runq if there's time remaining in the running G's time // slice. It will inherit the time left in the current time // slice. If a set of goroutines is locked in a // communicate-and-wait pattern, this schedules that set as a // unit and eliminates the (potentially large) scheduling // latency that otherwise arises from adding the ready'd // goroutines to the end of the run queue. // // Note that while other P's may atomically CAS this to zero, // only the owner P can CAS it to a valid G. runnext guintptr
// Available G's (status == Gdead) gFree struct { gList n int32 }
sudogcache []*sudog sudogbuf [128]*sudog
// Cache of mspan objects from the heap. mspancache struct { // We need an explicit length here because this field is used // in allocation codepaths where write barriers are not allowed, // and eliminating the write barrier/keeping it eliminated from // slice updates is tricky, more so than just managing the length // ourselves. lenint buf [128]*mspan }
// Cache of a single pinner object to reduce allocations from repeated // pinner creation. pinnerCache *pinner
trace pTraceState
palloc persistentAlloc // per-P to avoid mutex
// Per-P GC state gcAssistTime int64// Nanoseconds in assistAlloc gcFractionalMarkTime int64// Nanoseconds in fractional mark worker (atomic)
// limiterEvent tracks events for the GC CPU limiter. limiterEvent limiterEvent
// gcMarkWorkerMode is the mode for the next mark worker to run in. // That is, this is used to communicate with the worker goroutine // selected for immediate execution by // gcController.findRunnableGCWorker. When scheduling other goroutines, // this field must be set to gcMarkWorkerNotWorker. gcMarkWorkerMode gcMarkWorkerMode // gcMarkWorkerStartTime is the nanotime() at which the most recent // mark worker started. gcMarkWorkerStartTime int64
// gcw is this P's GC work buffer cache. The work buffer is // filled by write barriers, drained by mutator assists, and // disposed on certain GC state transitions. gcw gcWork
// wbBuf is this P's GC write barrier buffer. // // TODO: Consider caching this in the running G. wbBuf wbBuf
runSafePointFn uint32// if 1, run sched.safePointFn at next safe point
// statsSeq is a counter indicating whether this P is currently // writing any stats. Its value is even when not, odd when it is. statsSeq atomic.Uint32
// Timer heap. timers timers
// maxStackScanDelta accumulates the amount of stack space held by // live goroutines (i.e. those eligible for stack scanning). // Flushed to gcController.maxStackScan once maxStackScanSlack // or -maxStackScanSlack is reached. maxStackScanDelta int64
// gc-time statistics about current goroutines // Note that this differs from maxStackScan in that this // accumulates the actual stack observed to be used at GC time (hi - sp), // not an instantaneous measure of the total stack size that might need // to be scanned (hi - lo). scannedStackSize uint64// stack size of goroutines scanned by this P scannedStacks uint64// number of goroutines scanned by this P
// preempt is set to indicate that this P should be enter the // scheduler ASAP (regardless of what G is running on it). preempt bool
// pageTraceBuf is a buffer for writing out page allocation/free/scavenge traces. // // Used only if GOEXPERIMENT=pagetrace. pageTraceBuf pageTraceBuf
// Padding is no longer needed. False sharing is now not a worry because p is large enough // that its size class is an integer multiple of the cache line size (for any of our architectures). }
在 P 中有一个 Grunnable 的 goroutine 队列,这是一个 P 的局部队列
当 P 执行 go 代码时,它会优先从自己的这个局部队列中取,这时可以不用加锁,提高了并发度
如果发现这个队列空了,则去其它 P 的队列中拿一半过来,这样实现工作流窃取的调度(这种情况下是需要给调用器加锁的)
type schedt struct { goidgen atomic.Uint64 lastpoll atomic.Int64 // time of last network poll, 0 if currently polling pollUntil atomic.Int64 // time to which current poll is sleeping
lock mutex
// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be // sure to call checkdead().
midle muintptr // idle m's waiting for work nmidle int32// number of idle m's waiting for work nmidlelocked int32// number of locked m's waiting for work mnext int64// number of m's that have been created and next M ID maxmcount int32// maximum number of m's allowed (or die) nmsys int32// number of system m's not counted for deadlock nmfreed int64// cumulative number of freed m's
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's npidle atomic.Int32 // idle P的数量 nmspinning atomic.Int32 // See "Worker thread parking/unparking" comment in proc.go. needspinning atomic.Uint32 // See "Delicate dance" comment in proc.go. Boolean. Must hold sched.lock to set to 1.
// Global runnable queue. runq gQueue runqsize int32
// disable controls selective disabling of the scheduler. // // Use schedEnableUser to control this. // // disable is protected by sched.lock. disable struct { // user disables scheduling of user goroutines. user bool runnable gQueue // pending runnable Gs n int32// length of runnable }
// Global cache of dead G's. gFree struct { lock mutex stack gList // Gs with stacks noStack gList // Gs without stacks n int32 }
// Central cache of sudog structs. sudoglock mutex sudogcache *sudog
// Central pool of available defer structs. deferlock mutex deferpool *_defer
// freem is the list of m's waiting to be freed when their // m.exited is set. Linked through m.freelink. freem *m
gcwaiting atomic.Bool // gc is waiting to run stopwait int32 stopnote note sysmonwait atomic.Bool sysmonnote note
// safePointFn should be called on each P at the next GC // safepoint if p.runSafePointFn is set. safePointFn func(*p) safePointWait int32 safePointNote note
profilehz int32// cpu profiling rate
procresizetime int64// nanotime() of last change to gomaxprocs totaltime int64// ∫gomaxprocs dt up to procresizetime
// sysmonlock protects sysmon's actions on the runtime. // // Acquire and hold this mutex to block sysmon from interacting // with the rest of the runtime. sysmonlock mutex
// timeToRun is a distribution of scheduling latencies, defined // as the sum of time a G spends in the _Grunnable state before // it transitions to _Grunning. timeToRun timeHistogram
// idleTime is the total CPU time Ps have "spent" idle. // // Reset on each GC cycle. idleTime atomic.Int64
// totalMutexWaitTime is the sum of time goroutines have spent in _Gwaiting // with a waitreason of the form waitReasonSync{RW,}Mutex{R,}Lock. totalMutexWaitTime atomic.Int64
// stwStoppingTimeGC/Other are distributions of stop-the-world stopping // latencies, defined as the time taken by stopTheWorldWithSema to get // all Ps to stop. stwStoppingTimeGC covers all GC-related STWs, // stwStoppingTimeOther covers the others. stwStoppingTimeGC timeHistogram stwStoppingTimeOther timeHistogram
// stwTotalTimeGC/Other are distributions of stop-the-world total // latencies, defined as the total time from stopTheWorldWithSema to // startTheWorldWithSema. This is a superset of // stwStoppingTimeGC/Other. stwTotalTimeGC covers all GC-related STWs, // stwTotalTimeOther covers the others. stwTotalTimeGC timeHistogram stwTotalTimeOther timeHistogram
// totalRuntimeLockWaitTime (plus the value of lockWaitTime on each M in // allm) is the sum of time goroutines have spent in _Grunnable and with an // M, but waiting for locks within the runtime. This field stores the value // for Ms that have exited. totalRuntimeLockWaitTime atomic.Int64 }
其中有 M 的 idle 队列,P 的 idle 队列,以及一个全局的就绪的 G 队列
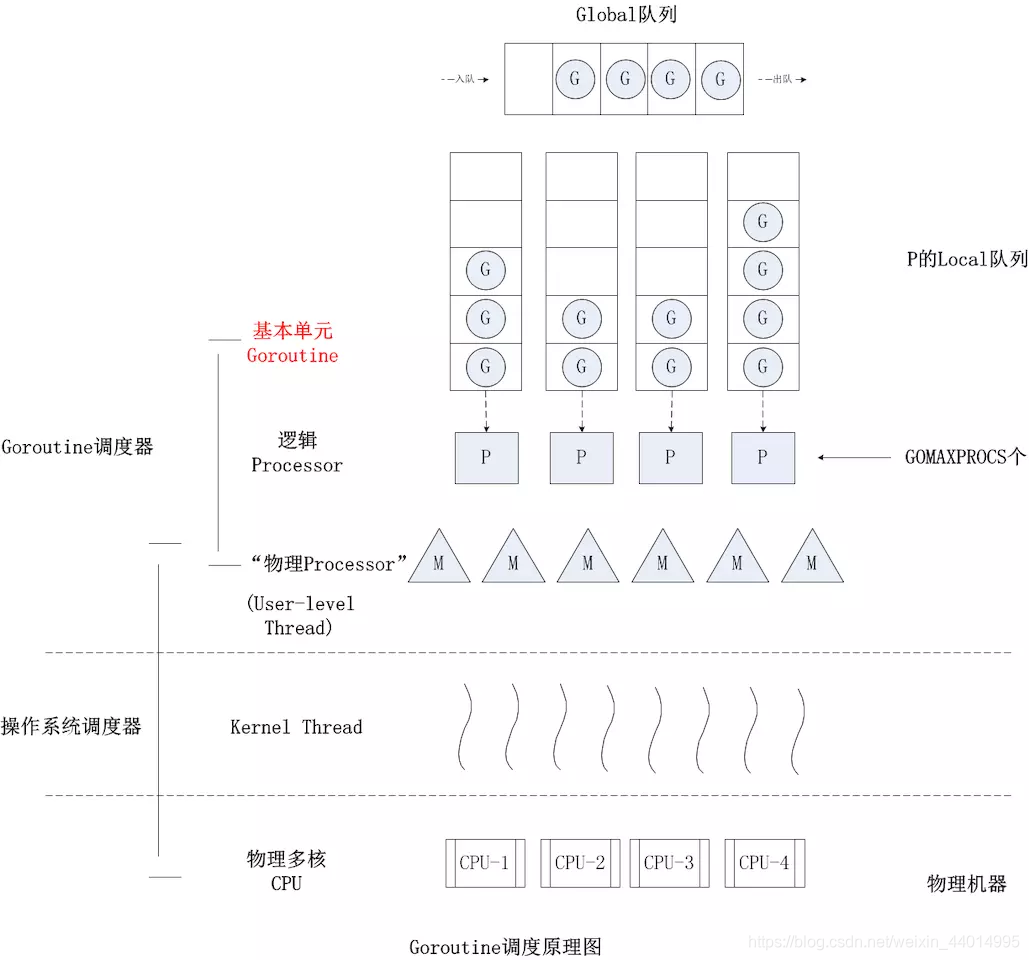
G-P-M 模型
G-P-M 模型是基于线程池演化而来:
把每个工作线程叫 worker 的话,每条线程运行一个 worker
每个 worker 做的事情就是不停地从队列中取出任务并执行
在 G-P-M 模型中:
G 就是我们需要完成的任务
M 就是一个 worker(一条线程)
Sched 相当于管理可运行 G 的全局任务队列(当然也包括了其他的辅助信息)
P 则是在 go-1.1 中才引入的内容,为了解决 G 阻塞导致的 M 资源浪费问题
G-P-M 模型图解:
G:goroutine 协程
通过 go 关键字创建,封装了所要执行的代码逻辑
属于用户级资源,对 OS 透明,具备轻量级,可以大量创建,上下文切换成本地等特点
P:Processor 逻辑处理器
默认 go 运行时的 Processor 数量等于 CPU 数量,也可以通过 GOMAXPROCS 函数指定 P 的数量
P 会从 Sched 中拿取 G 并加入自己的任务队列(在该任务队列中使用轻量级切换,不涉及内核),然后 P 将自己任务队列中的 G 交给 M 执行,一旦 G 阻塞,P 就会与 M 解除绑定,并寻找空闲的 M 继续执行任务队列中的 G,如果 P 中的任务队列全部执行完毕,则 P 会随机从其它 P 中窃取一半的可运行的 G
创建&销毁 goroutine
函数 runtime.newproc 会创建一个新的 G 结构体(核心工作由 runtime.newproc1 完成)
if readgstatus(newg) != _Gdead { throw("newproc1: new g is not Gdead") }
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame totalSize = alignUp(totalSize, sys.StackAlign) sp := newg.stack.hi - totalSize if usesLR { // caller's LR *(*uintptr)(unsafe.Pointer(sp)) = 0 prepGoExitFrame(sp) } if GOARCH == "arm64" { // caller's FP *(*uintptr)(unsafe.Pointer(sp - goarch.PtrSize)) = 0 }
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) newg.sched.sp = sp /* 将sp,pc等上下文环境保存在g的sched域 */ newg.stktopsp = sp newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn) newg.parentGoid = callergp.goid newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) newg.startpc = fn.fn if isSystemGoroutine(newg, false) { sched.ngsys.Add(1) } else { // Only user goroutines inherit pprof labels. if mp.curg != nil { newg.labels = mp.curg.labels } if goroutineProfile.active { // A concurrent goroutine profile is running. It should include // exactly the set of goroutines that were alive when the goroutine // profiler first stopped the world. That does not include newg, so // mark it as not needing a profile before transitioning it from // _Gdead. newg.goroutineProfiled.Store(goroutineProfileSatisfied) } } // Track initial transition? newg.trackingSeq = uint8(cheaprand()) if newg.trackingSeq%gTrackingPeriod == 0 { newg.tracking = true } gcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo)) /* 分配goroutine id */ // Get a goid and switch to runnable. Make all this atomic to the tracer. trace := traceAcquire() var status uint32 = _Grunnable if parked { status = _Gwaiting newg.waitreason = waitreason } casgstatus(newg, _Gdead, status) /* 将初始化完成的结构体G,挂到当前M的P的队列中 */ if pp.goidcache == pp.goidcacheend { // Sched.goidgen is the last allocated id, // this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch]. // At startup sched.goidgen=0, so main goroutine receives goid=1. pp.goidcache = sched.goidgen.Add(_GoidCacheBatch) pp.goidcache -= _GoidCacheBatch - 1 pp.goidcacheend = pp.goidcache + _GoidCacheBatch } newg.goid = pp.goidcache pp.goidcache++ newg.trace.reset() if trace.ok() { trace.GoCreate(newg, newg.startpc, parked) traceRelease(trace) }
// Set up race context. if raceenabled { newg.racectx = racegostart(callerpc) newg.raceignore = 0 if newg.labels != nil { // See note in proflabel.go on labelSync's role in synchronizing // with the reads in the signal handler. racereleasemergeg(newg, unsafe.Pointer(&labelSync)) } } releasem(mp)
return newg }
wakep 函数唤醒 P 时,调度器会试着寻找一个可用的 M 来绑定 P,必要的时候会新建 M,之后的调用链如下:
lasttrace := int64(0) idle := 0// how many cycles in succession we had not wokeup somebody delay := uint32(0)
for { if idle == 0 { // start with 20us sleep... delay = 20 } elseif idle > 50 { // start doubling the sleep after 1ms... delay *= 2 } if delay > 10*1000 { // up to 10ms delay = 10 * 1000 } usleep(delay)
// sysmon should not enter deep sleep if schedtrace is enabled so that // it can print that information at the right time. // // It should also not enter deep sleep if there are any active P's so // that it can retake P's from syscalls, preempt long running G's, and // poll the network if all P's are busy for long stretches. // // It should wakeup from deep sleep if any P's become active either due // to exiting a syscall or waking up due to a timer expiring so that it // can resume performing those duties. If it wakes from a syscall it // resets idle and delay as a bet that since it had retaken a P from a // syscall before, it may need to do it again shortly after the // application starts work again. It does not reset idle when waking // from a timer to avoid adding system load to applications that spend // most of their time sleeping. now := nanotime() if debug.schedtrace <= 0 && (sched.gcwaiting.Load() || sched.npidle.Load() == gomaxprocs) { lock(&sched.lock) if sched.gcwaiting.Load() || sched.npidle.Load() == gomaxprocs { syscallWake := false next := timeSleepUntil() if next > now { sched.sysmonwait.Store(true) unlock(&sched.lock) // Make wake-up period small enough // for the sampling to be correct. sleep := forcegcperiod / 2 if next-now < sleep { sleep = next - now } shouldRelax := sleep >= osRelaxMinNS if shouldRelax { osRelax(true) } syscallWake = notetsleep(&sched.sysmonnote, sleep) if shouldRelax { osRelax(false) } lock(&sched.lock) sched.sysmonwait.Store(false) noteclear(&sched.sysmonnote) } if syscallWake { idle = 0 delay = 20 } } unlock(&sched.lock) }
lock(&sched.sysmonlock) // Update now in case we blocked on sysmonnote or spent a long time // blocked on schedlock or sysmonlock above. now = nanotime()
// trigger libc interceptors if needed if *cgo_yield != nil { asmcgocall(*cgo_yield, nil) } // poll network if not polled for more than 10ms lastpoll := sched.lastpoll.Load() if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now { sched.lastpoll.CompareAndSwap(lastpoll, now) list, delta := netpoll(0) // non-blocking - returns list of goroutines if !list.empty() { // Need to decrement number of idle locked M's // (pretending that one more is running) before injectglist. // Otherwise it can lead to the following situation: // injectglist grabs all P's but before it starts M's to run the P's, // another M returns from syscall, finishes running its G, // observes that there is no work to do and no other running M's // and reports deadlock. incidlelocked(-1) injectglist(&list) incidlelocked(1) netpollAdjustWaiters(delta) } } if GOOS == "netbsd" && needSysmonWorkaround { // netpoll is responsible for waiting for timer // expiration, so we typically don't have to worry // about starting an M to service timers. (Note that // sleep for timeSleepUntil above simply ensures sysmon // starts running again when that timer expiration may // cause Go code to run again). // // However, netbsd has a kernel bug that sometimes // misses netpollBreak wake-ups, which can lead to // unbounded delays servicing timers. If we detect this // overrun, then startm to get something to handle the // timer. // // See issue 42515 and // https://gnats.netbsd.org/cgi-bin/query-pr-single.pl?number=50094. if next := timeSleepUntil(); next < now { startm(nil, false, false) } } if scavenger.sysmonWake.Load() != 0 { // Kick the scavenger awake if someone requested it. scavenger.wake() } // retake P's blocked in syscalls // and preempt long running G's if retake(now) != 0 { idle = 0 } else { idle++ } // check if we need to force a GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() { lock(&forcegc.lock) forcegc.idle.Store(false) var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now { lasttrace = now schedtrace(debug.scheddetail > 0) } unlock(&sched.sysmonlock) } }
如果检测到某个 P 的状态为 Prunning,并且它已经运行了超过10ms,则会将 P 的当前的 G 的 stackguard 设置为 StackPreempt
这个操作其实是相当于加上一个标记,通知这个 G 在合适时机进行调度
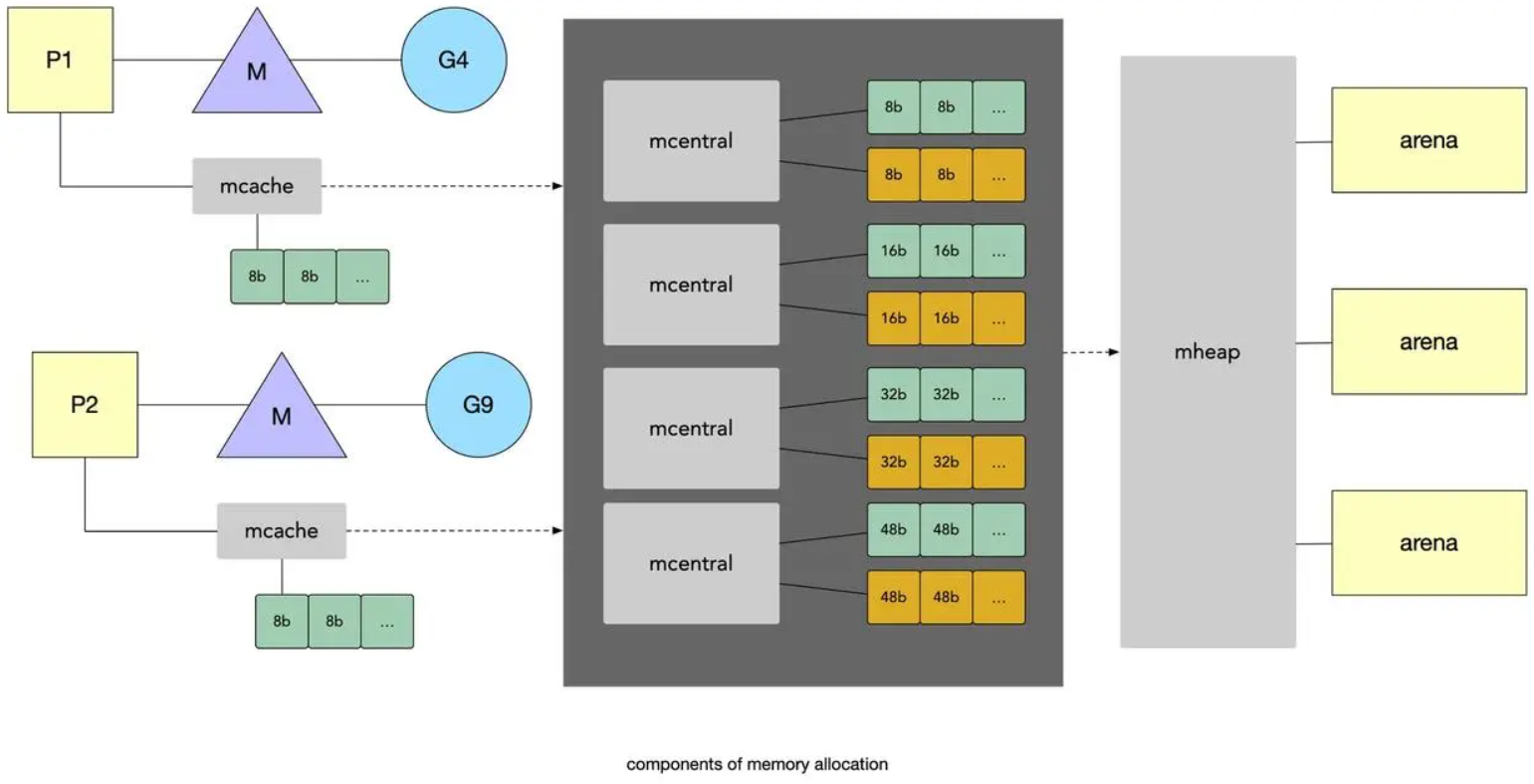
内存管理
go 是一门带垃圾回收的语言,go 内存管理机制主要有两个方面:
一个方面是内存池
一个方面是垃圾回收
内存池
go 的内存分配器采用了跟 tcmalloc 库相同的实现,是一个带内存池的分配器,底层直接调用操作系统的 mmap 等函数
type _func struct { sys.NotInHeap // Only in static data
entryOff uint32// start pc, as offset from moduledata.text/pcHeader.textStart nameOff int32// function name, as index into moduledata.funcnametab.
args int32// in/out args size deferreturn uint32// offset of start of a deferreturn call instruction from entry, if any.
pcsp uint32 pcfile uint32 pcln uint32 npcdata uint32 cuOffset uint32// runtime.cutab offset of this function's CU startLine int32// line number of start of function (func keyword/TEXT directive) funcID abi.FuncID // set for certain special runtime functions flag abi.FuncFlag _ [1]byte// pad nfuncdata uint8// must be last, must end on a uint32-aligned boundary
// The end of the struct is followed immediately by two variable-length // arrays that reference the pcdata and funcdata locations for this // function.
// pcdata contains the offset into moduledata.pctab for the start of // that index's table. e.g., // &moduledata.pctab[_func.pcdata[_PCDATA_UnsafePoint]] is the start of // the unsafe point table. // // An offset of 0 indicates that there is no table. // // pcdata [npcdata]uint32
// funcdata contains the offset past moduledata.gofunc which contains a // pointer to that index's funcdata. e.g., // *(moduledata.gofunc + _func.funcdata[_FUNCDATA_ArgsPointerMaps]) is // the argument pointer map. // // An offset of ^uint32(0) indicates that there is no entry. // // funcdata [nfuncdata]uint32 }