Fuzz-Lab1:Xpdf 本次实验我们将对 Xpdf (一款 PDF 转换解析工具)进行 fuzz,目标是在 CVE-2019-13288
CVE-2019-13288 是一个漏洞,可能会通过精心制作的 payload 文件导致无限递归
由于程序中每个被调用的函数都会在栈上分配一个栈帧,如果一个函数被递归调用这么多次,就会导致栈内存耗尽和程序崩溃
因此,远程攻击者可以利用它进行 DoS 攻击
学习的目标:
使用 instrumentation 工具编译目标应用程序
运行模糊器(afl-fuzz)
使用调试器(GDB)对崩溃进行分类
Download and build your target 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 cd $HOME # 创建目录 mkdir fuzzing_xpdf && cd fuzzing_xpdf/ sudo apt install build-essential cd .. wget https://dl.xpdfreader.com/old/xpdf-3.02.tar.gz # 获取xpdf tar -xvzf xpdf-3.02.tar.gz cd xpdf-3.02 # 编译&安装xpdf sudo apt update && sudo apt install -y build-essential gcc ./configure --prefix="$HOME/fuzzing_xpdf/install/" make make install cd $HOME/fuzzing_xpdf # 下载一些PDF示例 mkdir pdf_examples && cd pdf_examples wget https://github.com/mozilla/pdf.js-sample-files/raw/master/helloworld.pdf wget http://www.africau.edu/images/default/sample.pdf wget https://www.melbpc.org.au/wp-content/uploads/2017/10/small-example-pdf-file.pdf
我们可以使用以下命令测试 pdfinfo 二进制文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 ➜ pdf_examples $HOME/fuzzing_xpdf/install/bin/pdfinfo -box -meta $HOME/fuzzing_xpdf/pdf_examples/helloworld.pdf Tagged: no Pages: 1 Encrypted: no Page size: 200 x 200 pts MediaBox: 0.00 0.00 200.00 200.00 CropBox: 0.00 0.00 200.00 200.00 BleedBox: 0.00 0.00 200.00 200.00 TrimBox: 0.00 0.00 200.00 200.00 ArtBox: 0.00 0.00 200.00 200.00 File size: 678 bytes Optimized: no PDF version: 1.7
Install AFL++ 在本课程中,我们将使用最新版本的 AFL++ fuzzer ,您可以通过两种方式安装所有内容:
1 2 3 4 5 6 7 8 9 10 sudo apt-get update # 安装依赖 sudo apt-get install -y build-essential python3-dev automake git flex bison libglib2.0-dev libpixman-1-dev python3-setuptools sudo apt-get install -y lld-11 llvm-11 llvm-11-dev clang-11 || sudo apt-get install -y lld llvm llvm-dev clang sudo apt-get install -y gcc-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-plugin-dev libstdc++-$(gcc --version|head -n1|sed 's/.* //'|sed 's/\..*//')-dev cd $HOME # 安装AFL++ git clone https://github.com/AFLplusplus/AFLplusplus && cd AFLplusplus export LLVM_CONFIG="llvm-config-11" make distrib sudo make install
AFL 是一个 coverage-guided fuzzer ,这意味着它为每个变异的输入收集覆盖信息,以发现新的执行路径和潜在的错误
当源代码可用时,AFL 可以使用插桩,在每个基本块(函数、循环等)的开头插入函数调用
要想我们的目标应用程序启用检测,我们需要使用 AFL 的编译器编译代码
1 2 3 4 5 6 7 8 rm -r $HOME/fuzzing_xpdf/install # 清理所有之前编译的目标文件和可执行文件 cd $HOME/fuzzing_xpdf/xpdf-3.02/ make clean export LLVM_CONFIG="llvm-config-11" # 现在我们将使用afl-clang-fast编译器构建xpdf CC=$HOME/AFLplusplus/afl-clang-fast CXX=$HOME/AFLplusplus/afl-clang-fast++ ./configure --prefix="$HOME/fuzzing_xpdf/install/" make make install
在 AFL 编译文件时候 afl-gcc 会在规定位置插入桩代码,可以理解为一个个的探针(但是没有暂停功能),在后续 fuzz 的过程中会根据这些桩代码进行路径探索,测试等
AFL 通过插桩的形式注入到被编译的程序中,实现对分支(branch、edge)覆盖率的捕获,以及分支节点计数
我们可以使用以下命令测试 pdfinfo 二进制文件:
1 afl-fuzz -i $HOME/fuzzing_xpdf/pdf_examples/ -o $HOME/fuzzing_xpdf/out/ -s 123 -- $HOME/fuzzing_xpdf/install/bin/pdftotext @@ $HOME/fuzzing_xpdf/output
-i :表示我们必须放置输入案例的目录(a.k.a 文件示例)
-o :表示 AFL++ 将存储变异文件的目录-s :表示要使用的静态随机种子@@ :是占位符目标的命令行,AFL 将用每个输入文件名替换
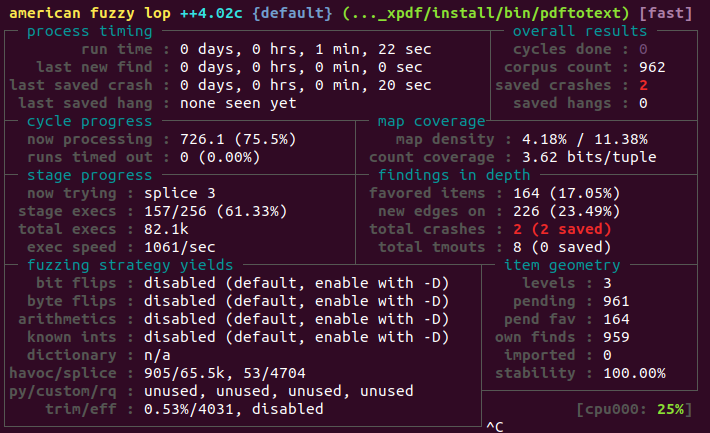
红色的 uniq. crash 值,显示发现的唯一崩溃数
您可以在 $HOME/fuzzing_xpdf/out/ 目录中找到这些崩溃文件
一旦发现第一次崩溃,您就可以停止模糊器,这是我们将要处理的问题(根据您的机器性能,最多可能需要一到两个小时才能发生崩溃)
Do it yourself! 为了完成这个练习,你需要:
用指定的文件重现崩溃
调试 crash 发现问题
修复问题
PS:预计时间 = 120 分钟
通过上一个部分我们已经获取了两个 crash,在 $HOME/fuzzing_xpdf/out/default/crashes 中可以找到:
1 2 3 4 ➜ crashes ls id:000000 ,sig:11 ,src:000000 +000810 ,time:45712 ,execs:44457 ,op:splice,rep:16 id:000001 ,sig:11 ,src:000726 ,time:62396 ,execs:61755 ,op:havoc,rep:2 README.txt
在使用 crash 文件进行调试前,我们需要先了解一下 Xpdf
Xpdf Xpdf 是可移植文档格式 (PDF) 文件的开源查看器(这些有时也被称为“Acrobat”文件,来自 Adobe 的 PDF 软件的名称)
Xpdf 项目还包括 PDF 文本提取器、PDF 到 PostScript 转换器和各种其他实用程序
Xpdf 在 UNIX、VMS 和 OS/2 上的 X 窗口系统下运行,非 X 组件(pdftops、pdftotext 等)也可以在 Win32 系统上运行,并且应该可以在几乎任何具有像样 C++ 编译器的系统上运行
Xpdf 被设计为小巧高效,它可以使用 Type 1 或 TrueType 字体
要运行 Xpdf,只需键入:
要生成 PostScript 文件,请点击 xpdf 中的“打印”按钮,或运行 pdftops:
要生成纯文本文件,请运行 pdftotext:
一共有5个实用程序(在他们的手册页中有完整的描述):
pdftotext — 通过 PDF 文件生成纯文本文件
pdfinfo — 转储 PDF 文件的信息字典(加上其他一些有用的信息)
pdffonts — 列出 PDF 文件中使用的字体以及各种每种字体的信息
pdftops — 将 PDF 文件转换为一系列 PPM/PGM/PBM 格式位图
pdfimages — 从 PDF 文件中提取图像
Reproduce the crash 1 2 3 cp id:000000,sig:11,src:000000+000810,time:45712,execs:44457,op:splice,rep:16 /home/yhellow/fuzzing_xpdf/install/bin cd /home/yhellow/fuzzing_xpdf/install/bin mv id:000000,sig:11,src:000000+000810,time:45712,execs:44457,op:splice,rep:16 test.pdf
依次使用 pdftotext pdfinfo pdffonts pdftops pdfimages 运行测试文件:
1 2 3 4 ➜ bin ./pdftotext test.pdf Error: May not be a PDF file (continuing anyway) Error: PDF file is damaged - attempting to reconstruct xref table... [1] 3065 segmentation fault ./pdftotext test.pdf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ➜ bin ./pdfinfo test.pdf Error: May not be a PDF file (continuing anyway) Error: PDF file is damaged - attempting to reconstruct xref table... Subject: Keywords: Author: Administrator Creator: PDFCreator 2.0.2.0 Producer: Pator 2.0.2.0 CreationDate: Sun Jul 26 00:25:22 2015 ModDate: Sun Jul 26 00:25:22 2015 Tagged: no Pages: 1 Encrypted: no Page size: 595 x 842 pts (A4) File size: 4109 bytes Optimized: no PDF version: 0.0
1 2 3 4 5 6 ➜ bin ./pdffonts test.pdf Error: May not be a PDF file (continuing anyway) Error: PDF file is damaged - attempting to reconstruct xref table... name type emb sub uni object ID ------------------------------------ ----------------- --- --- --- --------- Times-Roman
1 2 3 4 ➜ bin ./pdftops test.pdf Error: May not be a PDF file (continuing anyway) Error: PDF file is damaged - attempting to reconstruct xref table... [1] 3141 segmentation fault ./pdftops test.pdf
1 2 3 4 ➜ bin ./pdfimages test.pdf test Error: May not be a PDF file (continuing anyway) Error: PDF file is damaged - attempting to reconstruct xref table... [1] 3236 segmentation fault ./pdfimages test.pdf test
其中 pdftotext pdftops pdfimages 出现了段错误
我们先用 GDB 调试 pdftotext:
1 gdb --args ./pdftotext ./test.pdf
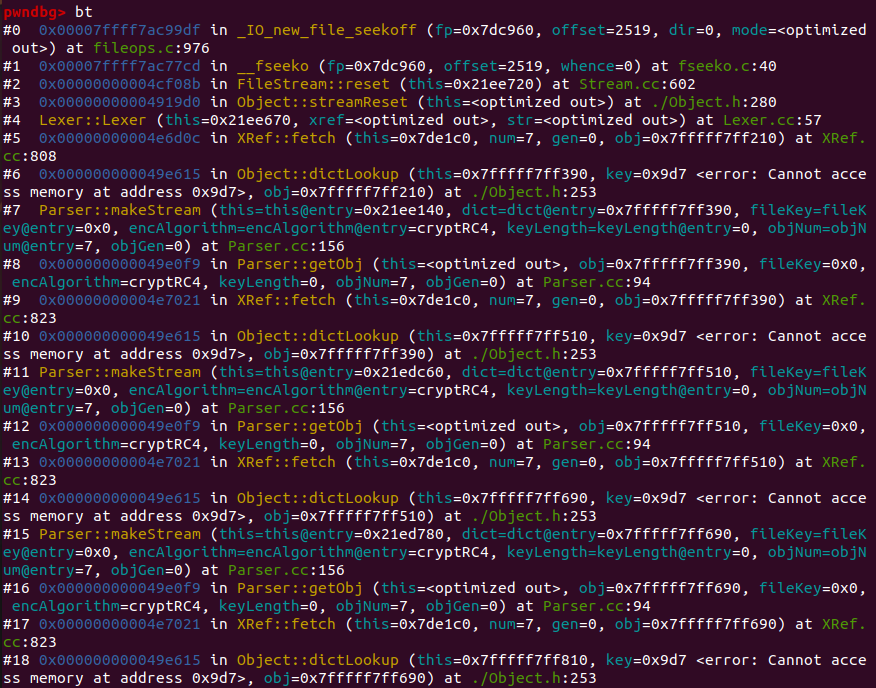
发现程序的行为异常,不断调用 Object::dictLookup Parser::makeStream Parser::getObj XRef::fetch,程序无限递归最终崩溃(经过测试,pdftops pdfimages 中的段错误也是这个原因)
我们在 Object::dictLookup Parser::makeStream Parser::getObj XRef::fetch 处打上断点,配合源码用 GDB 单步调试:
1 Parser::getObj(若干次) -> Parser::makeStream -> Object::dictLookup -> XRef::fetch
分析 Parser::makeStream -> Object::dictLookup:
1 2 3 4 5 6 7 8 9 dict->dictLookup("Length" , &obj); if (obj.isInt()) { length = (Guint)obj.getInt(); obj.free (); } else { error(getPos(), "Bad 'Length' attribute in stream" ); obj.free (); return NULL ; }
分析 Object::dictLookup -> XRef::fetch:
1 2 3 4 5 6 7 8 inline Object *Object::dictLookup (char *key, Object *obj) { return dict->lookup(key, obj); }Object *Dict::lookup (char *key, Object *obj) { DictEntry *e; return (e = find(key)) ? e->val.fetch(xref, obj) : obj->initNull(); }
分析 XRef::fetch -> Parser::getObj:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 parser->getObj(&obj1); parser->getObj(&obj2); parser->getObj(&obj3); if (!obj1.isInt() || obj1.getInt() != num || !obj2.isInt() || obj2.getInt() != gen || !obj3.isCmd("obj" )) { obj1.free (); obj2.free (); obj3.free (); delete parser; goto err; } parser->getObj(obj, encrypted ? fileKey : (Guchar *)NULL , encAlgorithm, keyLength, num, gen); obj1.free (); obj2.free (); obj3.free ();
分析 Parser::getObj -> Parser::getObj:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 while (!buf1.isCmd(">>" ) && !buf1.isEOF()) { if (!buf1.isName()) { error(getPos(), "Dictionary key must be a name object" ); shift(); } else { key = copyString(buf1.getName()); shift(); if (buf1.isEOF() || buf1.isError()) { gfree(key); break ; } obj->dictAdd(key, getObj(&obj2, fileKey, encAlgorithm, keyLength, objNum, objGen)); } }
分析 Parser::getObj -> Parser::makeStream:
1 2 3 if (allowStreams && buf2.isCmd("stream" )) { if ((str = makeStream(obj, fileKey, encAlgorithm, keyLength, objNum, objGen)))
从整个调用链来看,程序的运行逻辑就是闭合的,可能作者需要这种递归调用来完成一些工作,盲猜作者在涉及调用条件时出现了一些问题:
Parser::makeStream -> Object::dictLookup 和 Object::dictLookup -> XRef::fetch 都是无条件调用,这里应该不会出现问题XRef::fetch 中调用了4次 getObj,Parser::getObj 中通过多次调用 dictAdd 来调用 getObj,但它们的调用都是有条件的,如果某一次的传入的 Object 结构体设置不对,就可能导致无限调用
下载 4.02 版本代码,对比 Parser.cc,可以看到此漏洞被修复: