知识图谱实践项目一
这几天都在学习知识图谱的相关技术
本篇博客先简述知识图谱的相关知识,然后分析一个我自己写的 Demo
知识图谱基础知识
知识图谱是一种结构化的知识表示方法,相比于文本更易于被机器查询和处理
知识图谱的构建是一个浩大的工程,从大方面来讲,分为 知识获取、知识融合、知识验证、知识计算和应用 几个部分
数据支持层:选什么样的数据库以及怎么设计 schema(模式)
- 关系数据库
- NoSQL 数据库
- 内存数据库
- mongo 数据库(一种分布式数据库)
- 图数据库(Neo4J)
知识抽取层:对不同种类的数据用不同的技术提取
- 从结构化数据库中获取知识:D2R
- 从链接数据中获取知识:图映射
- 从半结构化(网站)数据中获取知识:使用包装器
- 从纯文本中获取知识:信息抽取(包括:实体识别、实体链接、实体关系识别、概念抽取)
知识融合层:将不同数据源获取的知识进行融合构建数据之间的关联
- 实体对齐
- 属性对齐
- 冲突消解
- 规范化
知识验证层:分为 补全、纠错、外链、更新 各部分,确保知识图谱的 一致性和准确性
知识计算和应用:
- 本体或者规则推理:技术可以获取数据中存在的隐含知识
- 链接预测:预测实体间隐含的关系
- 社区计算:在知识网络上计算获取知识图谱上存在的社区,提供知识间关联的路径……
- 知识计算知识图谱:可以产生大量的智能应用如专家系统、推荐系统、语义搜索、问答等
知识图谱项目
本项目就只有两个部分:
- 爬虫(使用
requests模块 + 正则表达式) - 知识图谱(使用 Neo4J 数据库)
爬虫
爬虫的目标网站为 https://down.ali213.net/pcgame
简单 F12 分析一下,然后直接正则匹配就好(我个人比较喜欢用 .*? 进行匹配)
- 请求头的信息可以抓包查看
有一个需要注意的点就是中文乱码问题,在 Python 使用如下代码来查看网页 html 的编码方式
1 | def test(self): |
1 | ISO-8859-1 |
最后把爬取的信息存储在文件中
爬虫的代码如下:
1 | # -*- coding: utf-8 -*-# |
知识图谱
我自己实现的知识图谱比较简单,其核心思想就是:读取爬取的数据,将其格式化为 Cypher 后发送给 Neo4j
- 刚开始时不了解 Cypher 的语法,遇到了很多问题:
- 匹配不到节点
- 删除重复节点
- 删除重复关系
- 不过这些问题在网上都有解决的办法
本知识图谱有两个主体 游戏名称 游戏标签,两者用 分类 关系进行连接
建立 游戏名称 节点时不用特殊处理,因为在爬虫爬取的过程中就不会有重复,但 游戏标签 中存在大量的重复,简单遍历后去重很影响效率,于是我就把 “建立节点” 和 “建立关系” 这两步给分开了:
- “建立关系” 的过程很依赖数据在文本中的位置(爬取时就从上往下存放数据)
- 先遍历文本并用列表记录 “存在的节点”,转化为 Cypher 后创建
游戏标签节点 - 然后再次遍历该文本来 “建立关系”
知识图谱的代码如下:
1 | # -*- coding: utf-8 -*-# |
最后到达的效果如下图:
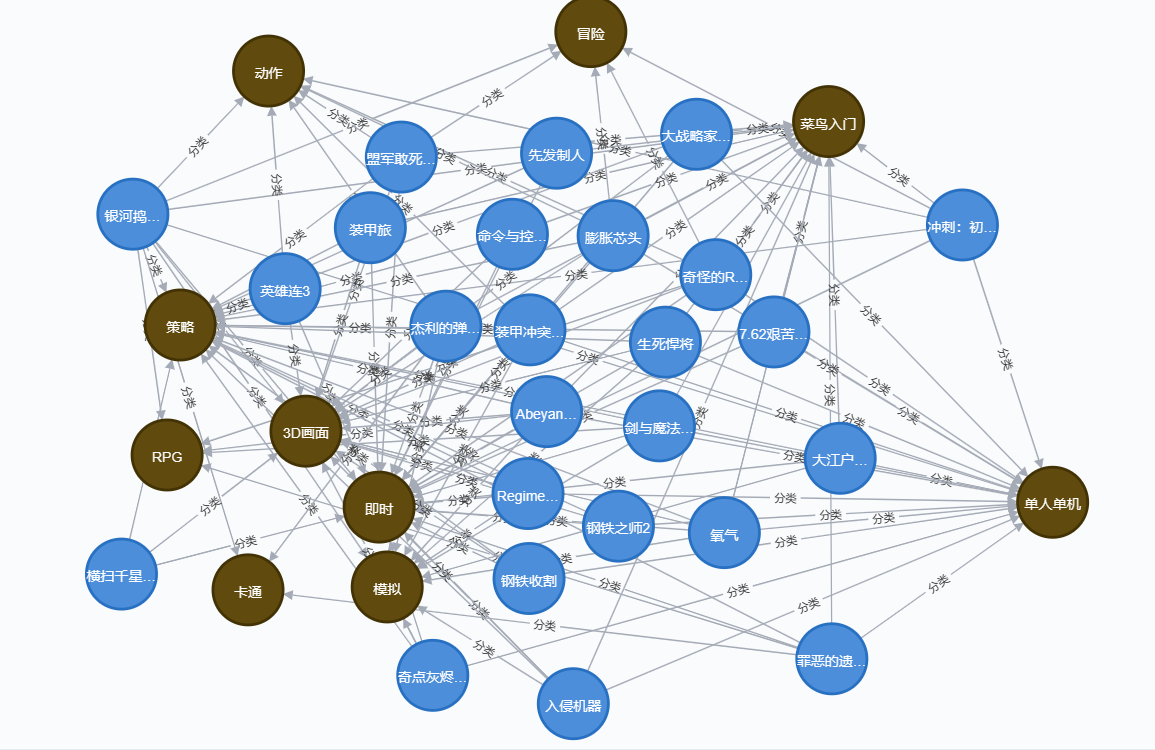
- 只放了部分(总共有:300 个
游戏名称节点,70 个游戏标签节点,17527 个关系)
个人感觉本项目在爬虫上下足了功夫,得到的虽然不是结构化的数据但非常好处理,于是省去了后续的 知识抽取 知识融合 知识验证
目前还没有学习图神经网络,基于知识图谱的应用(专家系统、推荐系统、语义搜索、问答…)暂时无法完成,之后有机会进行补充