Linux 内核简述 Linux 的内核虽然是基于单内核的,但是经过这么多年的发展,也具备微内核的一些特征(体现了 Linux 实用至上的原则)
主要有以下特征:
使用 GNU C 库(和标准C库有一定的区别)
支持动态加载内核模块
支持对称多处理(SMP)
内核可以抢占(preemptive),允许内核运行的任务有优先执行的能力
不区分线程和进程
Linux 内核源码的结构
目录 说明
arch
特定体系结构的代码
block
块设备I/O层
crypo
加密API
Documentation
内核源码文档
drivers
设备驱动程序
firmware
使用某些驱动程序而需要的设备固件
fs
VFS和各种文件系统
include
内核头文件
init
内核引导和初始化
ipc
进程间通信代码
kernel
像调度程序这样的核心子系统
lib
同样内核函数
mm
内存管理子系统和VM
net
网络子系统
samples
示例,示范代码
scripts
编译内核所用的脚本
security
Linux 安全模块
sound
语音子系统
usr
早期用户空间代码(所谓的initramfs)
tools
在Linux开发中有用的工具
virt
虚拟化基础结构
进程和线程 进程就是处于执行期的程序,包括:可执行代码,打开的文件,挂起的信号,内核内部的数据,处理器状态,一个或者多个具有内存映射的空间,一个或者多个执行线程,还有存放全局变量的代码段
内核把进程表列存放在叫做 任务队列(task_list) 的双向循环链表中,链表中的每个类型都是 task_struct(该结构体相对较大,包含一个具体进程的所有信息,通常存放在该进程内核栈的末尾)
Windows:开启的一个程序就是一个线程,它只是一个容器,用于装载系统资源,它并不执行代码,它是系统资源分配的最小单元,而在进程中执行代码的是线程,是代码执行的最小单位
Linux:Linux 中的进程于 Windows 相比是很轻量级的,而且不严格区分进程和线程,Linux 的进程就是 Windows 中的线程,线程就是轻量级的进程
Linux 中的第一个进程
Linux 内核在系统启动的最后阶段会启动 init 进程,该进程会读取系统的初始化脚本,并执行其他相关程序,最终启动系统
所有其他进程都是 PID 为“1”的 init 进程的后代
Linux 进程的状态
TASK_RUNNING(运行):正在运行,或者在运行队列中等待运行
TASK_INTERRUPTIBLE(可中断):正在睡眠(被阻塞),可以接受信号而被唤醒
TASK_UNINTERRUPTIBLE(不可中断):正在睡眠(被阻塞),不能被唤醒
TASK_TRACED(被追踪):被其他进程跟踪(例如:通过 ptrace 对调试程序进行跟踪)
强大的调试工具 gdb 和 Linux 系统调用和信号跟踪工具 strace,都是用 ptrace 实现的
ptrace 是一个系统调用,它提供了一种方法来让‘父’进程可以观察和控制其它进程的执行,检查和改变其核心映像以及寄存器,主要用来实现断点调试和系统调用跟踪
TASK_STOPPED(停止):即将停止,然后被回收
Linux 进程的创建
Linux 中创建进程与其他系统有个主要区别,Linux 中创建进程分2步:fork() 和 exec()
fork:通过拷贝当前进程创建一个子进程
exec:读取可执行文件,将其载入到内存中运行
Copy On Write,写时复制:
如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会获取指向相同资源的指针
直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变
也就是说,在一份共享资源,被多个调用者共同消费时,若出现修改资源的操作,我们并不直接对资源进行修改,而是对将资源修改操作划分为三个步骤:
第一:先将资源以 [页为单位] 进行复制,复制出一个新的资源备份
第二:往这个资源备份里面添加新的数据
第三:将原先资源地址指向资源备份的地址
Copy On Write 对 fork 的优化:
减少分配和复制大量资源时带来的瞬间延时
fork 并不是所有的页面都需要复制,父进程的代码段和只读数据段都不被允许修改,所以无需复制
Copy On Write 的原理:
fork() 之后,kernel 把父进程中所有的内存页的权限都设为 read-only,然后子进程的地址空间指向父进程
当父子进程都只读内存时,相安无事,当其中某个进程写内存时,CPU硬件检测到内存页是 read-only 的,于是触发页异常中断(page-fault),陷入 kernel 的一个中断例程
中断例程中,kernel 就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份
创建的流程:
系统调用 clone 的底层会调用 fork(),它的又底层是 _do_fork(),在其中会调用 copy_process()
1 2 p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL , trace, tls, NUMA_NO_NODE);
调用 dup_task_struct() 为新进程分配内核栈,task_struct 等,其中的内容与父进程相同
1 p = dup_task_struct(current, node);
check 新进程(进程数目是否超出上限等)
清理新进程的信息(比如 PID 置0等),使之与父进程区别开
新进程状态置为 TASK_UNINTERRUPTIBLE
更新 task_struct 的 flags 成员
执行调度程序相关设置,将此任务分配给 CPU,然后调用 copy 系列函数复制所有进程信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 shm_init_task(p); retval = security_task_alloc(p, clone_flags); if (retval) goto bad_fork_cleanup_audit; retval = copy_semundo(clone_flags, p); if (retval) goto bad_fork_cleanup_security; retval = copy_files(clone_flags, p); if (retval) goto bad_fork_cleanup_semundo; retval = copy_fs(clone_flags, p); if (retval) goto bad_fork_cleanup_files; retval = copy_sighand(clone_flags, p); if (retval) goto bad_fork_cleanup_fs; retval = copy_signal(clone_flags, p); if (retval) goto bad_fork_cleanup_sighand; retval = copy_mm(clone_flags, p); if (retval) goto bad_fork_cleanup_signal; retval = copy_namespaces(clone_flags, p); if (retval) goto bad_fork_cleanup_mm; retval = copy_io(clone_flags, p); if (retval) goto bad_fork_cleanup_namespaces; retval = copy_thread_tls(clone_flags, stack_start, stack_size, p, tls); if (retval) goto bad_fork_cleanup_io;
调用 alloc_pid() 为新进程分配一个有效的PID(copy_process() 返回)
根据 clone() 的参数标志 clone_flags,拷贝或共享相应的信息
做一些扫尾工作并返回新进程指针
用户态创建进程的 fork() 函数实际上最终是调用 clone() 系统调用,创建线程和进程的步骤一样,只是最终传给 clone() 的参数不同
1 2 3 4 5 6 ► 0x7ffff7ea1f3d <fork+77 > syscall <SYS_clone> fn: 0x1200011 child_stack: 0x0 flags: 0x0 arg: 0x7ffff7fb2810 ◂— 0x0 vararg: 0x0
在内核中创建的内核线程与普通的进程之间还有个主要区别在于:
内核线程没有独立的地址空间,它们只能在内核空间运行
这与之前提到的 Linux 内核是个单内核有关
fork 的变种:vfork
除了不拷贝父进程的页表项以外,vfork 和 fork 的功能相同,子进程作为父进程的一个单独线程,并在父进程的地址空间里运行
创建的子进程会执行完后,才到父进程执行
Linux 线程的创建
在 Linux 中,线程被视为一个与其他进程共享某些资源的进程,每个线程会单独占有一个 task_struct 结构体
Linux 线程和进程的底层都是系统调用 clone(上文已经介绍了 clone 的实现),就是传入的参数不同:
1 2 3 clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND , 0 ); clone(SIGCHLD , 0 ); clone(CLONE_VFORK | CLONE_VM | SIGCHLD, 0 );
参数标志
含义
CLONE_SETTID
将TID回写至用户空间
CLONE_SETTLS
为子进程创建新的TLS
CLONE_SIGHAND
父子进程共享信号处理函数以及被阻断的信号
CLONE_FILES
父子进程共享打开的文件
CLONE_FS
父子进程共享文件系统信息
CLONE_SYSVSEM
父子进程共享System V SEM_UNDO语义
CLONE_THREAD
父子进程放入相同的线程组
CLONE_VFORK
调用vfork,父进程准备睡眠等待子进程将其唤醒
CLONE_NEWNS
为子进程创建新的命名空间
CLONE_STOP
以TASK_STOPPED状态开始进程
CLONE_VM
父子进程共享地址空间
Linux 进程的终止
进程的终止一般是显示地调用 exit,或者隐式地从某个主函数中返回,和创建进程一样,终结一个进程同样有很多步骤:
子进程上的操作:(do_exit)
设置 task_struct 中的标识成员设置为 PF_EXITING
调用 del_timer_sync() 删除内核定时器, 确保没有定时器在排队和运行
调用 exit_mm() 释放进程占用的 mm_struct
调用 sem__exit() ,使进程离开等待 IPC 信号的队列
调用 exit_files() 和 exit_fs(),释放进程占用的文件描述符和文件系统资源
把 task_struct 的 exit_code 设置为进程的返回值
调用 exit_notify() 向父进程发送信号,并把自己的状态设为 EXIT_ZOMBIE
切换到新进程继续执行
子进程进入 EXIT_ZOMBIE 之后,虽然永远不会被调度,关联的资源也释放掉了,但是它本身占用的内存还没有释放(比如:创建时分配的内核栈,task_struct 结构等),这些由父进程来释放
父进程上的操作:(release_task)
父进程受到子进程发送的 exit_notify() 信号后,将该子进程的进程描述符和所有进程独享的资源全部删除
从上面的步骤可以看出,必须要确保每个子进程都有父进程,如果父进程在子进程结束之前就已经结束了会怎么样呢?
子进程在调用 exit_notify() 时已经考虑到了这点
如果子进程的父进程已经退出了,那么子进程在退出时,exit_notify() 函数会先调用 forget_original_parent() ,然后再调用 find_new_reaper() 来寻找新的父进程
find_new_reaper() 函数先在当前线程组中找一个线程作为父亲,如果找不到,就让 init 做父进程(init 进程是在 linux 启动时就一直存在的)
进程的调度 现在的操作系统都是 抢占式多任务 的,为了能让更多的任务能同时在系统上更好的运行,需要一个管理程序来管理计算机上同时运行的各个任务(也就是进程)
抢占式多任务:由调度模式来决定什么时候停止一个进程的运行,以便其他进程可以得到运行机会(这个强制挂起的动作就是抢占)
非抢占式多任务:除非进程自己主动停止运行,否则它会一直执行(这个主动挂起的操作就是让步)
这个管理程序就是调度程序,它的功能说起来很简单:
决定哪些进程运行,哪些进程等待
决定每个进程运行多长时间
总之,调度是一个平衡的过程:
一方面,它要保证各个运行的进程能够最大限度的使用CPU(即尽量少的切换进程,进程切换过多,CPU的时间会浪费在切换上)
另一方面,保证各个进程能公平的使用CPU(即防止一个进程长时间独占CPU的情况)
IO消耗型进程&CPU消耗型进程
IO消耗型进程:用大部分时间来提交/等待 IO 请求,这种进程经常处于可运行状态,但通常都是运行短短的一会儿
CPU消耗型进程:把大部分时间用在执行代码上,除非被抢占,否则它们通常都一直在不停地运行,因为它们对 IO 的需求很小
进程调度策略往往要在这两个矛盾中间寻找平衡:
时间片
决定哪个进程运行以及运行多长时间都和进程的优先级有关,但是对于调度程序来说,并不是运行一次就结束了,还必须知道间隔多久进行下次调度
为了确定一个进程到底能持续运行多长时间,调度中还引入了时间片的概念,也可以认为是进程在下次调度发生前运行的时间(除非进程主动放弃CPU,或者有实时进程来抢占CPU)
时间片的大小设置并不简单:
设大了,系统响应变慢(调度周期长)
设小了,进程频繁切换带来的处理器消耗
默认的时间片一般是10ms
通常来说:
IO消耗型进程不需要太长的时间片
CPU消耗型进程则希望时间片越长越好
完全公平调度器 CFS
前面说过,调度功能就是决定哪个进程运行以及进程运行多长时间
进程的优先级有2种度量方法,一种是 nice 值,一种是实时优先级:(实时优先级 > nice 值)
nice 值的范围是 -20~19,值越大优先级越低,也就是说 nice 值为 -20 的进程优先级最大
实时优先级的范围是 0~99,与 nice 值的定义相反,实时优先级是值越大优先级越高
实时进程都是一些对响应时间要求比较高的进程,因此系统中有实时优先级高的进程处于运行队列的话,它们会抢占一般的进程的运行时间
介绍下 CFS:
CFS 使用红黑树结构,来存储要调度的任务队列
每个节点代表了一个要调度的任务,节点的 key 即为虚拟时间(vruntime),虚拟时间由这个人物的运行时间计算而来(CFS 不再有时间片的概念,取而代之的是 vruntime)
key 越小,也就是 vruntime 越小的话,红黑树对应的节点就越靠左
CFS scheduler 每次都挑选最左边的节点作为下一个要运行的任务,这个节点是“缓存的”,由一个特殊的指针指向,不需要进行 O(logn) 遍历来查找,也因此,CFS 搜索的时间是 O(1)
vruntime(key) 的计算公式:
1 vruntime += 实际运行时间(time process run) * 1024 / 进程权重(load weight of this process)
实际运行时间:该程序已经运行了多久
进程权重:根据任务的 nice 值进行索引
1 2 3 4 5 6 7 8 9 10 static const int prio_to_weight[40 ] = { 88761 , 71755 , 56483 , 46273 , 36291 , 29154 , 23254 , 18705 , 14949 , 11916 , 9548 , 7620 , 6100 , 4904 , 3906 , 3121 , 2501 , 1991 , 1586 , 1277 , 1024 , 820 , 655 , 526 , 423 , 335 , 272 , 215 , 172 , 137 , 110 , 87 , 70 , 56 , 45 , 36 , 29 , 23 , 18 , 15 , };
相当于 nice 和 weight 是等价的,但是不同 nice 值的任务权重差别变大了
例子:现在我们有一个刚来的进程 [time=0,nice=0,priority=1024]:
1 vruntime += 0 * 1024 / 1024 = 10
vruntime 并不是无限小的,有一个最小值来限定 min_vruntime
假如新进程的 vruntime 初值为0的话,比老进程的值小很多,那么它在相当长的时间内都会保持抢占CPU的优势,老进程就要饿死了,这显然是不公平的
CFS 是这样做的:每个CPU的运行队列 cfs_rq 都维护一个 min_vruntime 字段,记录该运行队列中所有进程的 vruntime 最小值,新进程的初始 vruntime 值就以它所在运行队列的 min_vruntime 为基础来设置,与老进程保持在合理的差距范围内
对于新任务来说,vruntime = 0(任务:用于完成某个操作的一组 [进程,线程],用 task_struct 结构体来描述)
调度器入口
进程调度器的主要入口是函数 schedule():
1 2 3 4 5 6 7 8 9 10 11 12 asmlinkage __visible void __sched schedule (void ) struct task_struct *tsk = sched_submit_work(tsk); do { preempt_disable(); __schedule(false ); sched_preempt_enable_no_resched(); } while (need_resched()); } EXPORT_SYMBOL(schedule);
schedule() 函数只是个外层的封装,实际调用的还是 __schedule() 函数
__schedule() 接受一个参数,该参数为 bool 型,false 表示非抢占,自愿调度,而 true 则相反
__schedule() 的实现大概可以分为四个部分:
针对当前进程的处理
选择下一个需要执行的进程
执行切换工作
收尾工作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 static void __sched notrace __schedule(bool preempt){ struct task_struct *prev , *next ; unsigned long *switch_count; struct rq_flags rf ; struct rq *rq ; int cpu; cpu = smp_processor_id(); rq = cpu_rq(cpu); prev = rq->curr; schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); local_irq_disable(); rcu_note_context_switch(preempt); rq_lock(rq, &rf); smp_mb__after_spinlock(); rq->clock_update_flags <<= 1 ; update_rq_clock(rq); switch_count = &prev->nivcsw; if (!preempt && prev->state) { if (unlikely(signal_pending_state(prev->state, prev))) { prev->state = TASK_RUNNING; } else { deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK); prev->on_rq = 0 ; if (prev->in_iowait) { atomic_inc(&rq->nr_iowait); delayacct_blkio_start(); } if (prev->flags & PF_WQ_WORKER) { struct task_struct *to_wakeup ; to_wakeup = wq_worker_sleeping(prev); if (to_wakeup) try_to_wake_up_local(to_wakeup, &rf); } } switch_count = &prev->nvcsw; } next = pick_next_task(rq, prev, &rf); clear_tsk_need_resched(prev); clear_preempt_need_resched(); if (likely(prev != next)) { rq->nr_switches++; rq->curr = next; ++*switch_count; trace_sched_switch(preempt, prev, next); rq = context_switch(rq, prev, next, &rf); } else { rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP); rq_unlock_irq(rq, &rf); } balance_callback(rq); }
__schedule() 通常都需要和一个具体的调度类相关联,所以它会找到一个最高优先级的调度类(拥有自己的运行队列)
而 __schedule() 调用的 pick_next_task() 函数就实现了这个过程,它会以优先级为序,依次检查每一个调用类,选择最高优先级的进程
调度策略
Linux 的调度器是以模块的方式提供的,这种模块化的结构被称为 调度器类 ,它允许多种不同的可动态添加的调度算法共存
每个调度器都有一个优先级,程序会根据优先级遍历调度类,最高优先优先级的调度器类胜出,然后再根据调度器自身的算法去选择下一个将要执行的程序
策略
描述
SCHED_NORMAL
普通的分时进程,使用的 fair_sched_class 调度类(完全公平调度器)
SCHED_FIFO
先进先出的实时进程,当调用程序把CPU分配给进程的时候,它把该进程描述符保留在运行队列链表的当前位置,此调度策略的进程一旦使用CPU则一直运行,如果没有其他可运行的更高优先级实时进程,进程就继续使用CPU,想用多久就用多久,即使还有其他具有相同优先级的实时进程处于可运行状态,使用的是 rt_sched_class 调度类
SCHED_RR
时间片轮转的实时进程,当调度程序把CPU分配给进程的时候,它把该进程的描述符放在运行队列链表的末尾,这种策略保证对所有具有相同优先级的 SCHED_RR 实时进程进行公平分配CPU时间,使用的 rt_sched_class 调度类
SCHED_BATCH
是 SCHED_NORMAL 的分化版本,采用分时策略,根据动态优先级,分配CPU资源,在有实时进程的时候,实时进程优先调度,但针对吞吐量优化,除了不能抢占外与常规进程一样,允许任务运行更长时间,更好使用高速缓存,适合于成批处理的工作,使用的 fair_shed_class 调度类
SCHED_IDLE
优先级最低,在系统空闲时运行,使用的是 idle_sched_class 调度类,给0号进程使用
SCHED_DEADLINE
新支持的实时进程调度策略,针对突发型计算,并且对延迟和完成时间敏感的任务使用,基于 EDF(earliest deadline first),使用的是 dl_sched_class 调度类
SCHED_FIFO:实现了一种简单的先入先出的调度算法,它不使用时间片,处于 SCHED_FIFO 级的进程会比任何 SCHED_NORMAL 级的进程都要优先执行调度
SCHED_RR:SCHED_RR 和 SCHED_FIFO 大体上相同,只是 SCHED_RR 带有时间片,如果一个 SCHED_RR 任务耗尽了它的时间片,在同一优先级的其他实时进程会被轮流调度
PS:SCHED_FIFO 和 SCHED_RR 都是采用静态优先级
上下文切换&抢占
上下文切换:一个可执行进程切换到另一个可执行进程的过程(由 context_switch 函数进行处理)
context_switch 函数完成了两项基本工作:
调用 switch_mm,把虚拟内存从上一个进程映射切换到新进程中
调用 switch_to,把进程处理器状态从上一个进程切换到新进程中
用户抢占:内核从系统调用或中断处理程序即将返回用户空间的时候,如果 need resched 标志被设置,会导致 schedule,此时就会发生用用户抢占
用户抢占的发生场景:
从系统调用返回用户空间
从中断处理程序返回用户空间
内核抢占:Linux 支持内核抢占(对于不支持内核抢占的程序,内核代码会一直执行,直到它完成为止),内核会检查 need resched 和 preempt_count 的值
内核抢占的发生场景:
中断处理程序正在执行,且返回内核空间之前
内核代码再一次具有可抢占性
内核中的任务显式地调用 schedule
内核中的任务阻塞(这同样也会调用 schedule)
preempt_count 简述:
preempt_count 初始化为“0”,每当使用锁时数值加“1”,释放锁时数值减“1”当 preempt_count 为“0”时,说明有一个更为重要的任务需要执行并且可以抢占
当 preempt_count 不为“0”时,说明内核不能安全抢占该进程
系统调用 简单来说,系统调用就是用户程序和硬件设备之间的桥梁,用户程序在需要的时候,通过系统调用来使用硬件设备
系统调用的存在,有以下重要的意义:
用户程序通过系统调用来使用硬件,而不用关心具体的硬件设备,这样大大简化了用户程序的开发
系统调用使得用户程序有更好的可移植性
系统调用使得内核能更好的管理用户程序,增强了系统的稳定性
系统调用有效的分离了用户程序和内核的开发
用户程序,系统调用,内核,硬件设备的调用关系如下图:
要想实现系统调用,主要实现以下几个方面:
通知内核调用一个哪个系统调用(系统调用号)
用户程序把系统调用的参数传递给内核(前5个参数放在 [ebx,ecx,edx,esi,edi] 中,如果参数多的话,还需要用个单独的寄存器存放指向所有参数在用户空间地址的指针)
用户程序获取内核返回的系统调用返回值(获取系统调用的返回值也是通过寄存器,在x86系统上,返回值放在 [eax] 中)
Linux 系统调用的实现
Linux 采用 SYSCALL_DEFINEx 来定义一个系统调用(“x”代表该系统调用的参数个数)
1 2 3 4 5 SYSCALL_DEFINE1(pipe, int __user *, fildes) { return do_pipe2(fildes, 0 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__) #define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__) #define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__) #define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__) #define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__) #define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__) #define SYSCALL_DEFINE_MAXARGS 6 #define SYSCALL_DEFINEx(x, sname, ...) \ SYSCALL_METADATA(sname, x, __VA_ARGS__) \ __SYSCALL_DEFINEx(x, sname, __VA_ARGS__) #ifndef __SYSCALL_DEFINEx #define __SYSCALL_DEFINEx(x, name, ...) \ __diag_push(); \ __diag_ignore(GCC, 8, "-Wattribute-alias" , \ "Type aliasing is used to sanitize syscall arguments" );\ asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \ __attribute__((alias(__stringify(__se_sys##name)))); \ ALLOW_ERROR_INJECTION(sys##name, ERRNO); \ static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__));\ asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \ asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \ { \ long ret = __do_sys##name(__MAP(x,__SC_CAST,__VA_ARGS__));\ __MAP(x,__SC_TEST,__VA_ARGS__); \ __PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \ return ret; \ } \ __diag_pop(); \ static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) #endif
系统调用参数传递
x86-32 系统:
不超过6个:ebx,ecx,edx,esi,edi,ebp 按照顺序存放前6个参数
超过6个:全部参数应该依次放在一块连续的内存区域里,同时在寄存器 ebx 中保存指向该内存区域的指针
x86-64 系统:
RDI、RSI、RDX、RCX、R8、R9 这6个寄存器依次对应第1参数到第6个参数
内核数据结构 Linux 中4个基本的内核数据结构:链表,队列,映射,红黑树
链表
有个单独的头节点(head)
每个节点(node)除了包含必要的数据之外,还有2个指针(pre,next)
pre 指针指向前一个节点(node),next 指针指向后一个节点(node)
头节点(head)的 pre 指针指向链表的最后一个节点
最后一个节点的 next 指针指向头节点(head)
单向链表&双向链表:
1 2 3 4 5 struct list_element { void *data; struct list_element *next ; struct list_element *prev ; }
环形链表:
环形链表的节点和双向链表相同,但是最后一个元素指向第一个元素
有一个特殊的指针(头指针)始终指向头节点,利用该指针可以快速查找链表的“起始端”
Linux 内核的标准链表就是采用的环形链表
Linux 中链表的实现
Linux 不是将数据结构塞入链表,而是将链表节点塞入数据结构
其数据结构很简单:
1 2 3 struct list_head { struct list_head *next , *prev ; };
内核中添加链表的操作如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static inline void list_add_tail (struct list_head *_new, struct list_head *head) __list_add(_new, head->prev, head); } static inline void __list_add(struct list_head *_new, struct list_head *prev, struct list_head *next) { next->prev = _new; _new->next = next; _new->prev = prev; prev->next = _new; }
因为 list_add_tail 只接收 list_head 为参数,链表也只能查找到 list_head 的地址
所以需要一个宏定义来通过 list_head 快速定位父类型结构体:
1 2 3 4 5 #define container_of(ptr, type, member) \ ({ \ const typeof(((type *)0)->member) *__mptr = (ptr); \ (type *)((char *)__mptr - offsetof(type, member)); \ })
使用 container_of 宏,我们可以定义一个简单的宏函数来返回包含 list_head 的父类型结构体的起始地址:
1 2 #define list_entry(ptr, type, member) container_of(ptr, type, member) #define offsetof(TYPE, MEMBER) ((size_t) & ((TYPE *)0)->MEMBER)
依靠 list_entry ,内核提供了创建,操作以及其他链表管理的各种例程(所有这些方法都不需要考虑 list_head 在父类型结构体中的位置)
通过 offsetof ,内核可以快速查看某个结构条目在该父类型结构体中的偏移
PS:对于 container_of 的计算过程可以参考一下这篇博客 => container of()函数简介
Linux 中对链表的其他操作如下:
1 2 static inline void list_add_tail (struct list_head *_new, struct list_head *head) static inline void list_del (struct list_head *entry)
队列
内核中的队列是以字节形式保存数据的,所以获取数据的时候,需要知道数据的大小,如果从队列中取得数据时指定的大小不对的话,取得数据会不完整或过大
队列是限制在两端进行插入操作和删除操作的线性表,允许进行存入操作的一端称为“队尾”,允许进行删除操作的一端称为“队头”
当线性表中没有元素时,称为“空队”
特点:先进先出(FIFO)
常规的队列有如下两种:
顺序队列:建立顺序队列结构必须为其静态分配或动态申请一片连续的存储空间,并设置两个指针进行管理
队头指针 front,它指向队头元素
队尾指针 rear,它指向下一个入队元素的存储位置
链式队列:一个链队列显然需要两个分别指示队头和队尾的指针(分别成为头指针和尾指针)才能唯一确定
Linux 中队列的实现
Linux 中的通用队列被称为 kfifo,提供了两个主要操作:enqueue(入队列)和 dequeue(出队列)
用于管理 kfifo 的结构体如下:
1 2 3 4 5 6 7 struct __kfifo { unsigned int in; unsigned int out; unsigned int mask; unsigned int esize; void *data; };
创建队列 kfifo_alloc:
1 2 3 4 5 6 7 8 9 10 #define kfifo_alloc(fifo, size, gfp_mask) \ __kfifo_int_must_check_helper( \ ({ \ typeof((fifo) + 1) __tmp = (fifo); \ struct __kfifo *__kfifo = &__tmp->kfifo; \ __is_kfifo_ptr(__tmp) ? \ __kfifo_alloc(__kfifo, size, sizeof(*__tmp->type), gfp_mask) : \ -EINVAL; \ }) \ )
该函数创建并初始化一个大小为 size 的 kfifo(内核使用 gfp_mask 来标识分配队列)
该函数的核心还是调用 __kfifo_alloc,在其中会自动分配 buffer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int __kfifo_alloc(struct __kfifo *fifo, unsigned int size, size_t esize, gfp_t gfp_mask) { size = roundup_pow_of_two(size); fifo->in = 0 ; fifo->out = 0 ; fifo->esize = esize; if (size < 2 ) { fifo->data = NULL ; fifo->mask = 0 ; return -EINVAL; } fifo->data = kmalloc_array(esize, size, gfp_mask); if (!fifo->data) { fifo->mask = 0 ; return -ENOMEM; } fifo->mask = size - 1 ; return 0 ; } EXPORT_SYMBOL(__kfifo_alloc);
创建队列 kfifo_init:
1 2 3 4 5 6 7 8 #define kfifo_init(fifo, buffer, size) \ ({ \ typeof((fifo) + 1) __tmp = (fifo); \ struct __kfifo *__kfifo = &__tmp->kfifo; \ __is_kfifo_ptr(__tmp) ? \ __kfifo_init(__kfifo, buffer, size, sizeof(*__tmp->type)) : \ -EINVAL; \ })
该函数创建并初始化一个 kfifo 对象,它将使用由指针 buffer 指向的 size 字节大小的内存
该函数的核心还是调用 __kfifo_init,并为该 buffer 初始化 __kfifo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int __kfifo_init(struct __kfifo *fifo, void *buffer, unsigned int size, size_t esize) { size /= esize; size = roundup_pow_of_two(size); fifo->in = 0 ; fifo->out = 0 ; fifo->esize = esize; fifo->data = buffer; if (size < 2 ) { fifo->mask = 0 ; return -EINVAL; } fifo->mask = size - 1 ; return 0 ; }
Linux 中对队列的其他操作如下:
1 2 3 4 5 #define kfifo_in(fifo, buf, n) #define kfifo_out(fifo, buf, n) #define kfifo_size(fifo) #define kfifo_reset(fifo) #define kfifo_free(fifo)
映射
映射(也称为关联数组)是实现(key,value)绑定的一种数据结构(有点像其他语言中的字典类型),每个唯一的ID对应一个自定义的数据结构
映射需要至少支持三个操作:
Add(key,value)
Remove(key)
value = Lookup(key)
在 Linux 中的映射的目的是绑定一个标识数(UID)到一个指针,使用计算就是整数ID管理机制(IDR)
IDR 是用于将 uid 和一个数据地址进行绑定的一种映射
IDR 把每一个ID分级数据进行管理,每一级维护着ID的5位数据,这样就可以把IDR分为7级进行管理
IDR 底层使用了 redix 树
IDR 怎么对于数据ID管理呢?传统上我们对于未使用的ID进行管理的时候可以使用位图进行管理,也可以使用数组进行管理,也可以使用链表进行ID管理,三个个各有优缺点:
使用位图进行管理:使用空间少,但是对于位图对应的数据结构支持不太友好
使用数组进行管理:寻址快速,但是只能管理比较少量的ID数目
使用链表进行管理:可以支持大量的数据ID,但是通过链表的指针寻址比较慢
而 IDR 管理可以集合以上3者的优点:
Linux 中映射的实现
以下结构体用于映射用户空间的 UID:
1 2 3 4 5 struct idr { struct radix_tree_root idr_rt ; unsigned int idr_base; unsigned int idr_next; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static inline struct radix_tree_root *xfs_dquot_tree ( struct xfs_quotainfo *qi, int type) switch (type) { case XFS_DQ_USER: return &qi->qi_uquota_tree; case XFS_DQ_GROUP: return &qi->qi_gquota_tree; case XFS_DQ_PROJ: return &qi->qi_pquota_tree; default : ASSERT(0 ); } return NULL ; }
struct idr 类于 list_head,用于管理 IDR 整个树的信息其中最关键的是 radix_tree_root,它是 Linux 内核 Radix Tree 的基础数据结构
Linux 整数ID管理机制(IDR)的底层算法就是 Radix Tree,每个 idr 都是被 Radix Tree 组织起来的一个个单元,通过 Radix Tree 可以快速查找到各个 idr
初始化一个 idr:(需要提前定义静态的 idr 结构)
1 2 3 4 5 6 7 8 9 10 11 static inline void idr_init (struct idr *idr) idr_init_base(idr, 0 ); } static inline void idr_init_base (struct idr *idr, int base) INIT_RADIX_TREE(&idr->idr_rt, IDR_RT_MARKER); idr->idr_base = base; idr->idr_next = 0 ; }
分配一个 idr:(把一个 UID 分配给目标 idr,需要两个步骤)
调整后备树的大小:(为下一次调用 idr_alloc() 预分配内存)
1 2 3 4 5 6 void idr_preload (gfp_t gfp_mask) if (__radix_tree_preload(gfp_mask, IDR_PRELOAD_SIZE)) preempt_disable(); } EXPORT_SYMBOL(idr_preload);
在 @start 和 @end 指定的范围内分配一个未使用的ID:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int idr_alloc (struct idr *idr, void *ptr, int start, int end, gfp_t gfp) u32 id = start; int ret; if (WARN_ON_ONCE(start < 0 )) return -EINVAL; ret = idr_alloc_u32(idr, ptr, &id, end > 0 ? end - 1 : INT_MAX, gfp); if (ret) return ret; return id; } EXPORT_SYMBOL_GPL(idr_alloc);
查找一个 idr:
1 2 3 4 5 6 7 8 9 10 11 void *idr_find (const struct idr *idr, unsigned long id) return radix_tree_lookup(&idr->idr_rt, id - idr->idr_base); } EXPORT_SYMBOL_GPL(idr_find); void *radix_tree_lookup (const struct radix_tree_root *root, unsigned long index) return __radix_tree_lookup(root, index, NULL , NULL ); } EXPORT_SYMBOL(radix_tree_lookup);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void *__radix_tree_lookup(const struct radix_tree_root *root, unsigned long index, struct radix_tree_node **nodep, void __rcu ***slotp) { struct radix_tree_node *node , *parent ; unsigned long maxindex; void __rcu **slot; restart: parent = NULL ; slot = (void __rcu **)&root->xa_head; radix_tree_load_root(root, &node, &maxindex); if (index > maxindex) return NULL ; while (radix_tree_is_internal_node(node)) { unsigned offset; parent = entry_to_node(node); offset = radix_tree_descend(parent, &node, index); slot = parent->slots + offset; if (node == RADIX_TREE_RETRY) goto restart; if (parent->shift == 0 ) break ; } if (nodep) *nodep = parent; if (slotp) *slotp = slot; return node; }
如果该函数调用成功,则返回 ID 关联的指针
如果报错,则返回 NULL
删除一个 idr:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void *idr_remove (struct idr *idr, unsigned long id) return radix_tree_delete_item(&idr->idr_rt, id - idr->idr_base, NULL ); } void *radix_tree_delete_item (struct radix_tree_root *root, unsigned long index, void *item) struct radix_tree_node *node =NULL ; void __rcu **slot = NULL ; void *entry; entry = __radix_tree_lookup(root, index, &node, &slot); if (!slot) return NULL ; if (!entry && (!is_idr(root) || node_tag_get(root, node, IDR_FREE, get_slot_offset(node, slot)))) return NULL ; if (item && entry != item) return NULL ; __radix_tree_delete(root, node, slot); return entry; } EXPORT_SYMBOL(radix_tree_delete_item);
如果 idr_remove 调用成功,则将 ID 关联的指针一起从映射中删除
返回被删除的条目,如果不存在则返回 NULL
撤销一个 idr:
1 2 3 4 5 6 7 8 9 void idr_destroy (struct idr *idr) struct radix_tree_node *node = if (radix_tree_is_internal_node(node)) radix_tree_free_nodes(node); idr->idr_rt.xa_head = NULL ; root_tag_set(&idr->idr_rt, IDR_FREE); } EXPORT_SYMBOL(idr_destroy);
如果 idr_destroy 调用成功,则只释放 idr 中未使用的内存,并不会释放当前已经分配给 UID 使用的内存
参考:linux内核IDR机制详解
红黑树
红黑树是对概念模型2-3-4树的一种实现,由于直接进行不同节点间的转化会造成较大的开销,所以选择以二叉树为基础,在二叉树的属性中加入一个 颜色属性 来表示2-3-4树中不同的节点
红黑规则:
节点不是黑色,就是红色(非黑即红)
根节点为黑色,叶节点为黑色(叶节点是指末梢的空节点 Nil或Null)
一个节点为红色,则其两个子节点必须是黑色的(根到叶子的所有路径,不可能存在两个连续的红色节点)
每个节点到叶子节点的所有路径,都包含相同数目的黑色节点(相同的黑色高度)
在插链的过程中,可能会破坏这些规则,这就需要一些机制来恢复平衡:
中断处理 为了提高CPU和外围硬件(硬盘,键盘,鼠标等等)之间协同工作的性能,引入了中断的机制,中断是一种电信号,由硬件设备产生,并直接送入中断控制器的输入引脚中,中断机制是硬件在需要的时候向CPU发出信号,CPU暂时停止正在进行的工作来处理硬件请求
异步中断(一般由硬件引起):CPU 处理中断的时间过长,所以先将硬件复位,使硬件可以继续自己的工作,然后在适当时候处理中断请求中耗时的部分
同步中断:CPU 处理完中断请求的所有工作后才反馈硬件
硬中断
由与系统相连的外设(比如网卡、硬盘)自动产生的,主要是用来通知操作系统系统外设状态的变化(比如当网卡收到数据包的时候,就会发出一个硬中断)
为了在中断执行时间尽可能短和中断处理需完成大量工作之间找到一个平衡点,Linux 将中断处理程序分解为两个半部:上半部(top half)和下半部(bottom half):
顶半部完成尽可能少的比较紧急的功能,它往往只是 简单地读取寄存器中的中断状态并清除中断标志后就进行“登记中断”的工作
“登记中断”:将底半部处理程序挂到该设备的执行队列中去
底半部负责执行中断处理程序 ,它来完成中断事件的绝大多数任务,而且可以被新的中断打断顶半部往往被设计成不可中断,底半部则相对来说并不是非常紧急的,而且相对比较耗时,不在硬件中断服务程序中执行,所以可以打断
简单来说就是:
上半部:登记中断,把底半部处理程序挂到该设备的执行队列中,不可中断必须立刻完成
下半部:负责中断处理程序的具体实现,可中断(可以稍后完成)
上半部由硬中断完成,实现下半部的方法很多,目前使用最多的是以下3中方法:
softirq 软中断
tasklet 小片任务
工作队列
硬中断和软中断的区别
软中断是执行中断指令产生的,而硬中断是由外设引发的
硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器
硬中断是可屏蔽的,软中断不可屏蔽
硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为 [上半部]
软中断处理硬中断未完成的工作,是一种推后执行的机制,属于 [下半部]
softirq 软中断
软中断的流程如下:
软中断是在编译期间静态分配的,它不像 tasklet 那样能被动态地注册或注销,软中断由 softirq_action 结构体表示:
1 2 3 4 struct softirq_action { void (*action)(struct softirq_action *); };
这个结构体的字段是个函数指针,字段名称是 action
函数指针的参数是 struct softirq_action 的地址,其实就是指向 softirq_vec 中的某一项:
如果 open_softirq 是这样调用的:open_softirq(NET_TX_SOFTIRQ, my_tx_action)
那么 my_tx_action 的参数就是:softirq_vec[NET_TX_SOFTIRQ] 的地址
注册软中断的函数 open_softirq:
1 2 3 4 5 6 void open_softirq (int nr, void (*action)(struct softirq_action *)) softirq_vec[nr].action = action; }
触发软中断的函数 raise_softirq:(属于上半部)
1 2 3 4 5 6 7 8 void raise_softirq (unsigned int nr) unsigned long flags; local_irq_save(flags); raise_softirq_irqoff(nr); local_irq_restore(flags); }
1 2 3 4 5 6 7 inline void raise_softirq_irqoff (unsigned int nr) __raise_softirq_irqoff(nr); if (!in_interrupt()) wakeup_softirqd(); }
1 2 3 4 5 6 7 #define or_softirq_pending(x) (S390_lowcore.softirq_pending |= (x)) void __raise_softirq_irqoff(unsigned int nr){ trace_softirq_raise(nr); or_softirq_pending(1UL << nr); }
raise_softirq 通过把 [软中断类型位图] 的对应为置为“1”来传递 [被触发的中断类型]
执行软中断的函数 do_softirq:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 asmlinkage __visible void do_softirq (void ) __u32 pending; unsigned long flags; if (in_interrupt()) return ; local_irq_save(flags); pending = local_softirq_pending(); if (pending) __do_softirq(); local_irq_restore(flags); }
只要软中断类型位图 softirq pending 有一位不为“0”,就证明至少有一种软中断需要被处理,然后就会调用 __do_softirq
tasklet 小片任务
tasklet 也是利用软中断来实现的
tasklet 提供了比软中断更好用的接口(其实就是基于软中断又封装了一下)
tasklet 支持动态地注册或注销
所以除了对性能要求特别高的情况,一般建议使用 tasklet 来实现自己的中断
1 2 3 4 5 6 7 8 struct tasklet_struct { struct tasklet_struct *next ; unsigned long state; atomic_t count; void (*func)(unsigned long ); unsigned long data; };
已经注册了的 tasklet 由两个数据结构来组织:(两个都是 tasklet_struct 链表)
1 2 3 4 5 6 struct tasklet_head { struct tasklet_struct *head ; struct tasklet_struct **tail ; }; static DEFINE_PER_CPU (struct tasklet_head, tasklet_vec) static DEFINE_PER_CPU (struct tasklet_head, tasklet_hi_vec)
分别由 tasklet_schedule 和 tasklet_hi_schedule 函数进行调度:
1 2 3 4 5 6 void __tasklet_schedule(struct tasklet_struct *t){ __tasklet_schedule_common(t, &tasklet_vec, TASKLET_SOFTIRQ); } EXPORT_SYMBOL(__tasklet_schedule);
1 2 3 4 5 6 void __tasklet_hi_schedule(struct tasklet_struct *t){ __tasklet_schedule_common(t, &tasklet_hi_vec, HI_SOFTIRQ); } EXPORT_SYMBOL(__tasklet_hi_schedule);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static void __tasklet_schedule_common(struct tasklet_struct *t, struct tasklet_head __percpu *headp, unsigned int softirq_nr) { struct tasklet_head *head ; unsigned long flags; local_irq_save(flags); head = this_cpu_ptr(headp); t->next = NULL ; *head->tail = t; head->tail = &(t->next); raise_softirq_irqoff(softirq_nr); local_irq_restore(flags); }
所有的 tasklet 都通过重复调用 TASKLET_SOFTIRQ 和 HI_SOFTIRQ 两个软中断来实现
当一个 tasklet 被调度时,内核会唤起这两个软中断中的一个,然后执行特定的函数,执行所有已调度的 tasklet
静态创建一个 tasklet(直接引用):
1 2 3 4 5 #define DECLARE_TASKLET(name, func, data) \ struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data } #define DECLARE_TASKLET_DISABLED(name, func, data) \ struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
这两个宏都能根据给定的名称静态地创建一个 tasklet_struct 结构
两个宏的区别在于:
DECLARE_TASKLET 设置引用计数器为“0”,该 tasklet 处于激活状态
DECLARE_TASKLET_DISABLED 设置引用计数器为“1”,该 tasklet 处于禁止状态
动态创建一个 tasklet(间接引用):
1 2 3 4 5 6 7 8 9 10 void tasklet_init (struct tasklet_struct *t, void (*func)(unsigned long ), unsigned long data) t->next = NULL ; t->state = 0 ; atomic_set(&t->count, 0 ); t->func = func; t->data = data; } EXPORT_SYMBOL(tasklet_init);
其作用就是初始化一个 tasklet_struct
禁止一个 tasklet(暂缓):
1 2 3 4 5 6 static inline void tasklet_disable (struct tasklet_struct *t) tasklet_disable_nosync(t); tasklet_unlock_wait(t); smp_mb(); }
如果该 tasklet 正在执行,这个函数就会等到它执行完毕后再返回
禁止一个 tasklet(立刻):
1 2 3 4 5 static inline void tasklet_disable_nosync (struct tasklet_struct *t) atomic_inc(&t->count); smp_mb__after_atomic(); }
如果该 tasklet 正在执行,这个函数也会立刻终止该 tasklet(这样做会丧失许多安全性)
启用一个禁止的 tasklet:
1 2 3 4 5 static inline void tasklet_enable (struct tasklet_struct *t) smp_mb__before_atomic(); atomic_dec(&t->count); }
删除一个 tasklet:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void tasklet_kill (struct tasklet_struct *t) if (in_interrupt()) pr_notice("Attempt to kill tasklet from interrupt\n" ); while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) { do { yield(); } while (test_bit(TASKLET_STATE_SCHED, &t->state)); } tasklet_unlock_wait(t); clear_bit(TASKLET_STATE_SCHED, &t->state); } EXPORT_SYMBOL(tasklet_kill);
ksoftirqd 对 softirq 和 tasklet 的优化
当大量软中断出现时(tasklet 底层也是软中断),内核会唤醒一组内核线程来处理这些软中断,这些线程的名称都是 ksoftirqd/n
一旦这些线程初始化,就会执行类似于以下代码的死循环:
1 2 3 4 5 6 7 8 9 10 11 12 for (;;){ if (!softirq_pending(cpu)) schedule(); set_current_state(TASK_RUNNING); while (softirq_pending(cpu)){ do_softirq(); if (need_resched()) schedule(); } }
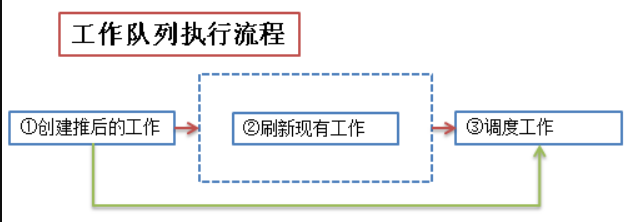
工作队列
工作队列子系统是一个 用于创建内核线程的接口 ,通过它可以创建一个“工作者线程”来专门处理中断的下半部工作(这些工作者线程就叫做 events/n),它在进程的上下文中运行,可以重新调度和睡眠
工作队列和 tasklet 不一样,不是基于软中断来实现的
工作队列主要用到下面几个结构体:
1 2 3 4 5 6 7 8 9 10 struct work_struct { atomic_long_t data; struct list_head entry ; work_func_t func; #ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map ; #endif };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 struct workqueue_struct { struct list_head pwqs ; struct list_head list ; struct mutex mutex ; int work_color; int flush_color; atomic_t nr_pwqs_to_flush; struct wq_flusher *first_flusher ; struct list_head flusher_queue ; struct list_head flusher_overflow ; struct list_head maydays ; struct worker *rescuer ; int nr_drainers; int saved_max_active; struct workqueue_attrs *unbound_attrs ; struct pool_workqueue *dfl_pwq ; #ifdef CONFIG_SYSFS struct wq_device *wq_dev ; #endif #ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map ; #endif char name[WQ_NAME_LEN]; struct rcu_head rcu ; unsigned int flags ____cacheline_aligned; struct pool_workqueue __percpu *cpu_pwqs ; struct pool_workqueue __rcu *numa_pwq_tbl []; };
worker_thread - 工作线程的处理函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 static int worker_thread (void *__worker) struct worker *worker = struct worker_pool *pool = set_pf_worker(true ); woke_up: spin_lock_irq(&pool->lock); if (unlikely(worker->flags & WORKER_DIE)) { spin_unlock_irq(&pool->lock); WARN_ON_ONCE(!list_empty(&worker->entry)); set_pf_worker(false ); set_task_comm(worker->task, "kworker/dying" ); ida_simple_remove(&pool->worker_ida, worker->id); worker_detach_from_pool(worker); kfree(worker); return 0 ; } worker_leave_idle(worker); recheck: if (!need_more_worker(pool)) goto sleep; if (unlikely(!may_start_working(pool)) && manage_workers(worker)) goto recheck; WARN_ON_ONCE(!list_empty(&worker->scheduled)); worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND); do { struct work_struct *work = list_first_entry(&pool->worklist, struct work_struct, entry); pool->watchdog_ts = jiffies; if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) { process_one_work(worker, work); if (unlikely(!list_empty(&worker->scheduled))) process_scheduled_works(worker); } else { move_linked_works(work, &worker->scheduled, NULL ); process_scheduled_works(worker); } } while (keep_working(pool)); worker_set_flags(worker, WORKER_PREP); sleep: worker_enter_idle(worker); __set_current_state(TASK_IDLE); spin_unlock_irq(&pool->lock); schedule(); goto woke_up; }
工作队列的实现比较复杂,我这里还没有完全看明白,以后有需要在专门学习一下
其实工作队列的核心思想就是:内核启动时创建并维护一个工作队列,该队列由内核线程实现,没有任务执行时就陷入睡眠,在用户调用 schedule_work 时,将 work 挂到该工作队列的链表或者队列中,唤醒该内核线程并执行该 work(用户也可以自己创建一个 workqueue 来使用)
内核同步 存在共享资源(共享一个文件,一块内存等等)的时候,为了防止并发访问时共享资源的数据不一致,引入了同步机制
所谓同步,其实防止在临界区中形成竞争条件:
临界区 - 也称为临界段,就是访问和操作共享数据的代码段
竞争条件 - 2个或2个以上线程在临界区里同时执行的时候,就构成了竞争条件
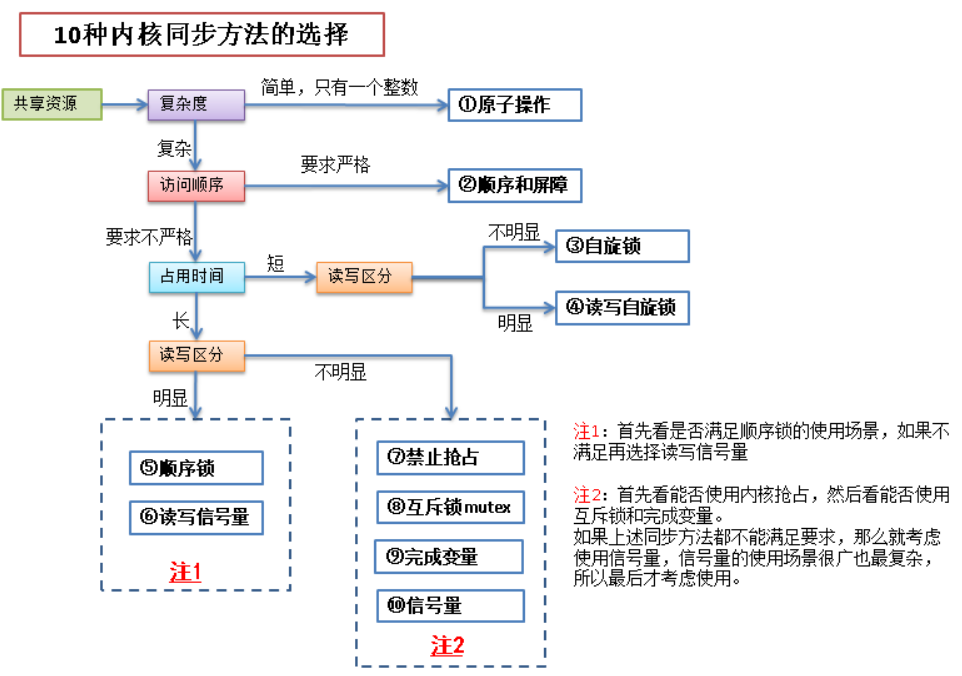
内核同步常见方法如下:
原子操作
原子操作是由编译器来保证的,保证一个线程对数据的操作不会被其他线程打断
所谓原子操作是指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch
原子操作只能针对 atomic_t 类型的数据进行处理:
1 2 3 4 5 6 7 typedef struct { int counter; } atomic_t ; typedef struct { long long counter; } atomic64_t ;
1 2 3 4 5 6 7 8 9 #define atomic_read(v) READ_ONCE((v)->counter) #define atomic64_read(v) READ_ONCE((v)->counter) #define atomic_set(v,i) WRITE_ONCE(((v)->counter), (i)) #define atomic64_set(v,i) WRITE_ONCE((v)->counter, (i)) #define set_bit(nr,p) ATOMIC_BITOP(set_bit,nr,p) #define clear_bit(nr,p) ATOMIC_BITOP(clear_bit,nr,p) #define change_bit(nr,p) ATOMIC_BITOP(change_bit,nr,p)
锁
为了给临界区加锁,保证临界区数据的同步,首先了解一下内核中哪些情况下会产生并发
内核中造成竞争条件的原因:
竞争原因 说明
中断
中断随时会发生,也就会随时打断当前执行的代码,如果中断和被打断的代码在相同的临界区,就产生了竞争条件
软中断和tasklet
软中断和 tasklet 也会随时被内核唤醒执行,也会像中断一样打断正在执行的代码
内核抢占
内核具有抢占性,发生抢占时,如果抢占的线程和被抢占的线程在相同的临界区,就产生了竞争条件
睡眠及用户空间的同步
用户进程睡眠后,调度程序会唤醒一个新的用户进程,新的用户进程和睡眠的进程可能在同一个临界区中
对称多处理
2个或多个处理器可以同时执行相同的代码
加锁后多线程的执行流程:
常见的锁有以下几类:
自旋锁:当一个线程获取了锁之后,其他试图获取这个锁的线程一直在循环等待获取这个锁,直至锁重新可用
由于线程实在一直循环的获取这个锁,所以会造成CPU处理时间的浪费,因此最好将自旋锁用于能很快处理完的临界区
自旋锁常用于中断处理程序中
1 2 3 4 5 6 7 8 9 10 11 spin_lock_init(lock); spin_trylock(lock); spin_is_locked(lock); spin_lock(&lock); spin_lock_irq(&lock); spin_lock_irqsave(&lock, flags); spin_unlock(&lock); spin_unlock_irq(&lock); spin_unlock_irqrestore(&lock, flags);
读写锁:读写锁实际是一种特殊的自旋锁
它把对共享资源的访问者划分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作
其实还是一种锁,是给一段临界区代码加锁,读写之间是互斥的:读的时候写阻塞,写的时候读阻塞,而且读和写在竞争锁的时候,写会优先得到锁
一次只有一个线程可以占有写模式的读写锁,但是可以有多个线程同时占有读模式的读写锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 DEFINE_RWLOCK(lock); read_lock(&lock); read_lock_irq(&lock); read_lock_irqsave(&lock); read_unlock(&lock); read_unlock_irq(&lock); read_unlock_irqrestore(&lock); write_lock(&lock); write_lock_irq(&lock); write_lock_irqsave(&lock); write_unlock(&lock); write_unlock_irq(&lock); write_unlock_irqrestore(&lock);
PS:这里的[读锁]和[写锁]指的都是 lock,它们是同一个锁,只是为了区分[读者]和[写者]和分开命名
顺序锁:顺序锁其实就对读写锁的一种优化
对某一个共享数据读取的时候不加锁,写的时候加锁
在读写锁的基础上,读锁被获取的情况下,写锁仍然可以被获取(顺序锁为写者赋予了较高的优先级,即使在读者正在读的时候,也允许写着继续运行)
可以实现同时读写,但是同时写不被允许
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define DEFINE_SEQLOCK(x) read_seqlock_excl(&lock); read_seqlock_excl_bh(&lock); read_seqlock_excl_irq(&lock); read_seqlock_excl_irqsave(&lock); read_sequnlock_excl(&lock); read_sequnlock_excl_irq(&lock); write_seqlock(&lock); write_seqlock_bh(&lock); write_seqlock_irq(&lock); write_seqlock_irqsave(&lock); write_unseqlock(&lock); write_sequnlock_irq(&lock); write_sequnlock_irqrestore(&lock);
互斥锁:互斥锁也是一种可以睡眠的锁(互斥锁不属于自旋锁,而是属于信号量)
其实相当于二值信号量,只是内核提供了单独的API,使用的场景也更严格一些
1 2 3 mutex_init(&mutex); mutex_lock(&mutex); mutex_unlock(&mutex);
信号量
信号量也是一种锁,和自旋锁不同的是,进程获取不到信号量的时候,不会像自旋锁一样循环的去试图获取锁,而是进入睡眠(进入等待队列),直至有信号量释放出来时,才会唤醒睡眠的进程,进入临界区执行
信号量结构体具体如下:
1 2 3 4 5 struct semaphore { spinlock_t lock; unsigned int count; struct list_head wait_list ; };
其实信号量就相当于一个 [常数] 加上一个 [等待队列]:
[常数] > 0:代表了当前临界区可以容纳的进程个数
[常数] = 0:争用信号量的进程会进入睡眠(进入等待队列)
[常数] < 0:在等待队列中的进程数目
当一个进程进入临界区时,会先检查该临界区的 semaphore->count:
如果大于“0”就进入该临界区,同时 semaphore->count--
如果小于等于“0”就进入 semaphore->wait_list,同时 semaphore->count--
当一个进程离开临界区时,也会检查该临界区的 semaphore->count:
如果小于“0”就把 semaphore->wait_list 中的一个进程放入临界区,同时 semaphore->count++
如果大于等于“0”,只执行 semaphore->count++ 就可以了
常规信号量:
1 2 3 4 5 6 7 void sema_init (struct semaphore *sem, int val) void down (struct semaphore *sem) int down_interruptible (struct semaphore *sem) int down_trylock (struct semaphore *sem) void up (struct semaphore *sem)
读写信号量:和读写锁一样,只是底层用的是信号量而已
1 2 3 4 5 6 7 #define init_rwsem(sem) void __sched down_read (struct rw_semaphore *sem) void __sched down_write (struct rw_semaphore *sem) void up_read (struct rw_semaphore *sem) void up_write (struct rw_semaphore *sem)
[读者]拿到[读锁]时,其他的[读者]想要拿锁是不会阻塞的,而[写者]则会阻塞
[写者]拿到[写锁]时,不管是[读者]还是[写者]都会阻塞(比读写锁更严格)
完成变量
完成变量的机制类似于信号量,比如一个线程A进入临界区之后,另一个线程B会在完成变量上等待,线程A完成了任务出了临界区之后,使用完成变量来唤醒线程B
如果在内核中一个任务需要发出信号通知另一任务发生了某个特定事件,利用完成变量(completion variable)是使两个任务得以同步的简单方法
如果一个任务要执行一些工作时,另一个任务就会在完成变量上等待
案例:vfork 函数会使用完成变量去唤醒父进程
1 2 3 void init_completion (struct completion *c) void wait_for_completion (struct completion *c) void complete (struct completion *c)
禁止抢占
内核是抢占性的,内核中的进程在任何时候都可以停止,使另一个优先度更高的进程运行,如果一个进程和被它抢占的进程在同一个临界区运行,那么就可能会出现安全问题
1 2 3 4 5 6 进程A对未添加保护的变量buf进行访问 进程A被进程B抢占 进程B也操作变量buf 进程B结束 进程A重新调度 进程A出现安全问题
内核抢占代码使用自旋锁作为非抢占区域的标记(如果一个自旋锁被持有,内核便不能进行抢占),对于独立变量而言,没有必要设置自旋锁(会浪费系统资源),因此需要使用 preempt_disable 来禁止内核抢占
1 2 preempt_enable() preempt_disable()
顺序与屏障
CPU 可能需要按照写数据的顺序来读数据(类似于 FIFO),但编译器和处理器为了提高效率,常常会对读写的顺序进行“重新排布”
有一些机械指令可以示意 CPU 不要对周围的数据进行重新排序,这些指令就叫做“屏障”
1 2 3 4 5 6 7 rmb() wmb() mb() smp_rmb() smp_wmb() smp_mb() barrier()
同步方法选择
系统时间 系统时间管理在内核中有相当重要的地位,内核中有大量函数都是基于时间驱动的
系统中管理的时间有2种:实际时间和定时器
实际时间:现实中钟表上显示的时间,其实内核中并不常用这个时间,主要是用户空间的程序有时需要获取当前时间,所以内核中也管理着这个时间
定时器:内核中主要使用的时间管理方法,通过定时器,可以有效的调度程序的执行
定时器
定时器在内核中用一个链表来保存的,链表的每个节点都是一个定时器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct timer_list { struct hlist_node entry ; unsigned long expires; void (*function)(struct timer_list *); u32 flags; #ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map ; #endif }; struct hlist_node { struct hlist_node *next , **pprev ; };
定时器的使用中,下面2个概念非常重要:
HZ:节拍率(HZ)是时钟中断的频率,表示的一秒内时钟中断的次数
jiffies:jiffies 用来记录自系统启动以来产生的总节拍数,比如系统启动了 N 秒,那么 jiffies 就为 N×HZ
1 2 3 4 5 6 7 8 # define jiffies raid6_jiffies() static inline uint32_t raid6_jiffies (void ) struct timeval tv ; gettimeofday(&tv, NULL ); return tv.tv_sec*1000 + tv.tv_usec/1000 ; }
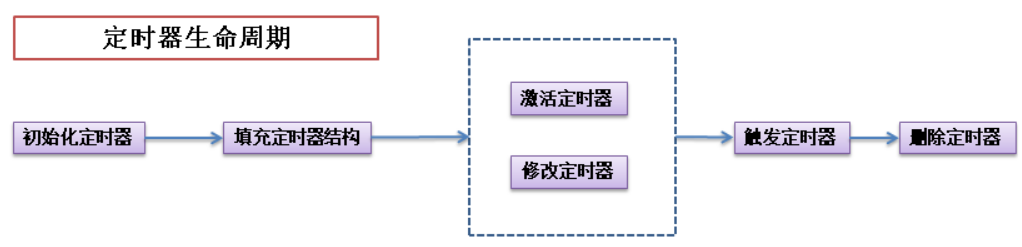
一个动态定时器的生命周期中,一般会经过下面的几个步骤:
相关的 API 如下:
1 2 3 4 5 #define timer_setup(timer, callback, flags) \ __init_timer((timer), (callback), (flags)) void add_timer (struct timer_list *timer) int mod_timer (struct timer_list *timer, unsigned long expires) int del_timer (struct timer_list * timer)
时间中断
时钟中断处理程序作为系统定时器而注册到内核中,体系结构的不同,可能时钟中断处理程序中处理的内容不同,介绍如下:
时钟中断是一种硬中断,由时间硬件(系统定时器,一种可编程硬件)产生,CPU处理后交由时间中断处理程序来完成更新系统时间、执行周期性任务等
系结构相关部分被注册到内核中,确保中断产生时能执行,这部分不能有耗时操作,主要是更新时间与调用结构无关部分列程(异步)
已到期的定时器由体系结构无关部分来处理,其它的一些耗时操作,如显示时间的更新也在这一部分
但是以下这些基本的工作都会执行:
获得 xtime_lock 锁(一种顺序锁),以便对访问 jiffies_64 和墙上时间 xtime 进行保护
需要时应答或重新设置系统时钟
周期性的使用墙上时间更新实时时钟
调用 tick_periodic()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 static void tick_periodic (int cpu) if (tick_do_timer_cpu == cpu) { write_seqlock(&jiffies_lock); tick_next_period = ktime_add(tick_next_period, tick_period); do_timer(1 ); write_sequnlock(&jiffies_lock); update_wall_time(); } update_process_times(user_mode(get_irq_regs())); profile_tick(CPU_PROFILING); } void do_timer (unsigned long ticks) jiffies_64 += ticks; calc_global_load(ticks); } void update_process_times (int user_tick) struct task_struct *p = account_process_tick(p, user_tick); run_local_timers(); rcu_check_callbacks(user_tick); #ifdef CONFIG_IRQ_WORK if (in_irq()) irq_work_tick(); #endif scheduler_tick(); if (IS_ENABLED(CONFIG_POSIX_TIMERS)) run_posix_cpu_timers(p); }
上述场景中,写锁必须要优先于读锁(因为 xtime 必须及时更新),而且写锁的使用者很少(一般只有系统定期更新 xtime 的线程需要持有这个锁)
这正是 [顺序锁] 的应用场景
延迟运行
除了使用定时器和下半部机制以外,还需要其他方法来推迟执行任务:
1 2 3 4 5 6 7 8 9 unsigned long delay = jiffies + 100 ; while (time_before(jiffies, delay)) cond_resched(); unsigned long delay = jiffies + 2 *HZ; while (time_before(jiffies, delay)) cond_resched();
1 2 3 void udelay (unsigned long usecs) void ndelay (unsigned long nsecs) #define mdelay(n) udelay((n) * 1000)
schedule_timeout():让需要延迟运行的任务睡眠到指定时间后,再运行(底层还是定时器)
1 signed long __sched schedule_timeout (signed long timeout)
内存管理 页
内存最基本的管理单元是页,同时按照内存地址的大小,大致分为3个区,页的大小与体系结构有关,在 x86 结构中一般是 4KB 或者 8KB
可以通过 getconf 命令来查看系统的 page 的大小:
1 2 3 4 5 ➜ 桌面 getconf -a | grep -i 'page' PAGESIZE 4096 PAGE_SIZE 4096 _AVPHYS_PAGES 514073 _PHYS_PAGES 995803
用于描述页的结构体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 struct page { unsigned long flags; atomic_t _count; union { atomic_t _mapcount; struct { u16 inuse; u16 objects; }; }; union { struct { unsigned long private ; struct address_space *mapping ; }; #if USE_SPLIT_PTLOCKS spinlock_t ptl; #endif struct kmem_cache *slab ; struct page *first_page ; }; union { pgoff_t index; void *freelist; }; struct list_head lru ; #if defined(WANT_PAGE_VIRTUAL) void *virtual ; #endif #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS unsigned long debug_flags; #endif #ifdef CONFIG_KMEMCHECK void *shadow; #endif }; struct page { unsigned long flags; union { struct { struct list_head lru ; struct address_space *mapping ; pgoff_t index; unsigned long private ; }; struct { union { struct list_head slab_list ; struct { struct page *next ; #ifdef CONFIG_64BIT int pages; int pobjects; #else short int pages; short int pobjects; #endif }; }; struct kmem_cache *slab_cache ; void *freelist; union { void *s_mem; unsigned long counters; struct { unsigned inuse:16 ; unsigned objects:15 ; unsigned frozen:1 ; }; }; }; struct { unsigned long compound_head; unsigned char compound_dtor; unsigned char compound_order; atomic_t compound_mapcount; }; struct { unsigned long _compound_pad_1; unsigned long _compound_pad_2; struct list_head deferred_list ; }; struct { unsigned long _pt_pad_1; pgtable_t pmd_huge_pte; unsigned long _pt_pad_2; union { struct mm_struct *pt_mm ; atomic_t pt_frag_refcount; }; #if ALLOC_SPLIT_PTLOCKS spinlock_t *ptl; #else spinlock_t ptl; #endif }; struct { struct dev_pagemap *pgmap ; unsigned long hmm_data; unsigned long _zd_pad_1; }; struct rcu_head rcu_head ; }; union { atomic_t _mapcount; unsigned int page_type; unsigned int active; int units; }; atomic_t _refcount; #ifdef CONFIG_MEMCG struct mem_cgroup *mem_cgroup ; #endif #if defined(WANT_PAGE_VIRTUAL) void *virtual ; #endif #ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS int _last_cpupid; #endif } _struct_page_alignment;
区
页是内存管理的最小单元,内核将内存按地址的顺序分成了不同的区
有的硬件只能访问有专门的区,其实一般主要关注的区只有3个:
区 描述 物理内存
ZONE_DMA
DMA使用的页
< 16MB
ZONE_NORMAL
正常可寻址的页
16MB~896MB
ZONE_HIGHMEM
动态映射的页
> 896MB 某些硬件只能直接访问内存地址,不支持内存映射,对于这些硬件内核会分配 ZONE_DMA 区的内存。
某些硬件的内存寻址范围很广,比虚拟寻址范围还要大的多,那么就会用到 ZONE_HIGHMEM 区的内存
而 ZONE_DMA 用于I/O设备直接存储器访问(网卡就会使用 DMA 技术)
对于大部分的内存申请,只要用 ZONE_NORMAL 区的内存即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 struct zone { unsigned long watermark[NR_WMARK]; unsigned long nr_reserved_highatomic; long lowmem_reserve[MAX_NR_ZONES]; #ifdef CONFIG_NUMA int node; #endif struct pglist_data *zone_pgdat ; struct per_cpu_pageset __percpu *pageset ; #ifndef CONFIG_SPARSEMEM unsigned long *pageblock_flags; #endif unsigned long zone_start_pfn; unsigned long managed_pages; unsigned long spanned_pages; unsigned long present_pages; const char *name; #ifdef CONFIG_MEMORY_ISOLATION unsigned long nr_isolate_pageblock; #endif #ifdef CONFIG_MEMORY_HOTPLUG seqlock_t span_seqlock; #endif int initialized; ZONE_PADDING(_pad1_) struct free_area free_area [MAX_ORDER ]; unsigned long flags; spinlock_t lock; ZONE_PADDING(_pad2_) unsigned long percpu_drift_mark; #if defined CONFIG_COMPACTION || defined CONFIG_CMA unsigned long compact_cached_free_pfn; unsigned long compact_cached_migrate_pfn[2 ]; #endif #ifdef CONFIG_COMPACTION unsigned int compact_considered; unsigned int compact_defer_shift; int compact_order_failed; #endif #if defined CONFIG_COMPACTION || defined CONFIG_CMA bool compact_blockskip_flush; #endif bool contiguous; ZONE_PADDING(_pad3_) atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS]; } ____cacheline_internodealigned_in_smp;
分配 ZONE_NORMAL 区的内存的方法如下:
按页获取内存 :最原始的方法,用于底层获取内存的方式
方法 描述
alloc_page(gfp_mask)
只分配一页,返回指向页结构的指针
alloc_pages(gfp_mask, order)
分配 2^order 个页,返回指向第一页页结构的指针
__get_free_page(gfp_mask)
只分配一页,返回指向其逻辑地址的指针
__get_free_pages(gfp_mask, order)
分配 2^order 个页,返回指向第一页逻辑地址的指针
get_zeroed_page(gfp_mask)
只分配一页,让其内容填充为“0”,返回指向其逻辑地址的指针
按字节获取内存 :使用最多的获取方法
有两种方式进行该种类型的分配:
kmalloc:分配的内存物理地址是连续的,虚拟地址也是连续的
vmalloc:分配的内存物理地址是不连续的,虚拟地址是连续的
因此在使用中,用的较多的还是 kmalloc:
kmalloc 的性能较好
kmalloc 的物理地址和虚拟地址之间的映射比较简单,只需要将物理地址的第一页和虚拟地址第一页关联起来即可
vmalloc 由于物理地址是不连续的,所以要将物理地址的每一页都和虚拟地址关联起来才行
PS:其实 kmalloc() 底层也是基于 SLAB 分配器的,只不过它所需要的管理结构头已经按照 2^n 的大小排列事先准备好了而已,这个管理结构体数组是 struct cache_sizes malloc_sizes[]
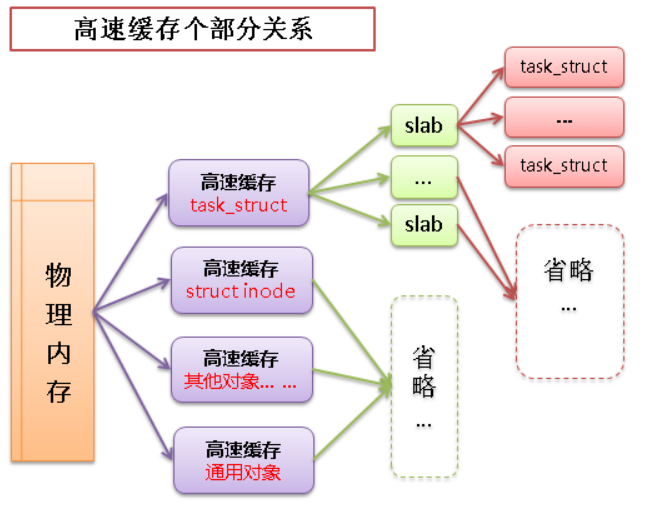
Slab 层获取 :效率最高的获取方法
linux 中的高速缓存是用所谓 slab 层来实现的,slab 层即内核中管理高速缓存的机制,整个 slab 层的原理如下:
可以在内存中建立各种对象的高速缓存(比如进程描述相关的结构 task_struct 的高速缓存)
除了针对特定对象的高速缓存以外,也有通用对象的高速缓存
每个高速缓存中包含多个 slab,slab 用于管理缓存的对象
slab 中包含多个缓存的对象,物理上由一页或多个连续的页组成
高速缓存 -> slab -> 缓存对象之间的关系如下图:
用于管理 slab 的结构体如下:
1 2 3 4 5 6 7 8 struct slab { struct list_head list ; unsigned long colouroff; void *s_mem; unsigned int inuse; kmem_bufctl_t free ; unsigned short nodeid; };
低级内核页分配:(当高速缓存中没有空闲的 slab 时才会调用 kmem_getpages 函数来分配页)
1 2 static struct page *kmem_getpages (struct kmem_cache *cachep, gfp_t flags, int nodeid)
高速缓存内核页分配:
高速缓存的创建
1 2 3 struct kmem_cache * kmem_cache_create (const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *))
name:一个字符串,存放着高速缓存的名字
size:高速缓存中每个元素的大小
align:slab 内第一个对象的偏移
flags:标志位,用于控制高速缓存的行为
flag
function
SLAB_HWCACHE_ALIGN - 0x00002000U
命令 slab 层把一个 slab 内的所有对象按照高速缓存行进行对齐
SLAB_POISON - 0x00000800U
使 slab 层用已知的值(a5a5a5a5)填充 slab,有利于对未初始化内存的访问
SLAB_RED_ZONE - 0x00000400U
使 slab 层在已经分配的内存周围插入“红色警戒区”,用于探测缓冲越界
SLAB_PANIC - 0x00040000U
当分配失败时提醒 slab 层
SLAB_CACHE_DMA - 0x00004000U
命令 slab 层分配可以执行 DMA 的内存空间给各个 slab(只有分配对象用于 DMA 时才会使用)
*ctor:高速缓存的构造函数(只有在新的页追加到高速缓存时,构造函数才会被调用),因为 Linux 内核的高速缓存不使用构造函数,所以这里常常被赋值为 NULL
return:指向高速缓存指针 *cachep
从高速缓存中分配对象
1 void *kmem_cache_alloc (struct kmem_cache *cachep, gfp_t flags)
cachep:指向高速缓存指针
flags:之前讨论的 gfp_mask 标志,只有在高速缓存中所有 slab 都没有空闲对象,并且需要申请新的空间时,这个标志才会起作用
return:指向对象的指针
向高速缓存释放对象
1 void kmem_cache_free (struct kmem_cache *cachep, void *objp)
高速缓存的销毁
1 void kmem_cache_destroy (struct kmem_cache *cachep)
高端内存获取
高端内存就是之前提到的 ZONE_HIGHMEM 区的内存,用于满足 “物理地址空间大于虚拟地址空间” 的一些设备的访问需求
在x86体系结构中,这个区的内存不能映射到内核地址空间上(因为 没有逻辑地址 ),为了使用 ZONE_HIGHMEM 区的内存,内核提供了永久映射和临时映射2种手段:
永久映射:永久映射的函数是可以睡眠的,所以只能用在进程上下文中(永久映射的数量有限)
1 static inline void *kmap (struct page *page)
1 static inline void kunmap (struct page *page)
临时映射:临时映射不会阻塞,也禁止了内核抢占,所以可以用在中断上下文和其他不能重新调度的地方
1 static inline void *kmap_atomic (struct page *page, enum km_type idx)
1 #define kunmap_atomic(addr, idx) do { pagefault_enable(); } while (0)
虚拟文件系统 虚拟文件系统(VFS)是 linux 内核和具体 I/O 设备之间的封装的一层共通访问接口,通过这层接口 Linux 内核可以以同一的方式访问各种 I/O 设备,它提供了一个通用的文件系统模型,该模型囊括了任何文件系统的常用功能和行为
PS:其实不仅是硬件设备,许多软件机制也会构造 VFS 对象,使用户层可以通过操作文件的形式来操作它们(Linux 中一切皆文件,在这里可以体现)
主要有以下好处:
简化了应用程序的开发:应用通过统一的系统调用访问各种存储介质
简化了新文件系统加入内核的过程:新文件系统只要实现VFS的各个接口即可,不需要修改内核部分
虚拟文件系统本身是 linux 内核的一部分,是纯软件的东西,并不需要任何硬件的支持,其核心就是4个主要对象:
超级块:代表一个具体的已安装文件系统
索引结点:代表一个具体的文件
目录项:代表一个目录项,是路径的一个组成部分
文件:代表由进程打开的文件
超级块
超级块(super_block)主要存储文件系统相关的信息,这是个针对文件系统级别的概念
超级块一般存储在磁盘的特定扇区中
但是对于那些基于内存的文件系统(比如 proc,sysfs),超级块是在使用时创建在内存中的
描述超级块的结构体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 struct super_block { struct list_head s_list ; const struct super_operations *s_op ; struct dentry *s_root ; struct mutex s_lock ; int s_count; struct list_head s_inodes ; struct mtd_info *s_mtd ; fmode_t s_mode; }; struct super_operations { struct inode *(*alloc_inode )(struct super_block *sb ); void (*destroy_inode)(struct inode *); void (*dirty_inode) (struct inode *); int (*write_inode) (struct inode *, int ); void (*drop_inode) (struct inode *); void (*delete_inode) (struct inode *); void (*put_super) (struct super_block *); void (*write_super) (struct super_block *); int (*sync_fs)(struct super_block *sb, int wait); int (*statfs) (struct dentry *, struct kstatfs *); int (*remount_fs) (struct super_block *, int *, char *); void (*clear_inode) (struct inode *); void (*umount_begin) (struct super_block *); };
超级块对象通过 alloc_super() 函数创建并初始化(从磁盘读取文件系统超级块,并将信息填充到内存中的超级块对象中)
索引节点
索引节点是 VFS 中的核心概念,它包含内核在操作文件或目录时需要的全部信息
一个索引节点代表文件系统中的一个文件(Linux 一切皆文件)
Linux 系统为每一个文件都分配了一个 inode 编号,这个编号中记录了文件相关的一些元信息,通过这些元信息可以用来唯一标识一个文件(操作系统上的 inode 并非无穷无尽,通常在你安装操作系统后,系统上的 inode 数量就已经确定了下来)
索引节点和超级块一样是实际存储在磁盘上的,当被应用程序访问到时才会在内存中创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 struct inode { struct hlist_node i_hash ; struct list_head i_list ; struct list_head i_sb_list ; struct list_head i_dentry ; unsigned long i_ino; atomic_t i_count; unsigned int i_nlink; uid_t i_uid; gid_t i_gid; struct timespec i_atime ; struct timespec i_mtime ; struct timespec i_ctime ; const struct inode_operations *i_op ; const struct file_operations *i_fop ; struct super_block *i_sb ; struct address_space *i_mapping ; struct address_space i_data ; unsigned int i_flags; void *i_private; }; struct inode_operations { int (*create) (struct inode *,struct dentry *,int , struct nameidata *); struct dentry * (*lookup ) (struct inode *,struct dentry *, struct nameidata *); int (*link) (struct dentry *,struct inode *,struct dentry *); void * (*follow_link) (struct dentry *, struct nameidata *); void (*put_link) (struct dentry *, struct nameidata *, void *); void (*truncate) (struct inode *); };
接下来看看几种类型的索引节点:
磁盘索引节点:保存在硬盘中的索引节点
内存索引节点:保存在内存中的索引节点
文件节点:用于指向磁盘索引节点的节点(有助于硬链接的实现)
不管是文件还是目录,[磁盘索引节点] 都需要与 [内存索引节点] 进行“绑定”,这样才可以操控磁盘上的数据,文件被打开时,[磁盘索引节点] 被复制到 [内存索引节点],以便于使用
相关 API 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static int ext4_create (struct inode *dir, struct dentry *dentry, umode_t mode, bool excl) struct dentry *ext4_lookup (struct inode *dir, struct dentry *dentry, unsigned int flags) static int ext4_link (struct dentry *old_dentry, struct inode *dir, struct dentry *dentry) static int ext4_symlink (struct inode *dir, struct dentry *dentry, const char *symname) static int ext4_mkdir (struct inode *dir, struct dentry *dentry, umode_t mode) static int ext4_mknod (struct inode *dir, struct dentry *dentry, umode_t mode, dev_t rdev) static int ext4_rename (struct inode *old_dir, struct dentry *old_dentry, struct inode *new_dir, struct dentry *new_dentry, unsigned int flags) int ext4_setattr (struct dentry *dentry, struct iattr *attr) int ext4_getattr (const struct path *path, struct kstat *stat, u32 request_mask, unsigned int query_flags) int vfs_setxattr (struct dentry *dentry, const char *name, const void *value, size_t size, int flags) ssize_t vfs_getxattr (struct dentry *dentry, const char *name, void *value, size_t size)
目录项
目录项不是目录,而是目录的组成部分
目录项是描述文件的逻辑属性,只存在于内存中,并不是实际存在于磁盘上,更确切的说是存在于内存的目录项缓存,为了提高查找性能而设计:
在使用的时候在内存中创建目录项对象,其实通过索引节点已经可以定位到指定的文件
但是索引节点对象的属性非常多,在查找,比较文件时,直接用索引节点效率不高,所以引入了目录项的概念
路径中的每个部分都是一个目录项
比如路径:/mnt/cdrom/foo/bar
其中包含5个目录项:/ mnt cdrom foo bar
每个目录项对象都有3种状态:
被使用:对应一个有效的索引节点,并且该对象由一个或多个使用者
未使用:对应一个有效的索引节点,但是VFS当前并没有使用这个目录项
负状态:没有对应的有效索引节点(可能索引节点被删除或者路径不存在了)
描述目录项的结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 struct dentry { atomic_t d_count; unsigned int d_flags; spinlock_t d_lock; int d_mounted; struct inode *d_inode ; struct hlist_node d_hash ; struct dentry *d_parent ; struct qstr d_name ; struct list_head d_lru ; union { struct list_head d_child ; struct rcu_head d_rcu ; } d_u; struct list_head d_subdirs ; struct list_head d_alias ; unsigned long d_time; const struct dentry_operations *d_op ; struct super_block *d_sb ; void *d_fsdata; unsigned char d_iname[DNAME_INLINE_LEN_MIN]; }; struct dentry_operations { int (*d_revalidate)(struct dentry *, struct nameidata *); int (*d_hash) (struct dentry *, struct qstr *); int (*d_compare) (struct dentry *, struct qstr *, struct qstr *); int (*d_delete)(struct dentry *); void (*d_release)(struct dentry *); void (*d_iput)(struct dentry *, struct inode *); char *(*d_dname)(struct dentry *, char *, int ); };
文件
文件对象表示进程已打开的文件,从用户角度来看,我们在代码中操作的就是一个文件对象,它主要从进程的角度描述了一个进程在访问文件时需要了解的文件标识,文件读写的位置,文件引用情况等信息,它的作用范围是某一具体进程
文件对象反过来指向一个目录项对象(目录项反过来指向一个索引节点)
其实只有目录项对象才表示一个已打开的实际文件,虽然一个文件对应的文件对象不是唯一的,但其对应的索引节点和目录项对象却是唯一的
下面是用于描述文件的结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 struct file { union { struct llist_node fu_llist ; struct rcu_head fu_rcuhead ; } f_u; struct path f_path ; struct inode *f_inode ; const struct file_operations *f_op ; spinlock_t f_lock; enum rw_hint f_write_hint ; atomic_long_t f_count; unsigned int f_flags; fmode_t f_mode; struct mutex f_pos_lock ; loff_t f_pos; struct fown_struct f_owner ; const struct cred *f_cred ; struct file_ra_state f_ra ; u64 f_version; #ifdef CONFIG_SECURITY void *f_security; #endif void *private_data; #ifdef CONFIG_EPOLL struct list_head f_ep_links ; struct list_head f_tfile_llink ; #endif struct address_space *f_mapping ; errseq_t f_wb_err; } __randomize_layout __attribute__((aligned(4 )));
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct file_operations { loff_t (*llseek) (struct file *, loff_t , int ); ssize_t (*read) (struct file *, char __user *, size_t , loff_t *); ssize_t (*write) (struct file *, const char __user *, size_t , loff_t *); ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long , loff_t ); ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long , loff_t ); int (*mmap) (struct file *, struct vm_area_struct *); int (*open) (struct inode *, struct file *); int (*flush) (struct file *, fl_owner_t id); };
file_operations 用于实现对于“特定文件系统”的系统调用这里有点面向对象的味道,也是 VFS 可以兼容多种文件系统的原因
四个对象之间关系图:
除了 VFS 以外,内核必须提供 file_system_type 结构体来描述每种文件系统的功能和行为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct file_system_type { const char *name; int fs_flags; #define FS_REQUIRES_DEV 1 #define FS_BINARY_MOUNTDATA 2 #define FS_HAS_SUBTYPE 4 #define FS_USERNS_MOUNT 8 #define FS_RENAME_DOES_D_MOVE 32768 struct dentry *(*mount ) (struct file_system_type *, int , const char *, void *); void (*kill_sb) (struct super_block *); struct module *owner ; struct file_system_type * next ; struct hlist_head fs_supers ; struct lock_class_key s_lock_key ; struct lock_class_key s_umount_key ; struct lock_class_key s_vfs_rename_key ; struct lock_class_key s_writers_key [SB_FREEZE_LEVELS ]; struct lock_class_key i_lock_key ; struct lock_class_key i_mutex_key ; struct lock_class_key i_mutex_dir_key ; };
每种文件系统,不管是有多少个实例安装到系统上,还是根本就没有安装,都只能有一个 file_system_type 结构体
当文件系统被实际安装时,将会有一个 vfsmount 结构体在安装点被创建,用来表示每个文件系统的实例:(代表一个安装点)
1 2 3 4 5 struct vfsmount { struct dentry *mnt_root ; struct super_block *mnt_sb ; int mnt_flags; } __randomize_layout;
块I/O层 I/O设备主要有2类:
字符设备:只能顺序读写设备中的内容(比如:串口设备,键盘)
块设备:能够随机读写设备中的内容(比如:硬盘,U盘)
字符设备由于只能顺序访问,因此应用场景也不多,块设备是随机访问的,所以块设备在不同的应用场景中存在很大的优化空间:
块设备的最小寻址单元就是扇区,扇区的大小是2的整数倍,一般是512字节
扇区是物理上的最小寻址单元,而逻辑上的最小寻址单元是块
为了便于文件系统管理,块的大小一般是扇区的整数倍,并且小于等于页的大小
1 2 3 4 5 6 ➜ 桌面 sudo fdisk -l [sudo] yhellow 的密码: Disk /dev/loop0:4 KiB,4096 字节,8 个扇区 单元:扇区 / 1 * 512 = 512 字节 扇区大小(逻辑/物理):512 字节 / 512 字节 I/O 大小(最小/最佳):512 字节 / 512 字节
块是文件系统的一种抽象:
只能基于块来访问文件系统
磁盘的物理寻址是按照扇区进行的,但内核执行的所有磁盘操作都是按块进行的
内核访问块设备
内核通过文件系统访问块设备时,需要先把块读入到内存中,所以文件系统为了管理块设备,必须管理[块]和内存页之间的映射
内核中有2种方法来管理 [块 ] 和内存页之间的映射:
一,缓冲区和缓冲区头:
每个 [块 ] 都是一个缓冲区,同时对每个 [块 ] 都定义一个缓冲区头来描述它
由于 [块 ] 的大小是小于内存页的大小的,所以每个内存页会包含一个或者多个 [块 ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct buffer_head { unsigned long b_state; struct buffer_head *b_this_page ; struct page *b_page ; sector_t b_blocknr; size_t b_size; char *b_data; struct block_device *b_bdev ; bh_end_io_t *b_end_io; void *b_private; struct list_head b_assoc_buffers ; struct address_space *b_assoc_map ; atomic_t b_count; };
b_state:表示缓冲区的状态,合法的标志存放在 bh_state_bits
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 enum bh_state_bits { BH_Uptodate, BH_Dirty, BH_Lock, BH_Req, BH_Uptodate_Lock, BH_Mapped, BH_New, BH_Async_Read, BH_Async_Write, BH_Delay, BH_Boundary, BH_Write_EIO, BH_Unwritten, BH_Quiet, BH_Meta, BH_Prio, BH_Defer_Completion, BH_PrivateStart, };
1 2 3 4 static inline void get_bh (struct buffer_head *bh) atomic_inc(&bh->b_count); }
1 2 3 4 5 static inline void put_bh (struct buffer_head *bh) smp_mb__before_atomic(); atomic_dec(&bh->b_count); }
PS:在 2.6 版本的 Linux 内核中,许多 IO 操作都不依靠 buffer_head,而是直接对页面或地址空间进行操作来完成,并引入了一种更灵活且轻量级的容器 bio 结构体
二,bio 结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 struct bio { sector_t bi_sector; struct bio *bi_next ; struct block_device *bi_bdev ; unsigned long bi_flags; unsigned long bi_rw; unsigned short bi_vcnt; unsigned short bi_idx; unsigned int bi_phys_segments; unsigned int bi_size; unsigned int bi_seg_front_size; unsigned int bi_seg_back_size; unsigned int bi_max_vecs; unsigned int bi_comp_cpu; atomic_t bi_cnt; struct bio_vec *bi_io_vec ; bio_end_io_t *bi_end_io; void *bi_private; #if defined(CONFIG_BLK_DEV_INTEGRITY) struct bio_integrity_payload *bi_integrity ; #endif bio_destructor_t *bi_destructor; struct bio_vec bi_inline_vecs [0]; };
bio 结构体:表示正在执行的 I/O 操作相关的信息
bi_io_vec 链表:表示当前 I/O 操作涉及到的内存页(每个 bio_vec 都是对应一个页面 page,从而保证内核能够方便高效的完成 I/O 操作)
bio_vec 结构体:表示 I/O 操作使用的片段
1 2 3 4 5 struct bio_vec { struct page *bv_page ; unsigned int bv_len; unsigned int bv_offset; };
bi_vcnt:表示 bi_io_vec 链表中 bi_vec 的个数
bi_idx:表示当前的 bi_vec 片段的索引
请求队列
块设备将它们挂起的块 IO 请求保存在请求队列 request_queue 中
队列中的请求由结构体 request 表示,一个请求可以由多个 bio 结构体组成
内核I/O调度
内核 I/O 调度程序通过两种方式来减少磁盘寻址时间:合并与排序
常见的内核 I/O 调度策略如下:
Linus 电梯:
为了保证磁盘寻址的效率,一般会尽量让磁头向一个方向移动,等到头了再反过来移动,这样可以缩短所有请求的磁盘寻址总时间
磁头的移动有点类似于电梯,所以这个 I/O 调度算法也叫电梯调度
最终期限I/O调度:
最终期限I/O调度算法类似于 Linus 电梯,但是给每个请求设置了超时时间,默认情况下,读请求的超时时间500ms,写请求的超时时间是5s
预测I/O调度:
基于最终期限I/O调度算法,新的读请求提交后,并不立即进行请求处理,而是有意等待片刻(默认是6ms)
等待期间如果有其他对磁盘相邻位置进行读操作的读请求加入,会立刻处理这些读请求
等待期间如果没有其他读请求加入,那么等待时间相当于浪费掉
完全公正的排队I/O调度:
完全公正的排队(Complete Fair Queuing,CFQ)I/O调度,是为专有工作负荷设计的,它和之前提到的I/O调度有根本的不同
CFQ I/O调度算法中,每个进程都有自己的I/O队列
CFQ I/O调度程序以时间片轮转调度队列,从每个队列中选取一定的请求数(默认4个),然后进行下一轮调度
空操作的I/O调度:
空操作I/O调度几乎不做什么事情,这也是它这样命名的原因
空操作I/O调度只做一件事情,当有新的请求到来时,把它与任一相邻的请求合并
Linux 内核中内置了上面4种I/O调度,可以在启动时通过命令行选项 elevator=xxx 来启用任何一种
elevator 选项参数如下:
参数 I/O调度程序
as
预测
cfq
完全公正排队
deadline
最终期限
noop
空操作
进程地址空间 地址空间
进程地址空间也就是每个进程所使用的内存(就是每个进程所能访问的虚拟内存地址范围),内核对进程地址空间的管理,也就是对用户态程序的内存管理
现代的操作系统中进程都是在保护模式下运行的,地址空间其实是操作系统给进程用的一段连续的虚拟内存空间
地址空间最终会通过页表映射到物理内存上,因为内核操作的是物理内存
虽然地址空间的范围很大,但是进程也不一定有权限访问全部的地址空间(一般都是只能访问地址空间中的一些地址区间),进程能够访问的那些地址区间也称为 [内存区域],进程如果访问了有效内存区域以外的内容就会报 “段错误” 信息
内存区域中主要包含以下信息:
代码段 (text section),即可执行文件代码的内存映射
数据段 (data section),即可执行文件的已初始化全局变量的内存映射
bss 段的零页 (页面信息全是“0”值),即未初始化全局变量的内存映射
进程用户空间栈的零页内存映射
进程使用的C库或者动态链接库等共享库的代码段,数据段和bss段的内存映射
任何内存映射文件
任何共享内存段
任何匿名内存映射,比如由 malloc() 分配的内存
linux 中的地址空间是用 mm_struct 来表示的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 struct mm_struct { struct vm_area_struct * mmap ; struct rb_root mm_rb ; struct vm_area_struct * mmap_cache ; unsigned long (*get_unmapped_area) (struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags) void (*unmap_area) (struct mm_struct *mm, unsigned long addr); unsigned long mmap_base; unsigned long task_size; unsigned long cached_hole_size; unsigned long free_area_cache; pgd_t * pgd; atomic_t mm_users; atomic_t mm_count; int map_count; struct rw_semaphore mmap_sem ; spinlock_t page_table_lock; struct list_head mmlist ; mm_counter_t _file_rss; mm_counter_t _anon_rss; unsigned long hiwater_rss; unsigned long hiwater_vm; unsigned long total_vm, locked_vm, shared_vm, exec_vm; unsigned long stack_vm, reserved_vm, def_flags, nr_ptes; unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end; unsigned long saved_auxv[AT_VECTOR_SIZE]; struct linux_binfmt *binfmt ; cpumask_t cpu_vm_mask; mm_context_t context; unsigned int faultstamp; unsigned int token_priority; unsigned int last_interval; unsigned long flags; struct core_state *core_state ; #ifdef CONFIG_AIO spinlock_t ioctx_lock; struct hlist_head ioctx_list ; #endif #ifdef CONFIG_MM_OWNER struct task_struct *owner ; #endif #ifdef CONFIG_PROC_FS struct file *exe_file ; unsigned long num_exe_file_vmas; #endif #ifdef CONFIG_MMU_NOTIFIER struct mmu_notifier_mm *mmu_notifier_mm ; #endif };
mm_users:就是 mm_struct 被用户空间进程(线程)引用的次数
mm_count:其实它记录就是 mm_struct 实际的引用计数
当 mm_users=0 时,并不一定能释放此 mm_struct,只有当 mm_count=0 时,才可以确定释放此 mm_struct
如果只有1个进程使用 mm_struct,那么 mm_users=1,mm_count也是 1
如果有9个线程在使用 mm_struct,那么 mm_users=9,而 mm_count 仍然为 1
虚拟内存区域(VMA)
[内存区域](进程能够访问的那些 [地址区间])在 linux 中也被称为 [虚拟内存区域](VMA),它其实就是进程地址空间上一段连续的内存范围
结构体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 struct vm_area_struct { struct mm_struct * vm_mm ; unsigned long vm_start; unsigned long vm_end; struct vm_area_struct *vm_next , *vm_prev ; pgprot_t vm_page_prot; unsigned long vm_flags; struct rb_node vm_rb ; union { struct { struct list_head list ; void *parent; struct vm_area_struct *head ; } vm_set; struct raw_prio_tree_node prio_tree_node ; } shared; struct list_head anon_vma_node ; struct anon_vma *anon_vma ; const struct vm_operations_struct *vm_ops ; unsigned long vm_pgoff; struct file * vm_file ; void * vm_private_data; unsigned long vm_truncate_count; #ifndef CONFIG_MMU struct vm_region *vm_region ; #endif #ifdef CONFIG_NUMA struct mempolicy *vm_policy ; #endif };
虚拟内存区域(VMA)对应的操作表如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 struct vm_operations_struct { void (*open)(struct vm_area_struct * area); void (*close)(struct vm_area_struct * area); int (*split)(struct vm_area_struct * area, unsigned long addr); int (*mremap)(struct vm_area_struct * area); vm_fault_t (*fault)(struct vm_fault *vmf); vm_fault_t (*huge_fault)(struct vm_fault *vmf, enum page_entry_size pe_size); void (*map_pages)(struct vm_fault *vmf, pgoff_t start_pgoff, pgoff_t end_pgoff); unsigned long (*pagesize) (struct vm_area_struct * area) vm_fault_t (*page_mkwrite)(struct vm_fault *vmf); vm_fault_t (*pfn_mkwrite)(struct vm_fault *vmf); int (*access)(struct vm_area_struct *vma, unsigned long addr, void *buf, int len, int write); const char *(*name)(struct vm_area_struct *vma); #ifdef CONFIG_NUMA int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new ); struct mempolicy *(*get_policy )(struct vm_area_struct *vma , unsigned long addr ); #endif struct page *(*find_special_page )(struct vm_area_struct *vma , unsigned long addr ); };
地址空间和页表
地址空间中的地址都是虚拟内存中的地址,而CPU需要操作的是物理内存(内核操作的也是物理内存),所以需要一个将虚拟地址映射到物理地址的机制
这个机制就是页表,linux 中使用3级页面来完成虚拟地址到物理地址的转换
PGD - 全局页目录,包含一个 pgd_t 类型数组,多数体系结构中 pgd_t 类型就是一个无符号长整型
PMD - 中间页目录,它是个 pmd_t 类型数组
PTE - 简称页表,包含一个 pte_t 类型的页表项,该页表项指向物理页面
翻译后缓存器-translate lookaside buffer-TLB
搜索物理地址的速度很有限,因此为了加快搜索,TLB 机制诞生了
TLB 其实就是一块高速缓存
当请求访问一个虚拟地址时,处理器会先检查 TLB 中是否缓存了该虚拟地址到物理地址的映射
页高速缓存&页回写 为了提高 I/O 性能,也引入了缓存机制,即将一部分磁盘上的数据缓存到内存中
之所以通过缓存能提高 I/O 性能是基于以下2个重要的原理:
CPU访问内存的速度远远大于访问磁盘的速度(访问速度差距不是一般的大,差好几个数量级)
数据一旦被访问,就有可能在短期内再次被访问(临时局部原理)
页高速缓存
页缓存和硬件 cache 的原理基本相同,将容量大而低速设备中的部分数据存放到容量小而快速的设备中,这样速度快的设备将作为低速设备的缓存,当访问低速设备中的数据时,可以直接从缓存中获取数据而不需再访问低速设备,从而节省了整体的访问时间
页高速缓存缓存的是具体的物理页面,与前面章节中提到的虚拟内存空间 vm_area_struct 不同
假设有进程创建了多个 vm_area_struct 都指向同一个文件,那么这个 vm_area_struct 对应的页高速缓存只有一份
也就是磁盘上的文件缓存到内存后,它的虚拟内存地址可以有多个,但是物理内存地址却只能有一个
为了有效提高 I/O 性能,页高速缓存要需要满足以下条件:
能够快速检索需要的内存页是否存在
能够快速定位脏页面(也就是被写过,但还没有同步到磁盘上的数据)
页高速缓存被并发访问时,尽量减少并发锁带来的性能损失
实现页高速缓存的最重要的结构体要算是 address_space:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct address_space { struct inode *host ; struct radix_tree_root page_tree ; spinlock_t tree_lock; unsigned int i_mmap_writable; struct prio_tree_root i_mmap ; struct list_head i_mmap_nonlinear ; spinlock_t i_mmap_lock; unsigned int truncate_count; unsigned long nrpages; pgoff_t writeback_index; const struct address_space_operations *a_ops ; unsigned long flags; struct backing_dev_info *backing_dev_info ; spinlock_t private_lock; struct list_head private_list ; struct address_space *assoc_mapping ; struct mutex unmap_mutex ; } __attribute__((aligned(sizeof (long ))));
这里的 Radix 树(基数树)就是页高速缓存的底层算法
页回写
由于页高速缓存的作用,写操作实际上会被延迟,当页高速缓存中的数据更新,但是后台存储的数据还没有更新时,该数据就被称为脏数据
在内存中累积起来的脏页最终必须被写回磁盘
而写回磁盘的操作就被称为页回写
Linux 页高速缓存页中的回写是由内核中的 flusher 线程来完成的,flusher 线程在以下3种情况发生时,触发回写操作:
一,当空闲内存低于一个阀值时:
空闲内存不足时,需要释放一部分缓存
由于只有不脏的页面才能被释放,所以要把脏页面都回写到磁盘,使其变成干净的页面
二,当脏页在内存中驻留时间超过一个阀值时:
确保脏页面不会无限期的驻留在内存中,从而减少了数据丢失的风险
三,当用户进程调用 sync() 和 fsync() 系统调用时:
给用户提供一种强制回写的方法,应对回写要求严格的场景
但页回写的条件满足时,内核便会调用 wakeup_flusher_threads 来唤醒一个或者多个 flusher 线程,然后 flusher 线程会将脏页写回磁盘
设备&模块 设备类型
Linux 中主要由3种类型的设备,分别是:
设备类型 代表设备 特点 访问方式
块设备
硬盘,光盘
随机访问设备中的内容
一般都是把设备挂载为文件系统后再访问
字符设备
键盘,打印机
只能顺序访问(一个一个字符或者一个一个字节)
一般不挂载,直接和设备交互
网络设备
网卡
打破了Unix “所有东西都是文件” 的设计原则
通过套接字API来访问
除了以上3种典型的设备之外,其实Linux中还有一些其他的设备类型,其中见的较多的应该算是”伪设备”
所谓”伪设备”,其实就是一些虚拟的设备,仅提供访问内核功能而已,没有物理设备与之关联
典型的”伪设备”就是 /dev/random(内核随机数发生器), /dev/null(空设备), /dev/zero(零设备), /dev/full(满设备)
设备结构体
用于描述一个字符设备:
1 2 3 4 5 6 7 8 struct cdev { struct kobject kobj ; struct module *owner ; const struct file_operations *ops ; struct list_head list ; dev_t dev; unsigned int count; } __randomize_layout;
对于不同的文件系统,file_operations 的内容不同
内核对象 kobj 用于统一设备模型
内核模块
Linux 内核是模块化组成的,内核中的模块可以按需加载,从而保证内核启动时不用加载所有的模块,即减少了内核的大小,也提高了效率
通过编写内核模块来给内核增加功能或者接口是个很好的方式(既不用重新编译内核,也方便调试和删除)
带参数的内核模块的示例:(我在网上抄了个示例,打 kernel pwn 的时候可能会用到)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <linux/init.h> #include <linux/module.h> #include <linux/kernel.h> MODULE_LICENSE("Dual BSD/GPL" ); struct student { int id; char * name; }; static void print_student (struct student*) static int stu_id = 0 ; module_param(stu_id, int , 0644 ); MODULE_PARM_DESC(stu_id, "学生ID,默认为 0" ); static char * stu_name_in = "default name" ; module_param_named(stu_name_out, stu_name_in ,charp, 0644 ); MODULE_PARM_DESC(stu_name, "学生姓名,默认为 default name" ); #define MAX_ARR_LEN 5 static int arr_len;static int arr_in[MAX_ARR_LEN];module_param_array_named(arr_out, arr_in, int , &arr_len, 0644 ); MODULE_PARM_DESC(arr_in, "数组参数,默认为空" ); static int test_paramed_km_init (void ) struct student * stu1 ; int i; printk(KERN_ALERT "*************************\n" ); printk(KERN_ALERT "test_paramed_km is inited!\n" ); printk(KERN_ALERT "*************************\n" ); printk(KERN_ALERT "alloc one student....\n" ); stu1 = kmalloc(sizeof (*stu1), GFP_KERNEL); stu1->id = stu_id; stu1->name = stu_name_in; print_student(stu1); for (i = 0 ; i < arr_len; ++i) { printk(KERN_ALERT "arr_value[%d]: %d\n" , i, arr_in[i]); } return 0 ; } static void test_paramed_km_exit (void ) printk(KERN_ALERT "*************************\n" ); printk(KERN_ALERT "test_paramed_km is exited!\n" ); printk(KERN_ALERT "*************************\n" ); printk(KERN_ALERT "\n\n\n\n\n" ); } static void print_student (struct student *stu) if (stu != NULL ) { printk(KERN_ALERT "**********student info***********\n" ); printk(KERN_ALERT "student id is: %d\n" , stu->id); printk(KERN_ALERT "student name is: %s\n" , stu->name); printk(KERN_ALERT "*********************************\n" ); } else printk(KERN_ALERT "the student info is null!!\n" ); } module_init(test_paramed_km_init); module_exit(test_paramed_km_exit);
上面的示例对应的 Makefile 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # must complile on customize kernel obj-m += paramed_km.o paramed_km-objs := test_paramed_km.o # generate the path CURRENT_PATH:=$(shell pwd) # the current kernel version number LINUX_KERNEL:=$(shell uname -r) # the absolute path LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL) # complie object all: make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned # clean clean: rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
内核模块运行方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [root@vbox chap17]# ll <-- 编译内核后,多了paramed_km.ko文件 total 124 -rw-r--r-- 1 root root 538 Dec 1 19:37 Makefile -rw-r--r-- 1 root root 118352 Dec 1 19:37 paramed_km.ko -rw-r--r-- 1 root root 2155 Dec 1 19:37 test_paramed_km.c <-- 通过 modinfo 命令可以查看对内核模块参数的注释 [root@vbox chap17]# modinfo paramed_km.ko filename: paramed_km.ko license: Dual BSD/GPL srcversion: C52F97687B033738742800D depends: vermagic: 2.6.32-279.el6.x86_64 SMP mod_unload modversions parm: stu_id:学生ID,默认为 0 (int) parm: stu_name_out:charp parm: stu_name_in:学生姓名,默认为 default name parm: arr_out:array of int parm: arr_in:数组参数,默认为空 <-- 3 个参数都是默认的 [root@vbox chap17]# insmod paramed_km.ko [root@vbox chap17]# rmmod paramed_km.ko [root@vbox chap17]# dmesg | tail -16 <-- 结果中显示2个默认参数,第3个数组参数默认为空,所以不显示 ************************* test_paramed_km is inited! ************************* alloc one student.... **********student info*********** student id is: 0 student name is: default name ********************************* ************************* test_paramed_km is exited! ************************* <-- 3 个参数都被设置 [root@vbox chap17]# insmod paramed_km.ko stu_id=100 stu_name_out=myname arr_out=1,2,3,4,5 [root@vbox chap17]# rmmod paramed_km.ko [root@vbox chap17]# dmesg | tail -21 ************************* test_paramed_km is inited! ************************* alloc one student.... **********student info*********** student id is: 100 student name is: myname ********************************* arr_value[0]: 1 arr_value[1]: 2 arr_value[2]: 3 arr_value[3]: 4 arr_value[4]: 5 ************************* test_paramed_km is exited! *************************
内核对象
Linux-2.6-kernel 中增加了一个引人注目的新特性:统一设备模型(device model)
统一设备模型的最初动机是为了实现智能的电源管理,linux 内核为了实现智能电源管理,需要建立表示系统中所有设备拓扑关系的树结构
这样在关闭电源时,可以从树的节点开始关闭
实现了统一设备模型之后,还给内核带来了如下的好处:
代码重复最小化(统一处理的东西多了)
可以列举系统中所有设备,观察它们的状态,并查看它们连接的总线
可以将系统中的全部设备以树的形式完整,有效的展示出来—包括所有总线和内部连接
可以将设备和其对应的驱动联系起来,反之亦然
可以将设备按照类型加以归类,无需理解物理设备的拓扑结构
可以沿设备树的叶子向其根的反向依次遍历,以保证能以正确的顺序关闭设备电源
kobject:
统一设备模型的核心部分就是 kobject,通过下面对 kobject 结构体的介绍,可以大致了解它是如何使得各个物理设备能够以树结构的形式组织起来的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct kobject { const char *name; struct list_head entry ; struct kobject *parent ; struct kset *kset ; struct kobj_type *ktype ; struct sysfs_dirent *sd ; struct kref kref ; unsigned int state_initialized:1 ; unsigned int state_in_sysfs:1 ; unsigned int state_add_uevent_sent:1 ; unsigned int state_remove_uevent_sent:1 ; unsigned int uevent_suppress:1 ; };
kobject 本身不代表什么实际的内容,一般都是嵌在其他数据结构中来发挥作用
1 2 3 4 5 6 struct kset { struct list_head list ; spinlock_t list_lock; struct kobject kobj ; struct kset_uevent_ops *uevent_ops ; };
cdev 中嵌入了 kobject 之后,就可以通过 cdev->kboj.parent 建立 cdev 之间的层次关系,通过 cdev->kobj.entry 获取关联的所有 cdev 设备等
总之,嵌入了 kobject 之后,cdev 设备之间就有了树结构关系,cdev 设备和其他设备之间也有可层次关系
sysfs文件系统
sysfs 文件系统是一个处于内存中的虚拟文件系统,它为我们提供 kobject 对象层次结构的视图,帮助用户可以以一个简单文件系统的方式来观察各种设备的拓扑结构:
sysfs 代替了先前处于 proc 下的设备文件
sysfs 就被挂载在 sys 目录中
1 2 3 ➜ labs git:(master) ✗ ls /sys block class devices fs kernel power bus dev firmware hypervisor module
block:每个子目录对应一个系统中已经注册的块设备
bus:提供了一个系统的总线视图
class:包含了以高层功能逻辑组织起来的系统设备视图
dev:已经注册的设备结点视图
devices:系统中设备拓扑结构视图(该目录将设备模型导出到用户空间)
firmware:包含一些诸如 ACPI EDD EFI 等底层子系统的特殊树
fs:已注册文件系统的视图
kernel:包含内核配置项和状态信息
module:包含系统已加载模块的信息
power:包含系统范围的电源管理数据
内核调试 printk
内核提供的打印函数 printk 和C语言提供的 printf 功能几乎相同:
printk 的弹性极佳,可以在任何时候进行调用printk 和 printf 的区别就在于,前者可以提供一个日志等级内核会根据其日志等级来判断是否在终端上打印消息
日志等级
描述
KERN_EMERG
一个紧急情况
KERN_ALERT
一个需要被立刻注意到的错误
KERN_CRIT
一个临界情况
KERN_ERR
一个错误
KERN_WARNING
一个警告
KERN_NOTICE
一个普通情况
KERN_INFO
一条非正式的消息
KERN_DEBUG
一条调试消息
oops
oops 是内核通知用户有错误发生的最常用方式,这个过程包括:
向终端上输出错误信息
输出寄存器中保存的信息
输出可供跟踪的回溯线索
下面是一个 oops 的实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 ➜ 5-oops-mod git:(master) ✗ dmesg | tail -64 [ 139.812510] before init [ 139.812512] BUG: kernel NULL pointer dereference, address: 0000000000000000 [ 139.812515] #PF: supervisor write access in kernel mode [ 139.812516] #PF: error_code(0x0002) - not-present page [ 139.812517] PGD 0 P4D 0 [ 139.812519] Oops: 0002 [#1] SMP NOPTI [ 139.812521] CPU: 1 PID: 3543 Comm: insmod Tainted: G OE 5.15.0-48-generic #54~20.04.1-Ubuntu [ 139.812523] Hardware name: VMware, Inc. VMware Virtual Platform/440BX Desktop Reference Platform, BIOS 6.00 11/12/2020 [ 139.812524] RIP: 0010:my_oops_init+0x15/0x31 [oops_mod] [ 139.812528] Code: Unable to access opcode bytes at RIP 0xffffffffc0b1bfeb. [ 139.812528] RSP: 0018:ffffb1bb85c6bb98 EFLAGS: 00010246 [ 139.812530] RAX: 000000000000000b RBX: 0000000000000000 RCX: 0000000000000027 [ 139.812530] RDX: 0000000000000000 RSI: ffffb1bb85c6b9e0 RDI: ffff942775e60588 [ 139.812531] RBP: ffffb1bb85c6bb98 R08: ffff942775e60580 R09: 0000000000000001 [ 139.812532] R10: 0000000000000001 R11: 000000000000000f R12: ffffffffc0b1c000 [ 139.812533] R13: ffff942695cb5ac0 R14: ffffffffc0b1e000 R15: 0000000000000000 [ 139.812534] FS: 00007f0f977db740(0000) GS:ffff942775e40000(0000) knlGS:0000000000000000 [ 139.812535] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 139.812536] CR2: ffffffffc0b1bfeb CR3: 00000001a9510003 CR4: 0000000000770ee0 [ 139.812557] PKRU: 55555554 [ 139.812558] Call Trace: [ 139.812559] <TASK> [ 139.812561] do_one_initcall+0x46/0x1e0 [ 139.812565] ? __cond_resched+0x19/0x40 [ 139.812568] ? kmem_cache_alloc_trace+0x15a/0x420 [ 139.812571] do_init_module+0x52/0x230 [ 139.812574] load_module+0x1376/0x1600 [ 139.812576] __do_sys_finit_module+0xbf/0x120 [ 139.812578] ? __do_sys_finit_module+0xbf/0x120 [ 139.812579] __x64_sys_finit_module+0x1a/0x20 [ 139.812581] do_syscall_64+0x59/0xc0 [ 139.812583] ? fput+0x13/0x20 [ 139.812584] ? ksys_mmap_pgoff+0x14b/0x2a0 [ 139.812586] ? exit_to_user_mode_prepare+0x3d/0x1c0 [ 139.812588] ? exit_to_user_mode_prepare+0x3d/0x1c0 [ 139.812589] ? syscall_exit_to_user_mode+0x27/0x50 [ 139.812591] ? __x64_sys_mmap+0x33/0x50 [ 139.812592] ? do_syscall_64+0x69/0xc0 [ 139.812593] ? do_syscall_64+0x69/0xc0 [ 139.812594] entry_SYSCALL_64_after_hwframe+0x61/0xcb [ 139.812596] RIP: 0033:0x7f0f9792173d [ 139.812598] Code: 00 c3 66 2e 0f 1f 84 00 00 00 00 00 90 f3 0f 1e fa 48 89 f8 48 89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 8b 0d 23 37 0d 00 f7 d8 64 89 01 48 [ 139.812599] RSP: 002b:00007ffdee07d0f8 EFLAGS: 00000246 ORIG_RAX: 0000000000000139 [ 139.812600] RAX: ffffffffffffffda RBX: 000055e6a61767c0 RCX: 00007f0f9792173d [ 139.812601] RDX: 0000000000000000 RSI: 000055e6a5c91358 RDI: 0000000000000003 [ 139.812602] RBP: 0000000000000000 R08: 0000000000000000 R09: 00007f0f979f8580 [ 139.812602] R10: 0000000000000003 R11: 0000000000000246 R12: 000055e6a5c91358 [ 139.812603] R13: 0000000000000000 R14: 000055e6a6176760 R15: 0000000000000000 [ 139.812604] </TASK> [ 139.812605] Modules linked in: oops_mod(OE+) isofs xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype iptable_filter iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 libcrc32c bpfilter br_netfilter bridge stp llc rfcomm aufs overlay bnep vsock_loopback vmw_vsock_virtio_transport_common vmw_vsock_vmci_transport vsock binfmt_misc nls_iso8859_1 intel_rapl_msr intel_rapl_common kvm_intel kvm crct10dif_pclmul ghash_clmulni_intel aesni_intel crypto_simd vmw_balloon cryptd btusb input_leds btrtl btbcm btintel bluetooth joydev serio_raw ecdh_generic ecc vmw_vmci mac_hid sch_fq_codel vmwgfx ttm drm_kms_helper cec rc_core fb_sys_fops syscopyarea sysfillrect sysimgblt msr parport_pc ppdev drm lp parport ip_tables x_tables autofs4 hid_generic crc32_pclmul usbhid ahci libahci psmouse hid e1000 mptspi pata_acpi mptscsih mptbase i2c_piix4 scsi_transport_spi [ 139.812636] CR2: 0000000000000000 [ 139.812637] ---[ end trace 840a29bcd63bee0c ]--- [ 139.812638] RIP: 0010:my_oops_init+0x15/0x31 [oops_mod] [ 139.812640] Code: Unable to access opcode bytes at RIP 0xffffffffc0b1bfeb. [ 139.812641] RSP: 0018:ffffb1bb85c6bb98 EFLAGS: 00010246 [ 139.812642] RAX: 000000000000000b RBX: 0000000000000000 RCX: 0000000000000027 [ 139.812642] RDX: 0000000000000000 RSI: ffffb1bb85c6b9e0 RDI: ffff942775e60588 [ 139.812643] RBP: ffffb1bb85c6bb98 R08: ffff942775e60580 R09: 0000000000000001 [ 139.812644] R10: 0000000000000001 R11: 000000000000000f R12: ffffffffc0b1c000 [ 139.812644] R13: ffff942695cb5ac0 R14: ffffffffc0b1e000 R15: 0000000000000000 [ 139.812645] FS: 00007f0f977db740(0000) GS:ffff942775e40000(0000) knlGS:0000000000000000 [ 139.812646] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 139.812647] CR2: ffffffffc0b1bfeb CR3: 00000001a9510003 CR4: 0000000000770ee0 [ 139.812664] PKRU: 55555554