d3kheap 复现
1 | ➜ rootfs cat init |
1 | ➜ d3kheap cat run.sh |
- 开了 kaslr
- 用了2个核心,2个线程(限制线程数量,可能有条件竞争)
命令定义:
1 | void __fastcall d3kheap_ioctl(__int64 fd, __int64 command) |
- 定义了两个命令
add(0x1234) 和free(0xDEAD) add只能申请 0x400 大小的空间(从逻辑上来讲只能执行一次)free会根据ref_count判断是否执行 kfree(),但是ref_count被初始化为“1”- 并且有一个自旋锁
漏洞分析:
1 | if ( ref_count ) |
1 | .data:0000000000000C00 01 00 00 00 ref_count dd 1 |
- 本程序有 UAF,并且 ref_count 被设置为“1”
- 第一次执行
add时,ref_count 会变为“2”,也就是说可以free两次
入侵思路:
我的第一反应是 glibc pwn 中的 Double free,slub 中的检查和 fastbin 中的相同(会检查 freelist 指向的第一个 object),绕不过去
kernel pwn 中的很多利用都要依靠 结构体,比如:tty_struct->tty_operations 中的虚表,subprocess_info 的 cleanup 指针,但在此之前,必须先绕过 kaslr(泄露内核基地址)
大佬使用了 CVE-2021-22555 的堆喷 msg_msg 与 sk_buff 的解法,在学习这个方法之前需要一些前置知识:
msg_msg
1 | struct msg_msg { |
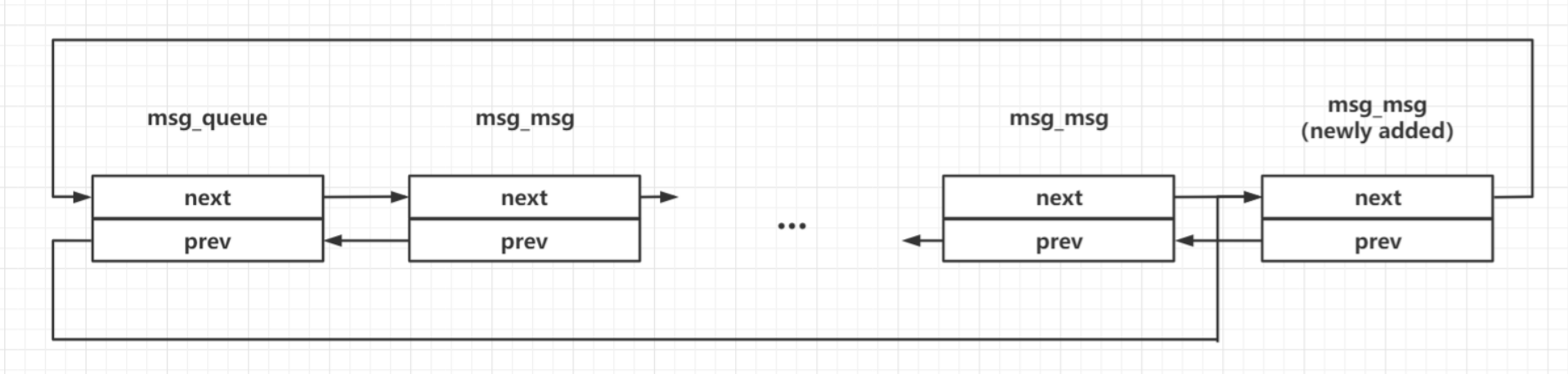
当我们在一个消息队列上发送多个消息时,会形成如下结构:(msg 双向链表)
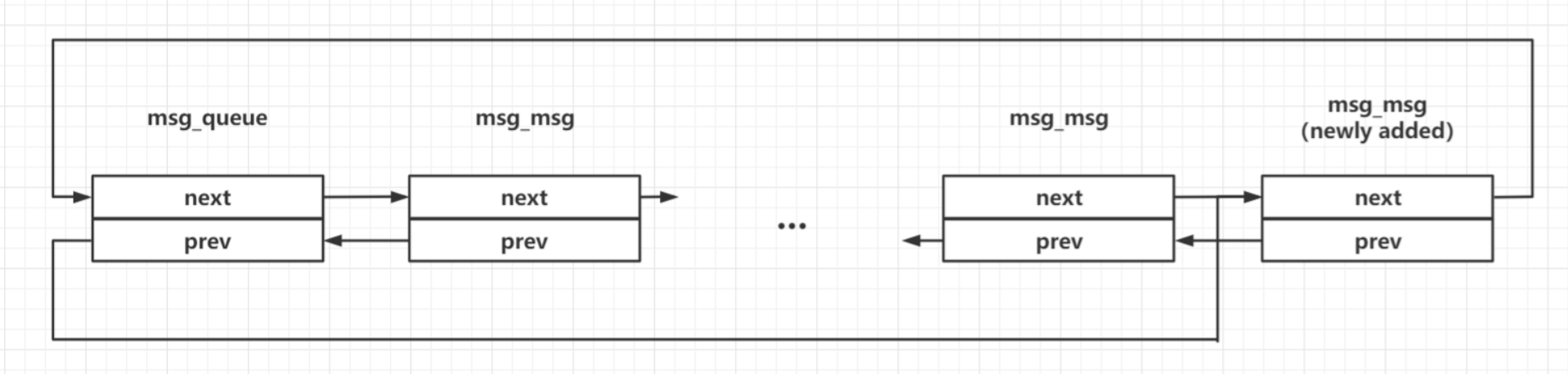
- 消息队列,Unix 的通信机制之一,可以理解为是一个存放消息(数据)容器
- 将消息写入消息队列,然后再从消息队列中取消息,一般来说是先进先出 FIFO 的顺序
虽然 msg_queue 的大小基本上是固定的,但是 msg_msg 作为承载消息的本体 其大小是可以随着消息大小的改变而进行变动的:
- 去除掉
msg_msg结构体本身的 0x30 字节的部分(或许可以称之为 header)剩余的部分都用来存放用户数据 - 因此内核分配的 object 的大小是跟随着我们发送的 message 的大小进行变动的
而当我们单次发送大于 [一个页面大小 - header size] 大小的消息时,内核会额外补充添加 msg_msgseg 结构体(只有一个 next 指针),其与 msg_msg 之间形成如下单向链表结构:
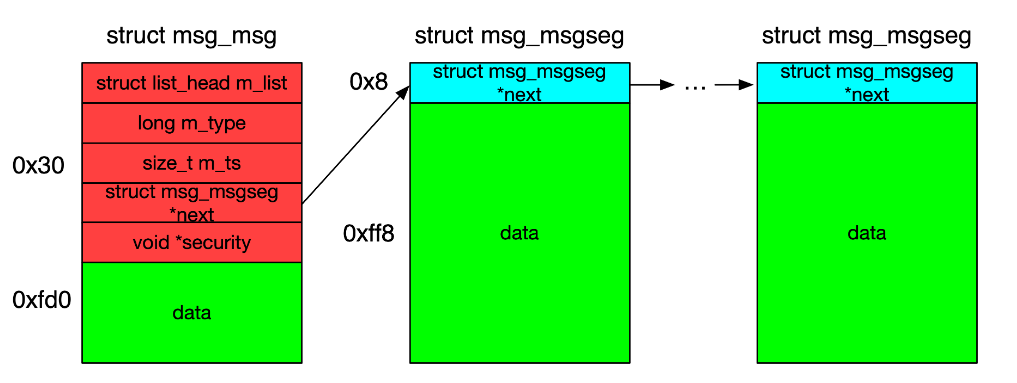
- 同样地,单个
msg_msgseg的大小最大为一个页面大小,因此超出这个范围的消息内核会额外补充上更多的msg_msgseg结构体 - 在读取
msg_msg中的数据时,如果msg_msg->next不为空,程序就会把msg_msg->next指向的内容也当做是msg_msg data的一部分,如果msg_msgseg->next还不为空,就会继续读取msg_msgseg->next指向的内容
利用:
- 在拷贝数据时对长度的判断主要依靠的是
msg_msg->m_ts,若是我们能够控制一个 msg_msg 的 header,将其msg_msg->m_ts成员改为一个较大的数,我们就能够越界读取出最多将近一张内存页大小的数据 - 若是我们能够同时劫持
msg_msg->m_ts与msg_msg->next,我们便能够完成内核空间中的任意地址读(msg_msg->next指向的数据也会被当做msg_msg data)- 但这个方法有一个缺陷,无论是
MSG_COPY还是常规的接收消息,其拷贝消息的过程的判断主要依据还是单向链表的 next 指针,因此若我们需要完成对特定地址向后的一块区域的读取,我们需要保证该地址的数据为 NULL
- 但这个方法有一个缺陷,无论是
相关接口:
1 | // 创建和获取ipc内核对象 |
- msqid:消息队列的标识符,代表要从哪个消息列中获取消息
- msgp: 存放消息结构体的地址(需要自己定义:
long type+char data[n]) - msgsz:消息正文的字节数
- msgtyp:消息的类型,可以有以下几种类型:
- msgtyp = 0:返回队列中的第一个消息
- msgtyp > 0:返回队列中消息类型为 msgtyp 的消息(常用)
- msgtyp < 0:返回队列中消息类型值小于或等于 msgtyp 绝对值的消息,如果这种消息有若干个,则取类型值最小的消息
- msgflg:函数的控制属性,其取值如下:
- 0:msgrcv() 调用阻塞直到接收消息成功为止
- MSG_NOERROR:若返回的消息字节数比 nbytes 字节数多,则消息就会截短到 nbytes 字节,且不通知消息发送进程
- MSG_COPY:读取但不释放,当我们在调用 msgrcv 接收消息时,相应的 msg_msg 链表便会被释放,当我们在调用 msgrcv 时若设置了
MSG_COPY标志位,则内核会将 message 拷贝一份后再拷贝到用户空间,原双向链表中的 message 并不会被 unlink - IPC_NOWAIT:调用进程会立即返回,若没有收到消息则立即返回 -1
案例:
1 |
|
1 | ➜ exp ./test |
socketpair
1 | int socketpair(int d, int type, int protocol, int sv[2]); |
- socketpair() 函数用于创建一对无名的、相互连接的套接子(有点类似于管道)
- 如果函数成功,则返回 “0”,创建好的套接字分别是 sv[0] 和 sv[1]
- 否则返回 “-1”,错误码保存于 errno 中
基本用法:
- 这对套接字可以用于全双工通信,每一个套接字既可以读也可以写(例如,可以往 sv[0] 中写,从 sv[1] 中读,或者从 sv[1] 中写,从 sv[0] 中读)
- 如果往一个套接字(sv[0])中写入后,再从该套接字读时会阻塞,只能在另一个套接字中(sv[1])上读成功
- 读、写操作可以位于同一个进程,也可以分别位于不同的进程,如父子进程,如果是父子进程时,一般会功能分离,一个进程用来读,一个用来写(因为文件描述副 sv[0] 和 sv[1] 是进程共享的,所以读的进程要关闭写描述符,反之,写的进程关闭读描述符)
案例:
1 |
|
1 | ➜ exp ./test |
- 可以发现原 str 改变以后,buf 并没有改变,也就是说 socketpair 底层的存储方式不是指针,数据传入
socket_pair[0-1][1]时就被复制了一份 - 那么
socket_pair[0-1][1]中的数据是储存到哪里的呢?
1 | pwndbg> search -s aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa |
- heap 上没有,那就极有可能在 kernel heap 中
sk_buff
结构体 sk_buff 的源码很长,但这里我们只需要注意以下片段:
1 | struct sk_buff { |
sk_buff(socket buffer)结构是 linux 网络代码中重要的数据结构,它管理和控制接收或发送数据包的信息- 类似于
msg_msg,其同样可以提供近乎任意大小对象的分配写入与释放,但不同的是:msg_msg由一个 header 加上用户数据组成- 而
sk_buff本身不包含任何用户数据,用户数据单独存放在一个 object 当中,而sk_buff中存放指向用户数据的指针
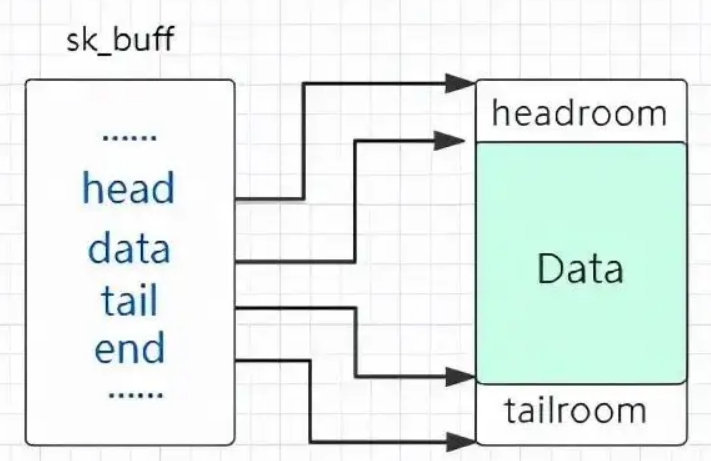
- sk_buff 在内核网络协议栈中代表一个「包」,我们只需要创建一对 socke,在上面发送与接收数据包就能完成 sk_buff 的分配与释放
- 最简单的办法便是用 socketpair 系统调用创建一对 socket,之后对其 read & write 便能完成收发包的工作
pipe_buffer
1 | struct pipe_buffer { |
- 当我们创建一个管道时,在内核中会生成数个连续的
pipe_buffer结构体,申请的内存总大小刚好会让内核从 kmalloc-1k 中取出一个 object - 在
pipe_buffer中存在一个函数表成员pipe_buf_operations,其指向内核中的函数表anon_pipe_buf_ops,若我们能够将其读出,便能泄露出内核基址
PS:因为本人太菜,所以第一遍只能跟着大佬的 exp 做阅读理解……
Step.I 堆喷 msg_msg,建立主从消息队列
1 | for (int i = 0; i < MSG_QUEUE_NUM; i++) |
堆喷多个消息队列,并分别在每一个消息队列上发送两条消息,形成如下内存布局:
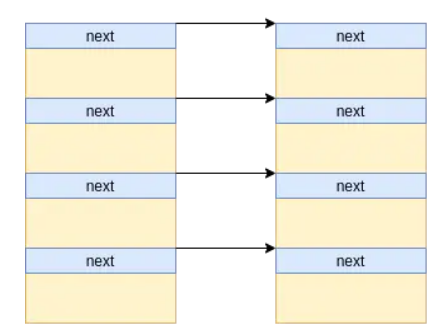
- 第一条消息(主消息)的大小为 96
- 第二条消息(辅助消息)的大小为 0x400
- 此时我们的辅助消息便有极大的概率获取到之前释放的 object
Step.II 构造 UAF,堆喷 sk_buff 定位 victim 队列
虽然辅助消息有极大的概率获取到之前释放的 object,但是我们并不知道是哪一个辅助消息获取了 object(一共有 4096 个辅助消息)
可以通过堆喷 sk_buff 定位 victim 队列,而 sk_buff 的分配与释放则靠 socketpair 完成
1 | int spraySkBuff(int sk_socket[SOCKET_NUM][2], void *buf, size_t size) |
1 | del(); /* 释放这个object,然后就会被socketpair申请的kernel heap占用 */ |
- 因为 socketpair 使用的也是 kernel heap 的空间,所以前面释放的 object 可能被 sk_buff 分配的空间占用(此时 object 仍然在被 secondary_msg 使用)
- 获取了 object 的辅助消息被修改为 fake_secondary_msg 后,所以使用 MSG_COPY flag 进行消息拷贝时便会失败
- 因此我们可以通过判断是否读取消息失败,来定位命中 UAF 的消息队列
Step.III 堆喷 sk_buff 伪造辅助消息,泄露 UAF obj 地址
用同样的方法,将辅助消息被修改为 fake_secondary_msg,使 msg_msg->m_ts 变为一个较大值,从而越界读取到相邻辅助消息的 header(msg_msg),泄露出堆上地址
为了捕获正确的 msg_msg,前面设置的 MSG_TAG 标志位就有作用了
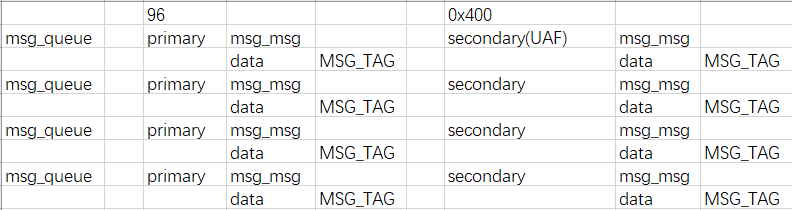
- 由于 slub 算法的特性,kmalloc-1k 会被分配到相邻的内存空间,kmalloc-96 会被分配到相邻的内存空间,两者互不干扰
- msg_queue,primary,secondary 通过
primary_msg->m_list与secondary_msg->m_list相关联
1 | buildMsg((struct msg_msg *)fake_secondary_msg, *(uint64_t*)"yhellow", *(uint64_t*)"yhellow", VICTIM_MSG_TYPE, 0x1000 - sizeof(struct msg_msg), 0, 0); |
- 越界读取到相邻辅助消息的 header,泄露对应主消息的地址
- 注意:同样是修改
msg_msg,上一个peekMsg就报错了,这里的peekMsg没有报错,目前不知道原因
1 | if (freeSkBuff(sk_sockets, fake_secondary_msg, sizeof(fake_secondary_msg)) < 0) |
- 在
msg_msg data的 0x1000-0x30 空间使用完毕后,程序就会根据msg_msg->next来确定msg_msgseg data的位置 - 将
msg_msg->next修改为primary->header,就可以读取并泄露primary->m_list.next,也就是secondary->header - 最后减去 0x400 就得到 victim_addr 了
Step.IV 堆喷 pipe_buffer,泄露内核基址
第二条消息(辅助消息)的大小为 0x400,刚好可以申请 pipe_buffer,它既能帮我们泄露内核代码段基址,也能帮我们劫持 RIP
1 | if (freeSkBuff(sk_sockets, fake_secondary_msg, sizeof(fake_secondary_msg)) < 0) |
- readMsg 没有设置 MSG_COPY,读取后便会从信息队列中释放 secondary,但是 sk_buff 中的指针并没有置空,也就是说,pipe_buffer 和 sk_buff 分配的区域在同一位置
- 所以接下来的 read sk_sockets 会把 pipe_buffer 读到 fake_secondary_msg 中
- 最后通过
pipe_buffer->ops获取内核偏移地址
Step.V 伪造 pipe_buffer,构造 ROP,劫持 RIP,完成提权
当我们关闭了管道的两端时,会触发 pipe_buffer->pipe_buf_operations->release 这一指针
而 UAF object 的地址对我们而言是已知的,因此我们可以直接利用 sk_buff 在 UAF object 上伪造函数表与构造 ROP chain,再选一条足够合适的 gadget 完成栈迁移便能劫持 RIP 完成提权
1 | pipe_buf_ptr = (struct pipe_buffer *) fake_secondary_msg; |
- 标准的 ret2usr,利用 commit_creds(prepare_kernel_cred(0)) 进行提取
- 在 gadget 上打断点,进行调试:
1 | ────────────────────────────────────────────────────────────────────────────────── |
- 寄存器 RSI 中就是我们布置的 ROP 链
1 | pwndbg> telescope 0xffff9799c2864800 |
完整 exp:
1 |
|
小结:
太菜了,只能对着别人的 wp 进行调试,不过还是学到了不少东西:
msg_msg,sk_buff的组合利用- 两种关于
msg_msg的泄露技巧(修改msg_msg->m_ts或者msg_msg->next) - 利用
pipe_buffer泄露内核基地址,或者劫持RIP
补充:
我仿照官方 exp 又自己打了一边,发现了许多之前没有理解的细节问题(改BUG真辛苦),接下来补充一些内容:
1 | buildMsg((struct msg_msg *)fake_secondary_msg, *(uint64_t*)"yhellow", *(uint64_t*)"yhellow", VICTIM_MSG_TYPE, SECONDARY_MSG_SIZE, 0, 0); |
1 | buildMsg((struct msg_msg *)fake_secondary_msg, *(uint64_t*)"yhellow", *(uint64_t*)"yhellow", VICTIM_MSG_TYPE, 0x1000 - sizeof(struct msg_msg), 0, 0); |
- 第一个
peekMsg因为修改了msg->m_ts而报错 - 第二个
peekMsg也修改了msg->m_ts但是没有报错
刚开始以为是:
msg->m_ts大于sizeof(secondary_msg)导致secondary_msg溢出,而后续的sizeof(oob_msg)足够大,不会溢出
后来又发现了新的内容:
- 这里修改了
msg->m_list也是有影响的:- 设置了
MSG_COPY标志位,内核会将 message 拷贝一份后再拷贝到用户空间,原双向链表中的 message 并不会被 unlink - 如果没有设置
MSG_COPY,则我们随便设置的msg->m_list一定会在 unlink 时报错
- 设置了
1 | peekMsg(msqid[i],&secondary_msg,sizeof(secondary_msg),1); |
之前提到过:msgtyp > 0 ,返回队列中消息类型为 msgtyp 的消息:
readMsg使用VICTIM_MSG_TYPE来获取对应的 UAF(遵守了这样的规则)peekMsg使用的msgtyp都是“1”(并且非“1”不可)- 这里还有点搞不懂,首先我把接收的数据打印出来,确定了
msgtyp的确是SECONDARY_MSG_TYPE,但把msgtyp改为SECONDARY_MSG_TYPE后反而接收不了数据了,然后我尝试修改SECONDARY_MSG_TYPE的值,发现并不影响结果,我感觉这是内核版本的问题(之后找机会看看源码)
1 | int spraySkBuff(int sk_socket[SOCKET_NUM][2], void *buf, size_t size) |
这里调用多次调用 write 和 read 是为了提高 sk_buff 命中 UAF 的概率
- PS:后面泄露 kernel_base 的时候一定要 read 所有的
sk_buff(sk_buff读取后释放),不然之后的spraySkBuff会因为sk_buff存在而 write 失败,从而导致程序卡住