RCU 简述
RCU(Read-Copy Update),是 Linux 中比较重要的一种同步机制,特点如下:
- 复制后更新:但更新数据的时候,需要先复制一份副本,在副本上完成修改,再一次性地替换旧数据”(替换数据时需要其他同步机制的保护)
- 延迟回收内存:在数据被删除后(节点脱链)销毁前(释放空间),需要等待其他读线程停止使用该数据
复制后更新是 Linux 内核实现的一种针对“读多写少”的共享数据的同步机制:
- 不同于其他的同步机制,它允许多个读者同时访问共享数据,而且读者的性能不会受影响
- 读者与写者之间也不需要同步机制,但需要“复制后再写”
- 但如果存在多个写者时,写者与写者之间需要利用其他同步机制保证同步
延迟回收内存是为了防止已经被销毁的数据被其他线程使用:
- 一个位于临界区的指针被释放之后,另一个线程如果使用该指针就会产生安全问题
RCU 作用
RCU 的一个典型的应用场景是链表,主要解决以下问题:
- 在读取过程中,另外一个线程删除了一个节点:
- 删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进行销毁操作
- RCU 中把这个过程称为宽限期(Grace period)
- 在读取过程中,另外一个线程插入了一个新节点
- 需要保证读到的这个节点是完整的(得到的要么全是旧的数据,要么全是新的数据,反正不会是半新半旧的数据)
- 这里涉及到了发布-订阅机制(Publish-Subscribe Mechanism)
- 保证读取链表的完整性
- 新增或者删除一个节点,不至于导致其他正在遍历该链表的线程从中间断开
- 但是 RCU 并不保证一定能读到新增的节点或者不读到要被删除的节点
RCU API
添加链表项:
1 |
|
- 除了
rcu_assign_pointer函数,其他地方和普通的__list_add没什么不同,该函数的底层应该是一个内存屏障(防止 CPU 优化执行顺序),以避免在新指针 new 准备好之前,就被引用了
删除链表项:
1 | static inline void list_del_rcu(struct list_head *entry) |
- 和
list_del相比,list_del_rcu只对entry->prev进行了处理(目前不知道原因)
更新链表:
1 | static inline void list_replace_rcu(struct list_head *old, |
- 同样也是只对
old->prev进行了处理
访问链表:
1 | rcu_read_lock(); /* 声明了一个读端的临界区(read-side critical sections) */ |
rcu_read_lock和rcu_read_unlock用来标识 RCU read side 临界区(其作用就是帮助检测宽限期是否结束)
RCU 机制
宽限期:(Grace period)
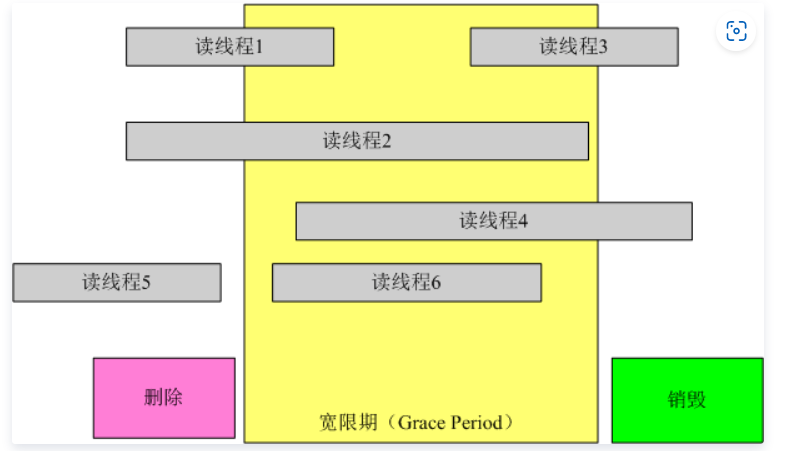
- 宽限期的意义是,在一个删除动作发生后,它必须等待所有在宽限期开始前已经开始的 Reader 线程结束,才可以进行销毁操作(例如:Reader1,Reader2)
- 删除之后,Reader 就会读取新数据,从而拿不到旧数据中的指针,因此就不用考虑安全问题
- 用于判定宽限期开始的函数如下:
1 | void synchronize_rcu(void) |
- 检测宽限期是否结束的操作很复杂,需要利用
rcu_read_lock和rcu_read_unlock所标记的区域进行判断 - 宽限期是 RCU 实现中最复杂的部分,要求在提高读数据性能的同时,删除数据的性能也不能太差
发布-订阅机制:(Publish-Subscribe Mechanism)
1 | static inline void __list_add_rcu(struct list_head *new, |
- 发布-订阅机制其实就是
rcu_assign_pointer函数的使用,用于解决优化导致的 CPU 执行顺序问题 - 对应宏函数如下:
1 |
- 其实我看不太懂这个函数,但它的功能和内存屏障很像,因此它的底层也极有可能是一个内存屏障
复制更新机制:(Copy Update)
1 | p = /* 将要被替换的对象 */ |
- 复制更新机制的实现基于宽限期(等待之前拿到旧节点的 Reader 执行结束,然后释放旧节点,之后拿到新节点的 Reader 不受影响)
synchronize_rcu可以防止在list_replace_rcu之后,kfree之前,有读线程使用了正在进行更新的链表节点- 更新以后的旧节点脱链,拿到旧节点的 Reader 在宽限期中执行完毕,之后的
kfree就不会引发安全问题了 - PS:申请空间和复制数据的操作需要手动完成,没有专门的 API
RCU 案例
Reader 正在遍历查找链表节点:
1 | int search(long key, int *result) { |
Writer 正在遍历删除链表节点:
1 | int delete(long key) { |
假设一个线程执行 Reader,另一个线程执行 Writer:
- 如果使用读写锁,那么 Reader 和 Writer 就不能同时进行,影响效率
- 如果使用顺序锁,那么在 Reader 和 Writer 同时操作指针时容易出现问题
- 这里使用了 RCU 锁,Writer 会在
synchronize_rcu上等待持有旧指针的 Reader 执行完毕,只是牺牲了 Writer 的效率就避免了安全问题
参考: