基础对比
先对比一下 [只开启PIE] 和 [关闭所有保护] 的程序反汇编
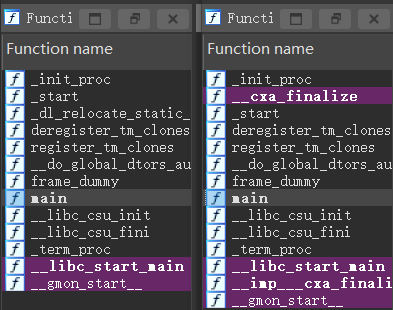
- 关闭 PIE:多一个名为
dl_relocate_static_pie 的函数
- 开启 PIE:多了
__cxa_finalize 和 __imp___cxa_finalize
再对比一下 GDB 调试两个文件效果
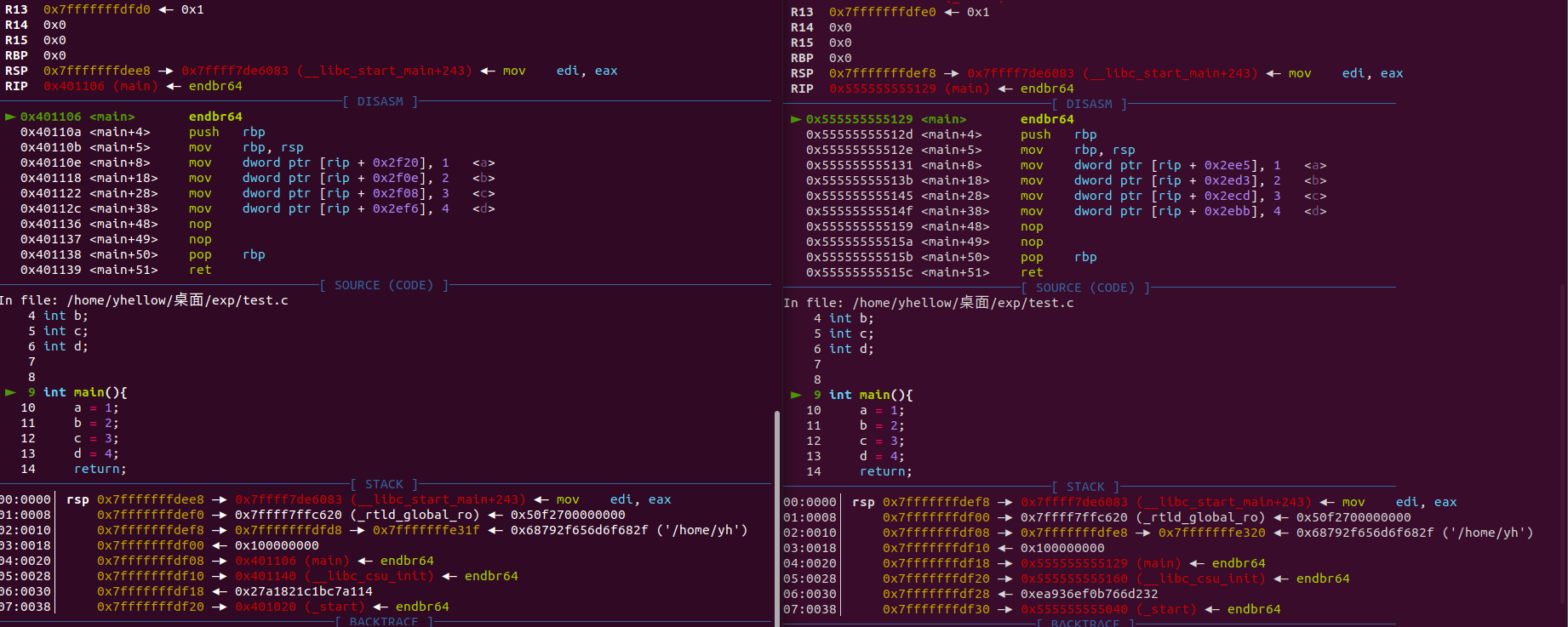
PIE 简述
PIE(position-independent executable)是一种生成地址无关可执行程序的技术,它属于ASLR(Address space layout randomization)的一部分,ASLR 要求执行程序被加载到内存时,它其中的任意部分都是随机的
作用:
- 提高缓冲区溢出攻击的门槛:
- ASLR 要求执行程序被加载到内存时,它其中的任意部分都是随机的
- 包括:Stack,Heap,Libs and mmap,Executable,Linker,VDSO
- 提高内存使用效率(更多指 PIC):
- 一个共享库可以同时被多个进程装载,如果不是地址无关代码(代码段中存在绝对地址引用),每个进程必须结合其自生的内存地址调用动态链接库
- 导致不得不将共享库整体拷贝到进程中,如果系统中有100个进程调用这个库,就会有100份该库的拷贝在内存中,这会照成极大的空间浪费
- 相反如果被加载的共享库是地址无关代码,100个进程调用该库,则该库只需要在内存中加载一次
- 这是因为 PIE 将共享库中代码段须要变换的内容分离到数据段,使得代码段加载到内存时能做到地址无关,多个进程调用共享库时只需要在自己的进程中加载共享库的数据段,而代码段则可以共享
PIE 的由来
PIE 源自于 PIC,因此我们需要先了解一些共享库的知识:
将共享库(.so)载入程序地址空间时需要特殊的处理,简而言之,在链接器创建共享库时,链接器不能对它们的代码假设一个已知的载入地址(因为每个程序可以使用任意多的共享库,没有一个简单的方法预先知道给定的共享库将被载入虚拟内存的什么位置)
在 Linux ELF 共享库里解决这个问题有两个主要途径:
- 载入时重定位(load-time relocation)
- 位置无关代码(PIC)
载入时重定位
1
2
3
4
5
6
7
8
9
10
11
| int myglob = 42;
int ml_util_func(int a){
return a + 1;
}
int ml_func(int a, int b){
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| $ objdump -d -Mintel libmlreloc.so
libmlreloc.so: fileformat elf32-i386
[...] skipping stuff
000004a7 <ml_func>:
4a7: 55 push ebp
4a8: 89 e5 mov ebp,esp
4aa: 83 ec 14 sub esp,0x14
4ad: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
4b0: 89 04 24 mov DWORD PTR [esp],eax
4b3: e8 fc ff ff ff call 4b4 <ml_func+0xd>
4b8: 03 45 0c add eax,DWORD PTR [ebp+0xc]
4bb: 89 45 fc mov DWORD PTR [ebp-0x4],eax
4be: a1 00 00 00 00 mov eax,ds:0x0
4c3: 03 45 fc add eax,DWORD PTR [ebp-0x4]
4c6: a3 00 00 00 00 mov ds:0x0,eax
4cb: a1 00 00 00 00 mov eax,ds:0x0
4d0: 03 45 0c add eax,DWORD PTR [ebp+0xc]
4d3: c9 leave
4d4: c3 ret
[...] skipping stuff
|
- 可以发现重定位并没有完成:
mov myglob 处的偏移任然是“0”call ml_util_func 处的偏移是“0xfffffffc”
创建一个特殊的重定位项指向这个位置:
1
2
3
4
5
6
7
8
9
10
11
| $ readelf -r libmlreloc.so
Relocation section '.rel.dyn' at offset 0x2fc contains 7entries:
Offset Info Type Sym.Value Sym. Name
00002008 00000008R_386_RELATIVE
000004b4 00000502 R_386_PC32 0000049c ml_util_func
000004bf 00000401 R_386_32 0000200c myglob
000004c7 00000401 R_386_32 0000200c myglob
000004cc 00000401 R_386_32 0000200c myglob
[...] skipping stuff
|
- 3处
myglob 的 offset,刚好对应了 ml_func 中空缺 myglob 的地址
- 证明链接器并没有重定位所有的符号,这些 符号都是在载入可执行文件时重定位的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| Dump of assembler code for function ml_func:
0x0012e4a7<+0>: 55 push ebp
0x0012e4a8<+1>: 89 e5 mov ebp,esp
0x0012e4aa<+3>: 83 ec 14 sub esp,0x14
0x0012e4ad<+6>: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
0x0012e4b0<+9>: 89 04 24 mov DWORD PTR [esp],eax
0x0012e4b3<+12>: e8 e4 ff ff ff call 0x12e49c <ml_util_func>
0x0012e4b8<+17>: 03 45 0c add eax,DWORD PTR [ebp+0xc]
0x0012e4bb<+20>: 89 45 fc mov DWORD PTR [ebp-0x4],eax
0x0012e4be<+23>: a1 0c 00 13 00 mov eax,ds:0x13000c
0x0012e4c3<+28>: 03 45 fc add eax,DWORD PTR [ebp-0x4]
0x0012e4c6<+31>: a3 0c 00 13 00 mov ds:0x13000c,eax
0x0012e4cb<+36>: a1 0c 00 13 00 mov eax,ds:0x13000c
0x0012e4d0<+41>: 03 45 0c add eax,DWORD PTR [ebp+0xc]
0x0012e4d3<+44>: c9 leave
0x0012e4d4<+45>: c3 ret
End of assembler dump.
|
总结:
- 载入时重定位是 Linux(及其他OS)用来解决,在将共享库载入内存时,在共享库里访问内部数据与代码的问题,时至今日,位置无关代码(PIC)是一个更流行的方法
- 一些现代系统(比如x86-64)已不再支持载入时重定位
位置无关代码-x86
载入时重定位的问题十分明显:
- 在应用程序载入时,需要花费一些时间执行这些重定位
- 并且它使得库的代码节不可共享
- 如果共享库的代码节可以只载入内存一次(然后映射到许多进程的虚拟内存),数目可观的 RAM 就可以被节省下来
- 但对载入时重定位这是不可能的,因为使用这个技术时,需要在载入时修改代码节来应用重定位(不同的可执行文件在装载同一个动态库的时候,重定位的结果可能不同)
- 另外,它要求要有一个可写的代码节(它必须保持可写,以允许动态载入器执行重定位),形成了一个安全风险
PIC 背后的思想是简单的:对代码中访问的所有全局数据与函数添加一层额外的抽象,通过巧妙地利用链接与载入过程中的某些工件,使得共享库的代码节真正位置无关是可能的(不做任何改变而容易地映射到不同的内存地址)
位置无关代码依靠一个“全局偏移表”或简称 GOT 来完成(这是位于动态库中的 GOT 表):
- 假设在代码节里某条指令想访问一个变量
- 指令不是通过绝对地址直接访问它,而是访问 GOT 里的一个项
- 因为 GOT 在数据节的一个已知位置,这个访问是相对的且链接器已知,而 GOT 项将包含该变量的绝对地址
这样,在代码里通过 GOT 重定向变量的访问,不过我们还是要在数据节里创建一个重定位,因为要让上面描述的场景工作,GOT 仍然必须包含变量的绝对地址,这样做的好处如下:
- 每次变量访问都要求代码节里的重定位,而在 GOT 里对每个变量我们只需要重定位一次,因此这更高效
- 数据节是可写的且不在进程间共享,因此向它添加重定位没有害处,而将重定位移出代码节使得代码节变成只读且在进程间共享
1
2
3
4
5
6
7
8
9
10
11
12
13
| int myglob = 42;
int ml_util_func(int a)
{
return a +1;
}
int ml_func(int a,int b)
{
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| 00000477 <ml_func>:
477: 55 push ebp
478: 89 e5 mov ebp,esp
47a: 53 push ebx
47b: 83 ec 24 sub esp,0x24
47e: e8 e4 ff ff ff call 467 <__i686.get_pc_thunk.bx>
483: 81 c3 71 1b 00 00 add ebx,0x1b71
489: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
48c: 89 04 24 mov DWORD PTR [esp],eax
48f: e8 0c ff ff ff call 3a0 <ml_util_func@plt>
<... snip morecode>
000003a0 <ml_util_func@plt>:
3a0: ff a3 14 00 00 00 jmp DWORD PTR [ebx+0x14]
3a6: 68 10 00 00 00 push 0x10
3ab: e9 c0 ff ff ff jmp 370 <_init+0x30>
0000045a <__i686.get_pc_thunk.cx>:
45a: 8b 0c 24 mov ecx,DWORD PTR [esp]
45d: c3 ret
|
call get_pc_thunk.bx 会把其下一条指令压栈,然后就用 mov 把下一条指令的地址放入 ebx 寄存器- 对
ebx 寄存器中的值进行 add 操作,获取 GOT 基地址,然后获取 myglob 的真实地址
- 访问函数时,先
call 其在 PLT 表中的地址,然后 jmp [ebx+0x14](对应 GOT 中 ml_util_func 的地址)
每个 PLT 项包含三个部分:
- 到 GOT 指定地址的一个跳转(这是跳转到 [ebx + 0x14])
- 为解析者准备参数(用于定位该函数)
- 调用解析函数
位置无关代码-x64
x86设计时没有考虑 PIC,因此实现 PIC 有一点缺陷:
- 一个显而易见的代价是 PIC 中所有对数据及代码的外部访问都要求额外的间接性,即对全局变量的每次访问,以及对函数的每次调用,都要一次额外的内存载入
- 是 PIC 的实现增加了寄存器的使用,需要一整个寄存器存放 GOT 基地址
在64位模式里实现了一个新的取址形式,RIP 相对取址(相当于指令指针):通过向指向下一条指令的64位 RIP 添加位移来构成一个有效的地址
- 在x86中数据访问(使用 mov 指令)仅支持绝对地址
- 在x64模式也用其他指令,比如 lea
1
2
3
4
| mov ax,table ;将table内容传送给ax寄存器
lea ax,table ;将table的地址传送给ax寄存器
;offset是属性操作符,表示应把其后跟着的符号的地址(而不是内容)作为传送数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| int myglob = 42;
int ml_util_func(int a)
{
return a + 1;
}
int ml_func(int a, int b)
{
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 000000000000064b <ml_func>:
64b: 55 push rbp
64c: 48 89 e5 mov rbp,rsp
64f: 48 83 ec 20 sub rsp,0x20
653: 89 7d ec mov DWORD PTR [rbp-0x14],edi
656: 89 75 e8 mov DWORD PTR [rbp-0x18],esi
659: 8b 45 ec mov eax,DWORD PTR [rbp-0x14]
65c: 89 c7 mov edi,eax
65e: e8 fd fe ff ff call 560 <ml_util_func@plt>
[... snip more code ...]
0000000000000560 <ml_util_func@plt>:
560: ff 25 a2 0a 20 00 jmp QWORD PTR [rip+0x200aa2]
566: 68 01 00 00 00 push 0x1
56b: e9 d0 ff ff ff jmp 540 <_init+0x18>
|
get_pc_thunk.bx 函数没有了,程序也不会专门用一个寄存器来保存 GOT 表基地址,而是直接用 rip + offset 来定位 GOT 表
在x86上 GOT 地址以两步被载入到某些基址寄存器:
- 首先以一个特殊的函数调用获取指令的地址
- 然后加上到 GOT 的偏移
在x64上这两步都不需要:
- 因为到 GOT 的相对偏移对链接器是已知的
- 并且可以简单地使用 RIP 相对取址直接获取对应数据
PIE 的原理
PIC 实现了位置无关代码,如果把 PIC 的范围扩大到整个二进制文件,就形成了 PIE:地址无关可执行程序
执行程序时,系统的动态链接器库 ld.so 会首先加载,接着 ld.so 会通过 .dynamic 段中类型为 DT_NEED 的字段查找其他需要加载的共享库,并依次将它们加载到内存中:
- 关闭 PIE:程序会在固定的地址开始加载,这些动态链接库每次加载的顺序和位置都一样
- 开启 PIE:因为没有绝对地址引用,所以每次加载的地址都不相同
- 不仅动态链接库的加载地址不固定,就连执行程序每次加载的地址也不一样
- 这就要求 ld.so 首先被加载后它不仅要负责重定位其他的共享库,同时还要对可执行文件重定位
当 kernel 加载运行一个可执行文件时,会调用 load_elf_binary() 这个函数(这里只写出了和 PIE 有关的片段):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
static int load_elf_binary(struct linux_binprm *bprm)
{
......
if (!(current->personality & ADDR_NO_RANDOMIZE) && randomize_va_space)
current->flags |= PF_RANDOMIZE;
......
retval = create_elf_tables(bprm, &loc->elf_ex,
load_addr, interp_load_addr);
if (retval < 0)
goto out;
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
if ((current->flags & PF_RANDOMIZE) && (randomize_va_space > 1)) {
current->mm->brk = current->mm->start_brk =
arch_randomize_brk(current->mm);
#ifdef compat_brk_randomized
current->brk_randomized = 1;
#endif
}
......
}
|
1
2
3
4
5
|
unsigned long arch_randomize_brk(struct mm_struct *mm)
{
return randomize_page(mm->brk, 0x02000000);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
unsigned long
randomize_page(unsigned long start, unsigned long range)
{
if (!PAGE_ALIGNED(start)) {
range -= PAGE_ALIGN(start) - start;
start = PAGE_ALIGN(start);
}
if (start > ULONG_MAX - range)
range = ULONG_MAX - start;
range >>= PAGE_SHIFT;
if (range == 0)
return start;
return start + (get_random_long() % range << PAGE_SHIFT);
}
|
1
2
3
4
5
6
7
8
9
|
static inline unsigned long get_random_long(void)
{
#if BITS_PER_LONG == 64
return get_random_u64();
#else
return get_random_u32();
#endif
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
u64 get_random_u64(void)
{
u64 ret;
bool use_lock;
unsigned long flags = 0;
struct batched_entropy *batch;
static void *previous;
#if BITS_PER_LONG == 64
if (arch_get_random_long((unsigned long *)&ret))
return ret;
#else
if (arch_get_random_long((unsigned long *)&ret) &&
arch_get_random_long((unsigned long *)&ret + 1))
return ret;
#endif
warn_unseeded_randomness(&previous);
use_lock = READ_ONCE(crng_init) < 2;
batch = &get_cpu_var(batched_entropy_u64);
if (use_lock)
read_lock_irqsave(&batched_entropy_reset_lock, flags);
if (batch->position % ARRAY_SIZE(batch->entropy_u64) == 0) {
extract_crng((u8 *)batch->entropy_u64);
batch->position = 0;
}
ret = batch->entropy_u64[batch->position++];
if (use_lock)
read_unlock_irqrestore(&batched_entropy_reset_lock, flags);
put_cpu_var(batched_entropy_u64);
return ret;
}
EXPORT_SYMBOL(get_random_u64);
|
因为 PIE 使用了 PIC 中的原理(GOT + RIP 相对取址)使代码与地址无关,所以 kernel 在加载ELF文件时,可以直接使用对应的函数把 current->mm->brk 随机化