第一个任务
任务目标:
- 定义一个待实现编译器的语言,用上下文无关文法定义该语言
- 写出10个该语言编写的程序样例(覆盖所有文法规则),用于后续测试
- 给该语言起一个名称
上下文无关文法 CFG(Context Free Grammar)是一组替换规则,描述了语句是如何形成
CFG 主要作用是验证一个输入字符串 input 是否符合某个文法 G(与正则表达式比较像,但是比正则表达式功能更强大)
具体的语法细节本人没有详细地了解过,下面给出一个简化的C语言的文法:
1 | G[program]: |
- 名称为 mini-c
第二个任务
- 构建词法、语法分析器
- 用测试样例覆盖所有文法规则
- 能检出10个不同的词法错误
- 具有错误恢复功能,能检出10个不同的语法错误,并提示行号
- 对正确的样例,输出其语法树
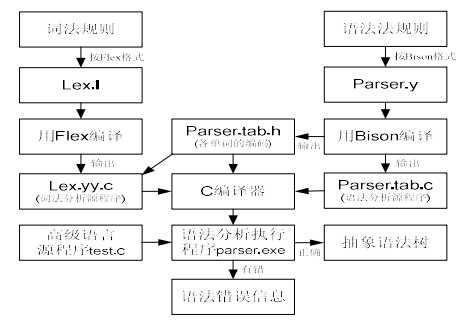
工具 Flex 和 Bison
Flex 是一个生成词法分析器的工具,利用 Flex,我们只需提供词法的正则表达式,就可自动生成对应的C代码
Bison 是一种通用解析器生成器,它将带注释的上下文无关文法转换为使用 LALR(1) 解析器表的确定性 LR 或广义 LR(GLR)解析器
通过联合使用 Flex 和 Bison 来构造词法、语法分析程序,大致流程如下:
词法分析
核心步骤:
- 设计能准确表示各类单词的正则表达式
- 用正则表达式表示的词法规则等价转化为相应的有限自动机 FA
- 将其确定化、最小化,最后依据这个 FA 编写对应的词法分析程序
高级语言的词法分析器,需要识别的单词有五类:
- 关键字(保留字),运算符,界符,常量,标识符
依据 mini-c 语言的定义,下面给出各单词的种类码和相应符号说明:
1 | INT → 整型常量 |
- 这里有关的单词种类码:
INT,FLOAT,......,WHILE每一个对应一个整数值作为其单词的种类码 - 实现时不需要自己指定这个值,当词法分析程序生成工具 Flex 和语法分析程序生成器 Bison 联合使用时,将这些单词符号以 %token 的形式在 Bison 的文件
parser.y中罗列出来,就可生成头文件parser.tab.h,以枚举常量的形式给这些单词种类码进行自动编号
在编写 Flex 文件之前,需要先了解 Flex 的文件格式:
1 | 定义部分 |
- Flex 文件是文件扩展名为
.l的文本文件 - 定义部分:
- 主要包含c语言的一些宏定义,如文件包含、宏名定义,以及一些变量和类型的定义和声明
- 规则部分:
- 由规则
正规表达式 动作组成 - 词法分析器一旦识别出正规表达式所对应的单词,就会执行动作所对应的操作,返回单词的种类码(常规操作:把读取到的单词以各种形式保存在联合变量 YYLVAL 中)
- 词法分析器识别出一个单词后,会将该单词保存在
yytext中,其长度为yyleng
- 由规则
- 用户子程序部分:
- 这部分代码会原封不动的被复制到词法分析器源程序
lex.yy.c中
- 这部分代码会原封不动的被复制到词法分析器源程序
实现代码如下:
1 | /* yylineno记录行号 */ |
语法分析
语法分析采用生成器自动化生成工具 GNU Bison(前身是 YACC),该工具采用了 LALR(1) 的自底向上的分析技术,完成语法分析
在编写 Bison 文件之前,需要先了解 Bison 的文件格式:
1 | { |
Bison 文件是文件扩展名为
.y的文本文件声明部分:
- 包含语法分析中需要的头文件包含,宏定义和全局变量的定义等,这部分会直接被复制到语法分析的C语言源程序中
辅助定义部分:
- 语义值的类型定义
- 非终结符的属性值类型说明(非终结符:不是终结符的都是非终结符)
- 终结符语义值类型定义(终结符:不能单独出现在推导式左边的符号)
- 优先级与结合性定义
规则部分:
采用 LR 分析法,需要在每条规则后给出相应的语义动作,例如:
规则:
Exp → Exp = Exp语义动作:
Exp: Exp ASSIGNOP Exp {$$=mknode(ASSIGNOP,$1,$3,NULL,yylineno); }
用户子程序部分:
- 这部分代码会原封不动的被复制到词法分析器源程序
lex.yy.c中
- 这部分代码会原封不动的被复制到词法分析器源程序
语法分析的过程比较复杂,先看一个案例:
calc.l:Flex 文件
1 | %{ |
- 使用正则匹配数字,将目标数字存储于
yylval中并返回 T_NUM - 使用正则匹配符号,并返回该符号(
yytext[0])
calc.y:Bison 文件
1 | %{ |
- 规则后面
{}中的是当完成归约时要执行的语义动作 - 规则左部的E的属性值用$$表示,右部有2个E,其属性值分别用$1和$3表示
- 例如:
A : B '+' C {$$ = $1 + $3;} - $$ 代指 A
- $1 代指 B
- $2 代指 +
- $3 代指 C
- 例如:
效果如下:
1 | bison -d -v calc.y |
1 | ➜ demo ./calc |
Bison 的规则部分非常复杂,总计为以下条目指定了规则:
ExtDefList-外部定义列表:即是整个语法树
1 | ExtDefList: {$$=NULL;} |
- mknode:生成一个非叶子树结点(第1个参数代表节点的类型,第2-4个参数代表该节点的子树,第5个参数代表行号)
- 对于每个 EXTDEFLIST 有2种可能:
- 外部定义列表为 NULL
- 外部定义列表不为 NULL,则创建 EXT_DEF_LIST 结点
- 对于每个 EXT_DEF_LIST 节点有2个子树:
- 第1个子树对应声明 ExtDef(声明变量,声明数组,声明函数)
- 第2个子树对应它自身 ExtDefList
- 代表多个声明 ExtDef(
A : B A {...}这种写法代表存在多个B)
ExtDef-声明:声明变量,声明数组,声明函数
1 | ExtDef: Specifier ExtDecList SEMI {$$=mknode(EXT_VAR_DEF,$1,$2,NULL,yylineno);} |
- 对于每个 ExtDef 有4种可能:
- 对应外部变量声明,生成 EXT_VAR_DEF 节点
- 对应数组声明,生成 ARRAY_DEF 节点
- 对应函数声明,生成 FUNC_DEF 节点
- 对应报错
- EXT_VAR_DEF,ARRAY_DEF,FUNC_DEF 节点的信息如上
Specifier-类型:表示一个类型 (int,float)
1 | Specifier: TYPE {$$=mknode(TYPE,NULL,NULL,NULL,yylineno);strcpy($$->type_id,$1);$$->type=(!strcmp($1,"int")?INT:(!strcmp($1,"float")?FLOAT:CHAR));} |
- 对于每个 Specifier 有1种可能:
- 对应类型,生成 TYPE 节点
- TYPE 节点无子树
ExtDecList-变量名称列表:由一个或多个变量组成,多个变量之间用逗号隔开
1 | ExtDecList: VarDec {$$=$1;} |
- 对于每个 EXT_DECLIST 有2种可能:
- 只有一个变量,则直接赋值 VarDec 变量
- 有多个变量,则生成 EXT_DEC_LIST 节点
- 对于每个 EXT_DEC_LIST 结点有2个子树:
- 第1个子树对应变量 VarDec
- 第2个子树对应它自身 ExtDecList
- 代表多个变量 VarDec
VarDec-变量名称:由一个 ID 组成
1 | VarDec: ID {$$=mknode(ID,NULL,NULL,NULL,yylineno);strcpy($$->type_id,$1);} // ID结点,标识符符号串存放结点的type_id |
- 对于每个 VarDec 有1种可能:
- 由一个 ID 组成,则生成 ID 节点
- ID 节点无子树
FuncDec-函数声明:包括函数名和参数定义
1 | FuncDec: ID LP VarList RP {$$=mknode(FUNC_DEC,$3,NULL,NULL,yylineno);strcpy($$->type_id,$1);} // 函数名存放在$$->type_id |
- 函数名 ID 存放在
$$->type_id - 对于每个 FuncDec 有3种可能:
- 对应一个带参数的函数,则生成 FUNC_DEC 节点(带参)
- 对应一个不带参数的函数,则生成 FUNC_DEC 节点(不带参)
- 对应报错
- 对于每个 FUNC_DEC 结点有1个子树或者无子树:
- 第1个子树对应参数定义列表 VarDec
ArrayDec-数组声明
1 | ArrayDec: ID LB Exp RB {$$=mknode(ARRAY_DEC,$3,NULL,NULL,yylineno);strcpy($$->type_id,$1);} |
- 对于每个 ArrayDec 有3种可能:
- 对应静态数组,则生成 ARRAY_DEC 节点(带有表达式 Exp)
- 对应动态数组,则生成 ARRAY_DEC 节点
- 对应报错
- 对于每个 ARRAY_DEC 结点有1个子树或者无子树:
- 第1个子树对应表达式 Exp
VarList-参数定义列表:由一个到多个参数定义组成,用逗号隔开
1 | VarList: ParamDec {$$=mknode(PARAM_LIST,$1,NULL,NULL,yylineno);} |
- 对于每个 VarList 有2种可能:
- 对应一个参数 ParamDec,则生成 PARAM_LIST 节点
- 对应用逗号隔开的多个参数 ParamDec,则生成 PARAM_LIST 节点
- 对于每个 PARAM_LIST 结点有1个或2个子树:
- 第1个子树对应参数定义 ParamDec
- 第2个子树对应它自身 PARAM_LIST
ParamDec-参数定义:固定由一个类型和一个变量组成
1 | ParamDec: Specifier VarDec {$$=mknode(PARAM_DEC,$1,$2,NULL,yylineno);} |
- 对于每个 ParamDec 有1种可能:
- 对应一个类型 Specifier 和一个变量 VarDec,则生成 PARAM_DEC 节点
- 对于每个 PARAM_DEC 节点有2个子树:
- 第1个子树对应类型 Specifier
- 第2个子树对应一个变量 VarDec
CompSt-复合语句:左右分别用大括号括起来,中间有定义列表和语句列表
1 | CompSt: LC DefList StmList RC {$$=mknode(COMP_STM,$2,$3,NULL,yylineno);} |
- 对于每个 CompSt 有2种可能:
- 对应一个由
{}包裹起来的子语句,则生成 COMP_STM 节点 - 对应报错
- 对应一个由
- 对于每个 COMP_STM 节点有2个子树:
- 第1个子树对应定义列表 DefList
- 第2个子树对应语句列表 StmList
StmList-语句列表:由“0”个或多个语句 Stmt 组成
1 | StmList: {$$=NULL;} |
- 对于每个 StmList 有2种可能:
- 对应 NULL
- 对应多个语句 Stmt,则生成 STM_LIST 节点
- 对于每个 STM_LIST 节点有2个子树:
- 第1个子树对应语句 Stmt
- 第2个子树对应它自身 StmList
Stmt-语句:可能为表达式,复合语句,return 语句,if 语句,if-else 语句,while 语句,for 语句
1 | Stmt: Exp SEMI {$$=mknode(EXP_STMT,$1,NULL,NULL,yylineno);} |
- 对于每个 Stmt 有7种可能:
- 对应基础表达式 Exp,则生成节点 EXP_STMT
- 对应符合语句 CompSt
- 对应 RETURN Exp,则生成节点 RETURN
- 对应 IF ELSE-IF 语句,则生成节点 IF_THEN
- 对应 IF ELSE 语句,则生成节点 IF_THEN_ELSE
- 对应 WHILE 语句,则生成节点 WHILE
- 对应 FOR 语句,则生成节点 FOR
DefList-定义列表:由“0”个或多个定义语句组成
1 | DefList: {$$=NULL; } |
- 对于每个 DefList 有2种可能:
- 对应 NULL
- 对应多个定义 Def,则生成 DEF_LIST 节点
Def-定义:定义一个或多个定义语句,由分号隔开
1 | Def: Specifier DecList SEMI {$$=mknode(VAR_DEF,$1,$2,NULL,yylineno);} |
- 对于每个 Def 有2种可能:
- 对应变量的定义,则生成 VAR_DEF 节点
- 对应数组的定义,则生成 ARRAY_DEF 节点
DecList-语句列表:由一个或多个语句组成,由逗号隔开,最终都成一个表达式
1 | DecList: Dec {$$=mknode(DEC_LIST,$1,NULL,NULL,yylineno);} |
- 对于每个 DecList 有2种可能:
- 对应一个语句 Dec,则生成 DEC_LIST 节点
- 对应用逗号隔开的多个 Dec,则生成 DEC_LIST 节点
Dec-语句:一个变量名称或者一个赋值语句(变量名称等于一个表达式)
1 | Dec: VarDec {$$=$1;} |
- 对于每个 Dec 有2种可能:
- 对应一个变量名称 VarDec
- 对应一个赋值语句,则生成 ASSIGNOP 节点
Exp-表达式:代表数字或是数字之间的运算,和函数调用
1 | Exp: Exp ASSIGNOP Exp {$$=mknode(ASSIGNOP,$1,$3,NULL,yylineno);strcpy($$->type_id,"ASSIGNOP");} // $$结点type_id空置未用,正好存放运算符 |
- 对于每个 Exp 有23种可能:
- 前10种可能分别对应:等于 ASSIGNOP,和 AND,或 OR,二元运算符 RELOP,加 PLUS,减 MINUS,乘 STAR,除 DIV,加等于 COMADD,减等于 COMSUB,都会生成对应的节点
- 第11种可能分别对应:左右括号
- 第12,13种可能分别对应:负操作和非操作,分别生成 UMINUS 和 NOT 节点
- 第14-17种可能分别对应:加加 AUTOADD 和减减 AUTOSUB 的左右操作,分别生成4种类型的节点
- 第18,19种可能对应:函数的有参调用和无参调用,都生成 FUNC_CALL 节点
- 最后4种可能对应:ID,INT,FLOAT,CHAR
Args-用逗号隔开的参数(和参数定义 ParamDec 不同)
1 | Args: Exp COMMA Args {$$=mknode(ARGS,$1,$3,NULL,yylineno);} |
- 参数 Args 只在函数调用时使用
- 对于每个 Args 有2种可能:
- 对应用逗号隔开的多个 Exp
- 对应一个 Exp
实现代码如下:
1 | %define parse.error verbose // 指示bison生成详细的错误消息 |
生成抽象语法树
AST 不同于推导树,去掉了一些修饰性的单词部分,简明地把程序的语法结构表示出来,后续的语义分析、中间代码生成都可以通过遍历抽象语法树来完成
其实在语法分析的过程中,已经调用了可视化抽象语法树的函数 display:
1 | program: ExtDefList { display($1,0);} /* 归约到program,显示语法树(display是自己实现的,用于可视化AST的函数) */ |
它的实现如下:
1 | void display(struct node* T,int indent){ |
- 其实就是根据不同的节点来进行不同的操作
在语法分析中使用的,用于创建新节点的函数 mknode 的实现如下:
1 | struct node *mknode(int kind,struct node *first,struct node *second, struct node *third,int pos ){ |
编译与结果
编译命令:
1 | flex lexer.l # 生成lexer.yy.c |
测试文件:
1 | int a,b,c;//可改错误1:缺少分号 |
最终结果:
1 | ➜ exercise-1 ./test1 test.c |