基础知识
虚拟机是一种类似于计算机的程序。它模拟CPU和其他一些硬件组件,允许它执行算术,读写内存,并与I/O设备交互,就像物理计算机一样
虚拟机的核心功能是:理解一种可以用来编程的机器语言
- 编译器可以通过将标准高级语言编译为多个 CPU 体系结构来解决类似的问题
- VM 创建一个标准 CPU 体系结构,该体系结构在各种硬件设备上进行模拟
- 编译器的一个优点是它没有运行时开销,而 VM 有
- 尽管编译器做得很好,但编写面向多个平台的新编译器非常困难,因此 VM 在这里仍然很有帮助(实际上,VM 和编译器在不同级别混合使用)
虚拟机的其他运用:
- 垃圾收集:在 C 或 C++ 之上实现自动垃圾回收没有简单的方法,因为程序看不到自己的堆栈或变量,但是虚拟机位于其正在运行的程序的“外部”,可以观察堆栈上的所有内存引用
- 安全隔离:智能合约是由区块链网络中的每个验证节点执行的小程序,这要求节点操作员在他们的机器上运行由完全陌生的程序,为了防止合约执行恶意操作,所有合约都在无法访问文件系统、网络、磁盘等的VM中运行
在真实机器中,二进制代码是由具体的硬件来执行的,而虚拟机则是用其他语言模拟了这个过程,使该二进制代码可以在虚拟机的控制下执行
LC-3架构
LC-3 与 x86 相比,它具有简化的指令集,但包含现代 CPU 中使用的所有主要思想
- LC-3 有 65536 个内存位置(可由16位无符号整数寻址的最大位置),每个位置存储一个16位值,这意味着它总共只能存储128KB
- LC-3 总共有10个寄存器,每个寄存器为16位:
- 8个通用寄存器 - R0 - R7
- 1个程序计数器 - PC
- 1个条件标志寄存器 - COND
1 | enum |
1 | uint16_t reg[R_COUNT]; |
- LC-3 中只有16个操作码,计算机可以计算的所有内容都是这些简单指令的某个序列,每条指令的长度为16位,剩下的4位存储操作码,其余位用于存储参数
1 | enum |
- LC-3 仅使用3个条件标志,用于指示先前计算的符号
1 | enum |
Assembly examples 装配示例
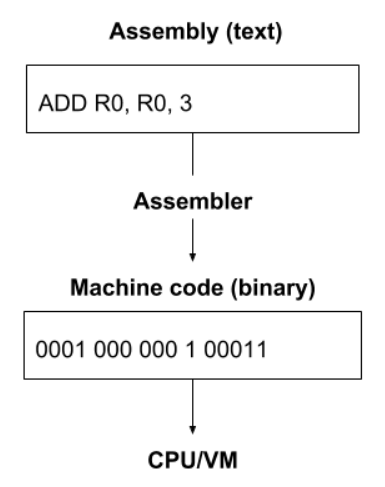
现在,让我们看一个 LC-3 汇编程序,以了解 VM 实际运行的内容,您不需要知道如何对装配进行编程或了解正在发生的一切,只是试着大致了解正在发生的事情:
1 | .ORIG x3000 ; 这是内存中将加载程序的地址 |
- 程序从顶部开始,一次执行一个语句
请注意,某些语句的名称与我们之前定义的操作码匹配,之前,我们了解到每条指令都是16位,但每行看起来都是不同数量的字符
- 这是因为我们正在阅读的代码是用汇编编写的,汇编是人类可读和可写的形式,以纯文本编码
- 称为汇编器的工具用于将每行文本转换为 VM 可以理解的16位二进制指令
- 这种二进制形式本质上是一个16位指令数组,称为机器代码,是 VM 实际运行的内容
Executing programs 程序执行
虚拟机执行的流程为:
- 从 PC 寄存器地址的内存中加载一条指令
- 递增 PC 寄存器
- 查看操作码以确定它应该执行哪种类型的指令
- 使用指令中的参数执行指令
- 返回到第一步
main 函数整体的构建为:
1 | int main(int argc, const char* argv[]) |
- 先读取传入 VM 的参数(一个文件的路径)
- 打开这个文件,并把里面的指定数据传输到 VM 私有内存
- 设置好 PC 寄存器,然后在循环中分析并执行二进制代码
- 执行完毕后退出
指令 ADD:
- 指令 ADD 需要两个数字,将它们相加,并将结果存储在寄存器 DR 中
1 | [0001][DR][SR1][0][00][SR2] |
- 前4位为指令编码,接下来的3位表示目标寄存器 DR,接下来的3位表示存储有目标数据的寄存器 SR1,接下来1位用于指明“模式”类型(即时模式 / 寄存器模式),最后5位可以代表 SR2 寄存器也可以代表 imm5 立即数
- 编码显示两行,因为 ADD 指令有两种不同的“模式”:
- 寄存器模式:把 SR1 和 SR2 中的数据相加然后存储到 DR 中
- 即时模式:把 SR1 中的数据与 imm5 相加然后存储到 DR 中
- 符号扩展:ADD 即时模式 imm5 值只有5位,但需要将其添加到16位数字中
- 对于正数,用“0”填充额外的位(强制类型转换即可)
- 对于负数,用“1”填充额外的位
1 | uint16_t sign_extend(uint16_t x, int bit_count) |
- 每当将值写入寄存器时,我们都需要更新标志以指示其符号:
1 | void update_flags(uint16_t r) |
- 指令 ADD 的代码如下:
1 | uint16_t r0 = (instr >> 9) & 0x7; |
指令 LDI:
- LDI 代表“间接加载”,此指令用于将值从内存中的某个位置加载到寄存器中
1 | [1010][DR][PCoffset9] |
- 前4位为指令编码,接下来的3位表示目标寄存器 DR,最后9位代表偏移地址,它告诉我们从何处加载
- 目标地址 = 偏移地址 + PC寄存器的值
- 指令 LDI 的代码如下:
1 | uint16_t r0 = (instr >> 9) & 0x7; |
接下来的大部分指令都是基于以上这两种格式,具体实现过程就省略了
Trap routines 陷阱例程
LC-3 提供了一些预定义的例程用于执行常见任务和与 I/O 设备交互,这些被称为陷阱例程,可以将其视为 LC-3 的操作系统或API
每个陷阱例程都被分配一个陷阱代码 trap code 来标识它(类似于操作码),如果想要执行一个陷阱,则需要使用所需例程的陷阱代码来调用 TRAP 指令
1 | [1111][0000][trapvect8] |
- 前4位为指令编码
[1111],接下来的4位固定为[0000],最后8位代表陷阱代码trap code
1 | enum |
在官方的 LC-3 模拟器中,陷阱例程是用汇编编写的,调用陷阱代码时,会将 PC 寄存器移动到该代码的地址,CPU 执行陷阱例程的指令,完成后,PC 将重置到初始调用后的位置
- 程序起始地址为
0x3000,就是为了给陷阱例程腾出空间
尽管陷阱例程可以用汇编形式编写,并且这是物理 LC-3 计算机可以执行的操作,但它并不是最适合 VM 的
与其编写我们自己的原始 I/O 例程,我们可以利用操作系统上可用的例程,这将使 VM 在我们的计算机上更好地运行,简化代码,并为可移植性提供更高级别的抽象:
1 | reg[R_R7] = reg[R_PC]; |
例程 PUTS:
- 陷阱代码用于输出以 NULL 结尾的字符串(类似于 C 中的
puts) - 要显示字符串,我们必须给陷阱例程一个要显示的字符串,这是通过在开始陷阱之前存储第一个字符的地址 memory 来完成的
1 | { |
- LC-3 中的内存位置为16位,因此字符串中的每个字符的宽度为16位,想要使用C函数显示它,我们需要将每个值转换为
char并单独输出它们
其他的例程都与之类似,用C代码很好实现
Loading programs 加载程序
当汇编程序转换为机器代码时,结果是一个包含指令和数据数组的文件,这可以通过将内容直接复制到内存中的地址来加载
程序文件的前16位指定程序应启动的内存地址(此地址称为 origin),必须首先读取它,然后从源地址开始将其余数据从文件读取到内存中
以下是将 LC-3 程序读入内存的代码:
1 | void read_image_file(FILE* file) |
- LC-3 程序是大端序的,但大多数现代计算机都是小端序的
- 因此,我们需要调用
swap16交换每个加载的内容
1 | uint16_t swap16(uint16_t x) |
Memory mapped registers 内存映射寄存器
某些特殊寄存器无法从普通寄存器表访问,相反,在内存中为他们保留了一个特殊地址,要读取和写入这些寄存器,只需读取和写入它们的内存位置
- 它们被称为内存映射寄存器 Memory mapped registers,它们通常用于与特殊硬件设备进行交互
LC-3有两个需要实现的 Memory mapped registers:
- 键盘状态寄存器 KBSR:标识键盘是“按下”还是“弹起”
- 键盘数据寄存器 KBDR:记录按下的键盘数据
1 | enum |
- Memory mapped registers 使内存访问稍微复杂一些:
- 不能直接读取和写入内存数组,而是必须调用
setter和getter函数 - 当从 KBSR 中读取内存时,
getter将检查键盘并更新两个内存位置
- 不能直接读取和写入内存数组,而是必须调用
1 | void mem_write(uint16_t address, uint16_t val) |
Platform specifics 平台细节
本节包含访问键盘和表现良好的一些繁琐细节,这些与了解 VM 没有见地或相关(随意复制粘贴)
这些函数应该在主函数上方声明
Linux/macOS/UNIX:
1 | struct termios original_tio; |
1 |
|
Windows:
1 | HANDLE hStdin = INVALID_HANDLE_VALUE; |
1 |
|
All platforms:
为了正确处理终端的输入,我们需要调整一些缓冲设置,这些平台的实现因每个平台而异,应该已在上面定义
- 在 main 中循环开始时写入如下代码:
1 | signal(SIGINT, handle_interrupt); /* 设置信号处理程序 */ |
- 如果我们收到结束程序的信号,也应该恢复设置
1 | void handle_interrupt(int signal) |
- 在 main 中循环结束时写入如下代码:
1 | restore_input_buffering(); |
到目前为止,我们编写的所有内容都应按以下顺序添加到 C 文件中:
1 | @{Includes} |
Running the VM 启动虚拟机
现在可以构建并运行 LC-3 虚拟机了:
- 编译虚拟机
1 | gcc lc3.c -o lc3-vm |
- 下载 2048 或 Rogue 的组装版本
- 使用
.obj文件作为参数运行 VM
1 | lc3-vm path/to/2048.obj |
调试 Debugging:
如果程序无法正常工作,则可能是因为您错误地编写了指令,调试起来可能很棘手
我建议通读 LC-3 程序的汇编源代码,同时使用调试器逐个执行 VM 指令,读取程序集时,请确保 VM 转到预期指令,如果出现差异,您将知道是哪个指令导致了问题,重新阅读其规范并仔细检查您的代码
Full VM code 完整虚拟机代码
本人只是把如下文章中的代码拼接到了一起
1 | /* Includes */ |
尝试编译该代码并运行目标程序:
1 | ➜ vm gcc lc3.c -o lc3-vm |
Reverse the VM 逆向虚拟机
此虚拟机被编译为了3个版本:
- 正常版本
- debug 版本
- 去符号版本
正常版本和 debug 版本只有一些全局变量的差别:
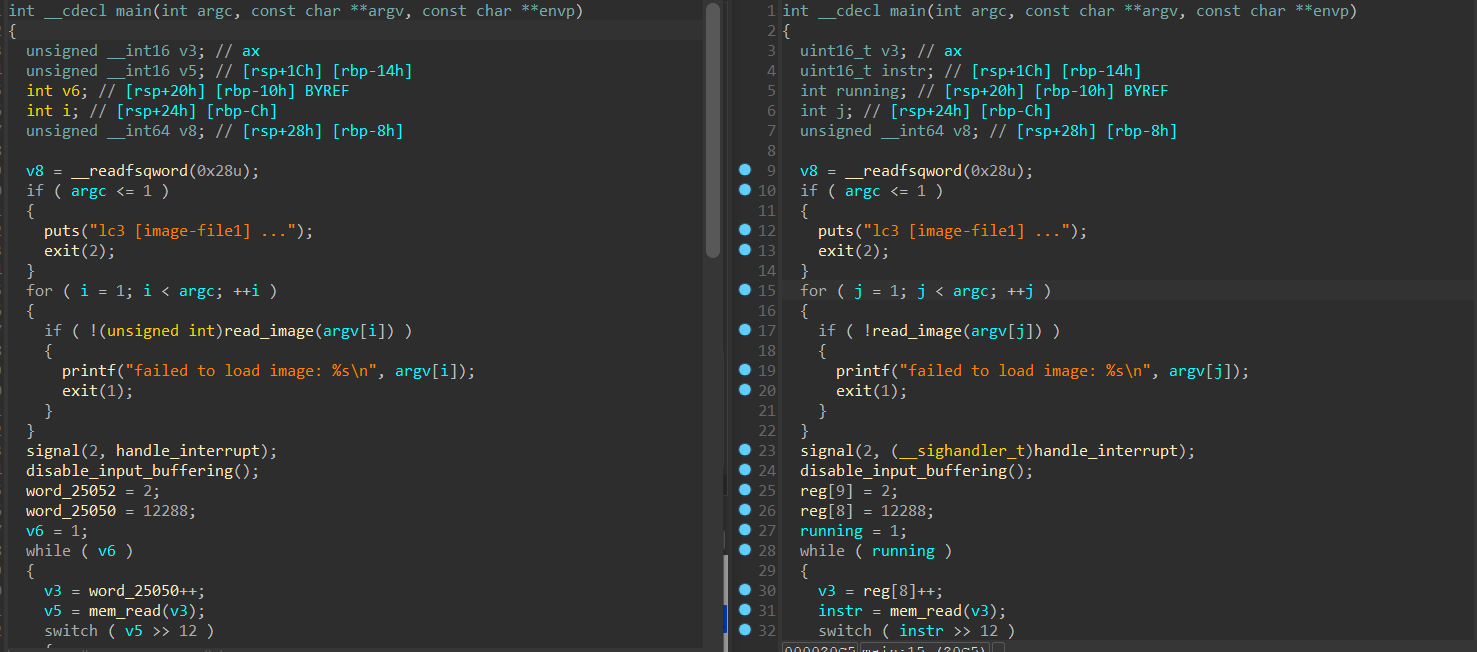
去符号版本的逆向难度要大一些:

总体的逆向思路就是:
- 先找到 Switch-Case 循环,并确定每条指令的长度
- 找到存放寄存器的全局变量,判断各个寄存器个数/位置/功能
- 分析 Switch-Case 的各个分支,弄懂大概的功能,并了解指令中各个位的用途
在 VM pwn 中要多多注意带有 Read/Write 的指令(重点看有没有溢出)