沙盒基础知识
在 CTF 的 pwn 题中一般有两种函数调用方式实现沙盒机制:
使用 prctl 系统调用:
1 |
|
1 | 0000: 0x20 0x00 0x00 0x00000000 A = sys_number |
使用 seccomp 库函数:
1 |
|
1 | 0000: 0x20 0x00 0x00 0x00000004 A = arch |
- 对
seccomp_load函数进行逆向分析,可以发现其底层也是使用prctl系统调用
1 | v17 = prctl(38LL, 1LL, 0LL, 0LL, 0LL); /* PR_SET_NO_NEW_PRIVS */ |
1 | v14 = prctl(22LL, 2LL, v10, v10, v7); /* PR_SET_SECCOMP */ |
prctl 系统调用
prctl(Process Control Language,进程控制语言)是一个 Linux 系统调用的一个重要工具,它可以对进程进行各种管理和控制操作
prctl 提供了对进程的许多控制和设置,使用第一个参数来指定其功能:
- 设置进程的权限级别
- 设置进程的调度参数
- 设置进程的内存限制
- 设置进程的 CPU 时间限制
- 设置进程的信号处理
- 设置进程的资源限制
- 设置进程的属性
- 获取进程的属性
沙盒需要的 prctl 功能如下:
prctl(PR_SET_NO_NEW_PRIVS):命名空间内以CAP_SYS_ADMIN权限运行(子进程会保证不会赋予运行进程新的权限)prctl(PR_SET_SECCOMP):第二个参数是设置的过滤模式,第三个参数是设置的过滤规则
1 | SYSCALL_DEFINE5(prctl, int, option, unsigned long, arg2, unsigned long, arg3, |
核心函数 prctl_set_seccomp 的调用链如下:
1 | long prctl_set_seccomp(unsigned long seccomp_mode, void __user *filter) |
1 | static long do_seccomp(unsigned int op, unsigned int flags, |
这里我们重点分析过滤模式的 seccomp_set_mode_filter 函数:
1 | static long seccomp_set_mode_filter(unsigned int flags, |
- 其最核心的工作就是在
current->seccomp.filter中注册过滤器:
1 | filter->prev = current->seccomp.filter; |
如果使用了 FILTER 模式,则调用 seccomp_run_filters 函数来进行所有指令判断过滤,系统调用号作为参数传递,根据返回值来进行后续处理
这里我们分析一下从 syscall 入口函数 entry_SYSCALL_compat 到 seccomp_run_filters 的调用链:
1 | SYM_CODE_START(entry_SYSCALL_compat) |
1 | static noinstr bool __do_fast_syscall_32(struct pt_regs *regs) |
1 | long syscall_enter_from_user_mode_work(struct pt_regs *regs, long syscall) |
1 | static __always_inline long |
1 | static long syscall_trace_enter(struct pt_regs *regs, long syscall, |
1 | int __secure_computing(const struct seccomp_data *sd) |
1 | static int __seccomp_filter(int this_syscall, const struct seccomp_data *sd, |
指令过滤函数 seccomp_run_filters 的源码如下:
1 | static u32 seccomp_run_filters(const struct seccomp_data *sd, |
bpf_prog_run_pin_on_cpu是一个用于运行 BPF 程序的函数,该函数将 BPF 程序加载到指定 CPU 的内存中,并将其附加到指定 CPU 的运行队列中
1 | static inline u32 bpf_prog_run_pin_on_cpu(const struct bpf_prog *prog, |
eBPF 虚拟机
Linux 下 eBPF 的整体架构如下图所示:
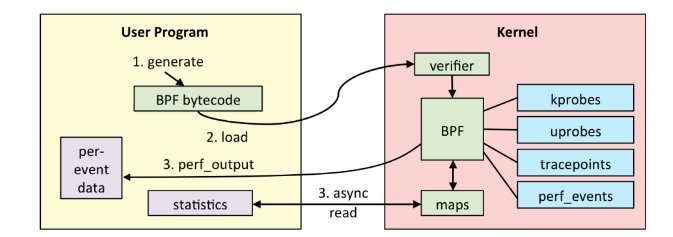
- 传入:用户进程首先在用户空间编写相应的 BPF 字节码程序,传入内核
- 检查:内核通过
verifier对字节码程序进行安全性检查 - 编译 or 解释:通过检查后便通过 JIT 编译运行,或者直接解释运行 BPF 字节码
- 映射:用以保存数据的通用结构,可以在不同的 eBPF 程序之间或是用户进程与内核间共享数据(不同的 eBPF 程序之间可以共享同一个映射)
eBPF 底层是一个使用 RISC 指令集的虚拟机,使用11个64位寄存器和一个固定大小为512字节的栈:
- 其中9个寄存器是通用寄存器
- 一个只读栈帧寄存器
寄存器总是64位大小,在32位机器上会默认把前32位置零,这也为 eBPF 提供了交叉编译的兼容性,各个寄存器的功能如下:
- R0: RAX,存放函数返回值或程序退出状态码
- R1: RDI,第一个实参
- R2: RSI,第二个实参
- R3: RDX,第三个实参
- R4: RCX,第四个实参
- R5: R8,第五个实参
- R6: RBX,callee saved
- R7: R13,callee saved
- R8: R14,callee saved
- R9: R15,callee saved
- R10: RBP,只读栈帧
在 eBPF 中,一个寄存器的状态信息使用 bpf_reg_state 进行表示:
1 | struct bpf_reg_state { |
当 eBPF 字节码载入到内核中后,verifier 会对 eBPF 字节码进行一系列的检查,主要关注以下几个字段:
smin_value、smax_value:64 位有符号的值的可能取值边界umin_value、umax_value:64 位无符号的值的可能取值边界s32_min_value、s32_max_value:32 位有符号的值的可能取值边界u32_min_value、u32_max_value:32 位无符号的值的可能取值边界
核心检查函数就是 bpf_check,一个静态代码分析器:
- 逐条遍历 eBPF 程序中的指令并更新寄存器 / 堆栈的状态,条件分支的所有路径都会被分析,直到
bpf_exit指令 - 这其实是一个模拟执行的过程,verifier 会推测寄存器的边界值,检查其是否符合规则
- 模拟通过后才能正常加载 eBPF 程序
在其中用于检测指令合法性的函数为 do_check,该函数会遍历每一条指令并根据指令的不同类型进行不同操作,对于算术指令(BPF_ALU / BPF_ALU64)而言有如下调用链
1 | do_check() // 遍历每一条指令并根据类型调用相应函数处理 |
当 eBPF 字节码载入到内核中后,内核最终会使用一个 bpf_prog 结构体来表示一个 eBPF 程序:
1 | struct bpf_prog { |
接着就是编译,解释 eBPF 字节码,生成 bpf map 并记录在 bpf_reg_state->map_ptr 中
bpf map 是一个通用的用以储存不同种类数据的结构,用以在用户进程与 eBPF 程序、eBPF 程序与 eBPF 程序之间进行数据共享(这些数据以二进制形式储存,因此用户在创建时只需要指定 key 与 value 的 size)
核心结构体 bpf_map 如下:
1 | struct bpf_map { |
bpf map 有多种类型,记录于 bpf_map_type 枚举中:
1 | enum bpf_map_type { |
Seccomp BPF
柏克莱封包过滤器(Berkeley Packet Filter,缩写 BPF),是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发,除此之外,如果网卡驱动支持洪泛模式,那么它可以让网卡处于此种模式,这样可以收到网络上的所有包,不管他们的目的地是不是所在主机
Seccomp BPF 是一种基于 Linux 内核的 BPF 过滤器,用于对 Linux 进程的系统调用进行过滤和拦截(eBPF 的一部分)
BPF 的指令集比较简单,开发人员定义了符号常量和两个方便的宏 BPF_STMT 和 BPF_JUMP 可以用来方便的编写 BPF 规则
1 | BPF_STMT(BPF_LD | BPF_W | BPF_ABS,(offsetof(struct seccomp_data, arch))) |
BPF_LD:建一个 BPF 加载操作BPF_W:操作数大小是一个字BPF_ABS:使用绝对偏移,即使用指令中的值作为数据区的偏移量,该值是体系结构字段与数据区域的偏移量offsetof():生成数据区域中期望字段的偏移量
1 | BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K ,AUDIT_ARCH_X86_64 , 1, 0) |
BPF_JMP | BPF JEQ会创建一个相等跳转指令,它将指令中的值(即第二个参数)与累加器中的值(BPF_K)进行比较,判断是否相等- 如果架构是则跳过下一条指令(jt=1,代表测试为真,跳过一条指令)
- 否则将执行下一条指令(jf=0,代表测试为假,继续执行下一条指令)
用户编写的 eBPF 程序最终会被编译成 eBPF 字节码,eBPF 字节码使用 bpf_insn 结构来表示,如下:
1 | struct bpf_insn { |
eBPF 程序会被 LLVM/Clang 编译成 bpf_insn 结构数组,这里使用了 JIT 即时编译技术(PS:当 eBPF 字节码被加载到内核时,内核会根据是否开启了 JIT 功能选项,来决定是否将 eBPF 字节码编译成机器码)
内核通过 bpf_prog_load 函数来加载 eBPF 字节码
1 | static int bpf_prog_load(union bpf_attr *attr, union bpf_attr __user *uattr) |
- 函数
bpf_prog_load会调用bpf_prog_select_runtime函数来判断是否使用 JIT
1 | struct bpf_prog *bpf_prog_select_runtime(struct bpf_prog *fp, int *err) |
- 对于不同的架构,函数
bpf_int_jit_compile有不同的实现 - 这里我们只分析 x86_64 架构下的
bpf_int_jit_compile:
1 | struct bpf_prog *bpf_int_jit_compile(struct bpf_prog *prog) |
当函数 do_jit 将 eBPF 码编译为字节码后,可以直接调用 prog->bpf_func 来执行字节码
当内核要执行 eBPF 字节码时,会调用原本位于 prog->bpf_func 的函数 __bpf_prog_run,该函数是 BPF 的核心函数入口,该函数被多个不同 stack size 的函数调用:
1 | static u64 ___bpf_prog_run(u64 *regs, const struct bpf_insn *insn, u64 *stack) |