Jemalloc 安装&使用 jemalloc 是 Facebook 推出的一种通用 malloc 实现,在 FreeBSD、firefox 中被广泛使用,比起 ptmalloc2 具有更高的性能
编译安装
1 2 3 4 5 wget https://github.com/jemalloc/jemalloc/releases/download/5.0.1/jemalloc-5.0.1.tar.bz2 tar -xjvf jemalloc-5.0.1.tar.bz2 cd jemalloc-5.0.1 ./configure --prefix=/usr/local/jemalloc --enable-debug make -j4 && sudo make install
接下来修改链接信息:
1 2 3 4 sudo bash echo /usr/local/jemalloc/ >> /etc/ld.so.conf.d/jemalloc.conf echo /usr/local/lib >> /etc/ld.so.conf ldconfig
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> #include <jemalloc/jemalloc.h> void jemalloc_test (int i) malloc (i*100 ); } int main (int argc, char **argv) int i; for (i=0 ;i<1000 ;i++) { jemalloc_test(i); } malloc_stats_print(NULL ,NULL ,NULL ); return 0 ; }
使用 GCC 进行编译:
1 gcc jemalloc.c -o jemalloc -ljemalloc
演示:
1 2 3 4 5 6 7 8 9 10 11 ➜ exp gcc test.c -o jemalloc -ljemalloc ➜ exp ldd jemalloc linux-vdso.so.1 (0x00007fff753f8000 ) libjemalloc.so.2 => /usr/local/lib/libjemalloc.so.2 (0x00007f6caa002000 ) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f6ca9e10000 ) libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f6ca9bf6000 ) libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f6ca9bd3000 ) libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f6ca9bcd000 ) libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f6ca9bb0000 ) /lib64/ld-linux-x86-64. so.2 (0x00007f6caa2a6000 ) libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f6ca9a61000 )
对于 Jemalloc 堆的调试,最好使用 shadow:
CENSUS/shadow: jemalloc heap exploitation framework (github.com)
使用 GDB 查看 Jemalloc 内存布局
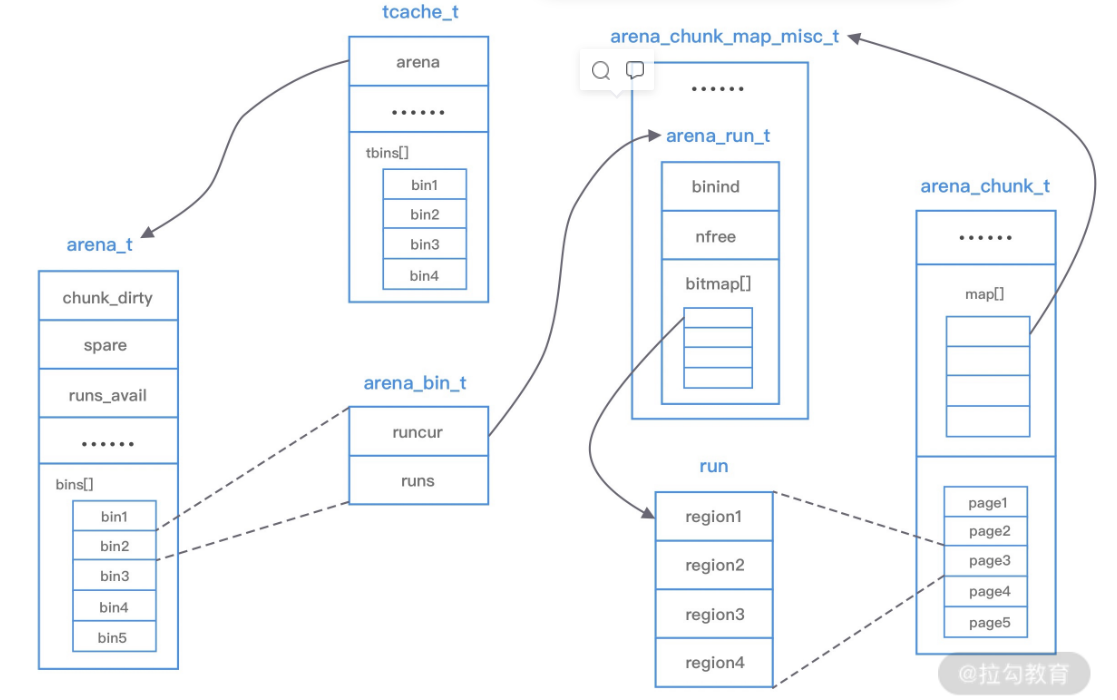
Jemalloc 架构设计 上图中涉及 jemalloc 的几个核心概念,例如 arena、bin、chunk、run、region、tcache 等,我们下面逐一进行介绍:
arena 是 jemalloc 最重要的部分 ,内存由一定数量的 arenas 负责管理,每个用户线程都会被绑定到一个 arena 上,线程采用 round-robin 轮询的方式选择可用的 arena 进行内存分配,为了减少线程之间的锁竞争,默认每个 CPU 会分配 4 个 arenabin 用于管理不同档位的内存单元 ,每个 bin 管理的内存大小是按分类依次递增,因为 jemalloc 中小内存的分配是基于 Slab 算法完成的,所以会产生不同类别的内存块chunk 是负责管理用户内存块的数据结构 ,chunk 以 Page 为单位管理内存,默认大小是 4M,即 1024 个连续 Page,每个 chunk 可被用于多次小内存的申请,但是在大内存分配的场景下只能分配一次run 实际上是 chunk 中的一块内存区域 ,每个 bin 管理相同类型的 run,最终通过操作 run 完成内存分配,run 结构具体的大小由不同的 bin 决定(例如 8 字节的 bin 对应的 run 只有一个 Page,可以从中选取 8 字节的块分配给 regions)region 是每个 run 中的对应的若干个小内存块 ,每个 run 会将划分为若干个等长的 region,每次内存分配也是按照 region 进行分发tcache 是每个线程私有的缓存 ,用于 small 和 large 场景下的内存分配,每个 tcahe 会对应一个 arena,tcache 本身也会有一个 bin 数组,称为tbin,与 arena 中 bin 不同的是,它不会有 run 的概念,tcache 每次从 arena 申请一批内存,在分配内存时首先在 tcache 查找,从而避免锁竞争,如果分配失败才会通过 run 执行内存分配
重新梳理下它们之间的关系:
内存是由一定数量的 arenas 负责管理,线程均匀分布在 arenas 当中
每个 arena 都包含一个 bin 数组,每个 bin 管理不同档位的内存块
每个 arena 被划分为若干个 chunks,每个 chunk 又包含若干个 runs,每个 run 由连续的 Page 组成,run 才是实际分配内存的操作对象
每个 run 会被划分为一定数量的 regions,在小内存的分配场景,region 相当于用户内存
每个 tcache 对应 一个 arena,tcache 中包含多种类型的 bin
简单来说:首先是 arena 是最顶层的,会有多个 arena 结构(一般是一个线程对应一个),arena 内储存 chunk,每个 chunk 大小为 4M,chunk 被分为 run,run 内是 region(用户分配到的数据)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Chunk .--------------------------------. .--------------------------------. | Run #0 Run #1 | | Run #0 Run #1 | | .-------------..-------------. | | .-------------..-------------. | | | Page || Page | | | | Page || Page | | | | .---------. || .---------. | | | | .---------. || .---------. | | | | | Regions | || | Regions | | | | | | Regions | || | Regions | | | ... | |[] [] [] | || |[] [] [] | | | | | |[] [] [] | || |[] [] [] | | || | `- |----- |-' || `---------' | | | | `- |----- |-' || `---------' | | | `--- |----- |---'`-------------' | | `--- |----- |---'`-------------' | `-----|----- |--------------------' `----- |----- |--------------------' | | | | .---|----- |----------. .--- |----- |----------. | free regions' tree | ... | free regions' tree | ... `--------------------' `--------------------' bin[Chunk #0][Run #0] bin[Chunk #1][Run #0]
Jemalloc 数据结构 arena_t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 typedef struct arena_s arena_t ;struct arena_s {#ifdef JEMALLOC_DEBUG uint32_t magic; # define ARENA_MAGIC 0x947d3d24 #endif unsigned ind; unsigned nthreads; malloc_mutex_t lock; #ifdef JEMALLOC_STATS arena_stats_t stats; # ifdef JEMALLOC_TCACHE ql_head(tcache_t ) tcache_ql; # endif #endif #ifdef JEMALLOC_PROF uint64_t prof_accumbytes; #endif ql_head(arena_chunk_t ) chunks_dirty; arena_chunk_t *spare; size_t nactive; size_t ndirty; size_t npurgatory; arena_avail_tree_t runs_avail_clean; arena_avail_tree_t runs_avail_dirty; arena_bin_t bins[1 ]; };
arena_chunk_t
1 2 3 4 5 6 7 8 9 10 11 12 typedef struct arena_chunk_s arena_chunk_t ;struct arena_chunk_s { arena_t *arena; ql_elm(arena_chunk_t ) link_dirty; bool dirtied; size_t ndirty; arena_chunk_map_t map [1 ]; };
用于描述 Chunk 的结构体
块映射与块的内存对齐结合的主要用途是:实现对空闲和大/小堆分配(区域)的管理元数据的恒定时间访问
arena_bin_t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 typedef struct arena_bin_s arena_bin_t ;struct arena_bin_s { malloc_mutex_t lock; arena_run_t *runcur; arena_run_tree_t runs; #ifdef JEMALLOC_STATS malloc_bin_stats_t stats; #endif };
用于描述 Bins 的结构体
每个 bin 都有一个关联的大小类别,并存储/管理该类别的区域大小类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 pwndbg> telescope 0x7ffff7800c30 00 :0000 │ 0x7ffff7800c30 ◂— 0x0 01 :0008 │ 0x7ffff7800c38 ◂— 0x0 02 :0010 │ 0x7ffff7800c40 ◂— 0x200 03 :0018 │ 0x7ffff7800c48 ◂— 0x0 04 :0020 │ 0x7ffff7800c50 ◂— 0x0 05 :0028 │ 0x7ffff7800c58 —▸ 0x7ffff7006000 ◂— 0x384adf93 06 :0030 │ 0x7ffff7800c60 —▸ 0x7ffff7800c68 ◂— 0x7ffff7800c68 07 :0038 │ 0x7ffff7800c68 ◂— 0x7ffff7800c68 pwndbg> p (arena_bin_t )*0x7ffff7800c30 $5 = { lock = { __data = { __lock = 0 , __count = 0 , __owner = 0 , __nusers = 0 , __kind = 512 , __spins = 0 , __elision = 0 , __list = { __prev = 0x0 , __next = 0x0 } }, __size = '\000' <repeats 17 times>, "\002" , '\000' <repeats 21 times>, __align = 0 }, runcur = 0x7ffff7006000 , runs = { rbt_root = 0x7ffff7800c68 , rbt_nil = { u = { rb_link = { rbn_left = 0x7ffff7800c68 , rbn_right_red = 0x7ffff7800c68 }, ql_link = { qre_next = 0x7ffff7800c68 , qre_prev = 0x7ffff7800c68 } }, bits = 0 } } }
arena_bin_info_t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 typedef struct arena_bin_info_s arena_bin_info_t ;struct arena_bin_info_s { size_t reg_size; size_t run_size; uint32_t nregs; uint32_t bitmap_offset; bitmap_info_t bitmap_info; #ifdef JEMALLOC_PROF uint32_t ctx0_offset; #endif uint32_t reg0_offset; };
arena_run_t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct arena_run_s arena_run_t ;struct arena_run_s {#ifdef JEMALLOC_DEBUG uint32_t magic; # define ARENA_RUN_MAGIC 0x384adf93 #endif arena_bin_t *bin; uint32_t nextind; unsigned nfree; unsigned regs_mask[]; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 pwndbg> telescope 0x7ffff7006000 00 :0000 │ 0x7ffff7006000 ◂— 0x384adf93 01 :0008 │ 0x7ffff7006008 —▸ 0x7ffff7800c30 ◂— 0x0 02 :0010 │ 0x7ffff7006010 ◂— 0xfa00000002 03 :0018 │ 0x7ffff7006018 ◂— 0xfffffffffffffffc 04 :0020 │ 0x7ffff7006020 ◂— 0xffffffffffffffff 05 :0028 │ 0x7ffff7006028 ◂— 0xffffffffffffffff 06 :0030 │ 0x7ffff7006030 ◂— 0xfffffffffffffff 07 :0038 │ 0x7ffff7006038 ◂— 0xf pwndbg> p (arena_run_t )*0x7ffff7006000 $4 = { magic = 944430995 , bin = 0x7ffff7800c30 , nextind = 2 , nfree = 250 }
extent_node_t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 typedef struct extent_node_s extent_node_t ;struct extent_node_s {#if (defined(JEMALLOC_SWAP) || defined(JEMALLOC_DSS)) rb_node(extent_node_t ) link_szad; #endif rb_node(extent_node_t ) link_ad; #ifdef JEMALLOC_PROF prof_ctx_t *prof_ctx; #endif void *addr; size_t size; };
huge 的分配由 “extent_node_t” 结构表示,在所有线程共有的全局红黑树中排序
“extent_node_t” 结构分配在称为基节点的小内存区域中
基本节点不会影响最终用户堆分配的布局,因为它们由 DSS 或由 “mmap()” 获取的单个内存映射提供服务
用于分配空闲空间的实际方法取决于 jemalloc 是如何编译的,而 “mmap()” 是默认值
Regions/Allocations
Jemalloc 实际分配给用户的内存空间就是 Regions,根据 Regions 的大小,可以把它区分为3个种类:
下图总结了到目前为止我们对 jemalloc 的分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 .----------------------------------. .---------------------------. .----------------------------------. | +--+-----> arena_chunk_t | .---------------------------------. | | | | | | arena_t | | | | | .---------------------. | | | | | | | | | | | .--------------------. | | | | | | arena_run_t | | | | arena_chunk_t list |-----+ | | | | | | | | | `--------------------' | | | | | | | .-----------. | | | | | | | | | | | page | | | | arena_bin_t bins[]; | | | | | | | +-----------+ | | | .------------------------. | | | | | | | | region | | | | | bins[0] ... bins[27] | | | | | | | | +-----------+ | | | `------------------------' | | |.' | | | | region | | | | | | |.' | | | +-----------+ | | `-----+----------------------+----' | | | | region | | | | | | | | +-----------+ | | | | | | | . . . | | | v | | | .-----------. | | | .-------------------. | | | | page | | | | | .---------------. | | | | +-----------+ | | | | | arena_chunk_t |-+---+ | | | region | | | | | `---------------' | | | +-----------+ | | | [2-5] | .---------------. | | | | region | | | | | | arena_chunk_t | | | | +-----------+ | | | | `---------------' | | | | region | | | | | . . . | | | +-----------+ | | | | .---------------. | | | | | | | | arena_chunk_t | | | `---------------------' | | | `---------------' | | [2-6] | | | . . . | | .---------------------. | | `-------------------' | | | | | +----+--+---> arena_run_t | | | | | | | | +----------+ | | | .-----------. | | | | | | | page | | | | | | | +-----------+ | | | | | | | region | | | v | | | +-----------+ | | .--------------------------. | | | | region | | | | arena_bin_t | | | | +-----------+ | | | bins[0] (size 8) | | | | | region | | | | | | | | +-----------+ | | | .----------------------. | | | | . . . | | | | arena_run_t *runcur; |-+---------+ | | .-----------. | | | `----------------------' | | | | page | | | `--------------------------' | | +-----------+ | | | | | region | | | | | +-----------+ | | | | | region | | | | | +-----------+ | | | | | region | | | | | +-----------+ | | | | | | | `---------------------' | `---------------------------'
Jemalloc 分配机制 Jemalloc 把内存分配分为了 三个部分 :
第一部分类似 tcmalloc,是分别以8字节,16字节,64字节 …… 等分隔开的 small class
第二部分以分页为单位,等差间隔开的 large class
然后就是 huge class
内存块的管理也通过一种 chunk 进行,一个 chunk 的大小是 2^k (默认4 MB),通过这种分配实现常数时间地分配 small 和 large 对象,对数时间地查询 huge 对象的 meta(使用红黑树)
默认64位系统的划分方式如下:
Small: [8],[16,32,48,…,128](16字节等分),[128,192,256,320, …,512](64字节等分),[512,768,1024,1280,…,3840](256字节等分)Large: [4 KB, 8 KB, 12 KB,…, 4072 KB](4KB 等分,一页等分)Huge: [4 MB, 8 MB, 12 MB,…](大于 4MB 的超大内存)
接下来我们分析下 jemalloc 的整体内存分配和释放流程,主要分为 Samll 、Large 和 Huge 三种场景:
Small 场景
如果请求分配内存的大小小于 arena 中的最小的 bin,那么优先从线程中对应的 tcache 中进行分配
首先确定查找对应的 tbin 中是否存在缓存的内存块,如果存在则分配成功,否则找到 tbin 对应的 arena
从 arena 中对应的 bin 中分配 region 保存在 tbin 的 avail 数组中,最终从 availl 数组中选取一个地址进行内存分配,当内存释放时也会将被回收的内存块进行缓存
Large 场景
Large 的内存分配与 Samll 类似,如果请求分配内存的大小大于 arena 中的最小的 bin,但是不大于 tcache 中能够缓存的最大块,依然会通过 tcache 进行分配,但是不同的是此时会分配 chunk 以及所对应的 run,从 chunk 中找到相应的内存空间进行分配
内存释放时也跟 samll 场景类似,会把释放的内存块缓存在 tacache 的 tbin 中
此外还有一种情况,当请求分配内存的大小大于 tcache 中能够缓存的最大块,但是不大于 chunk 的大小,那么将不会采用 tcache 机制,直接在 chunk 中进行内存分配
Huge 场景
如果请求分配内存的大小大于 chunk 的大小,那么直接通过 mmap 进行分配,调用 munmap 进行回收
分配流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 MALLOC(size): IF size CAN BE SERVICED BY AN ARENA: IF size IS SMALL OR MEDIUM: bin = get_bin_for_size(size) IF bin->runcur EXISTS AND NOT FULL: run = bin->runcur ELSE: run = lookup_or_allocate_nonfull_run() bin->runcur = run bit = get_first_set_bit(run->regs_mask) region = get_region(run, bit) ELIF size IS LARGE: region = allocate_new_run() ELSE: region = allocate_new_chunk() RETURN region
如果不在 arena 的范围内:
则调用 allocate_new_chunk 分配一个新的 chunk,返回给用户
如果在 arena 的范围内,并且在 small/medium 的范围内:
调用 get_bin_for_size 获取对应大小的 bin
如果对应的 bin 存在且未满:
如果对应的 bin 不存在或者已满:
调用 lookup_or_allocate_nonfull_run 申请一个 run,并接在 bin 的后面
调用 get_first_set_bit 从 bin 中获取 bit(每个位对应一个区域,0 表示该区域已使用,1 位值表示相应区域空闲)
最后调用 get_region 从 bin 中获取一个 run
否则调用 allocate_new_run 分配一个新的 run,返回给用户
释放流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 FREE(addr): IF addr IS NOT EQUAL TO THE CHUNK IT BELONGS: IF addr IS A SMALL ALLOCATION: run = get_run_addr_belongs_to(addr); bin = run->bin; size = bin->reg_size; element = get_element_index(addr, run, bin) unset_bit(run->regs_mask[element]) ELSE: run = get_run_addr_belongs_to(addr) chunk = get_chunk_run_belongs_to(run) run_index = get_run_index(run, chunk) mark_pages_of_run_as_free(run_index) IF ALL THE PAGES OF chunk ARE MARKED AS FREE: unmap_the_chunk_s_pages(chunk) ELSE: unmap_the_huge_allocation_s_pages(addr)
根据 addr 对应的 size 大小来选择释放的方法:
huge:
采用 unmap_the_huge_allocation_s_pages 进行释放
small:
调用 get_run_addr_belongs_to 获取该 addr 对应的 run
通过 run 获取对应的 bin
通过 bin 获取对应的 reg_size
调用 get_element_index 获取 region(大小为 byte)在 run 中的偏移
调用 unset_bit 进行释放
large:
调用 get_run_addr_belongs_to 获取该 addr 对应的 run
调用 get_chunk_run_belongs_to 获取该 addr 对应的 chunk
调用 get_run_index 获取 region(大小为 page)在 chunk 中的偏移
调用 mark_pages_of_run_as_free 进行释放
如果 chunk 的所有 page 都标记为 free(空闲):
调用 unmap_the_chunk_s_pages 释放该 chunk
分配 region
1 2 3 ret = (void *)((uintptr_t )run + (uintptr_t )bin_info->reg0_offset + (uintptr_t )(bin_info->reg_size * regind));
region 的值可以理解为“3”部分相加:
run:对应 run 的基地址
bin_info->reg0_offset:此 bin 对应的 run 中第一个 region 的偏移量
bin_info->reg_size * regind:目标 region 在 run 中的偏移量
可以说,ptmalloc 就是通过偏移 regind 来获取 region 的位置的
在 jemalloc-2.2.5 分配 region 前,会在目标 run 的范围的头部申请一个 arena_run_t 结构体来管理 run(但 jemalloc-5.0.1 是不会分配 arena_run_t 的)
因为 run 以 page 为单位,所以 arena_run_t 的地址后3位为“0”
由此可以快速判断 arena_run_t 的位置
分配 run
run 以 page 为单位,如果 size 比较小,run 的大小范围往往就是一页
默认64位系统的划分方式:
Small: [8],[16,32,48,…,128](16字节等分),[128,192,256,320, …,512](64字节等分),[512,768,1024,1280,…,3840](256字节等分)
通过以下案例,来看看不同 run 的地址范围:(jemalloc-5.0.1)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <stdio.h> #include <string.h> #include <jemalloc/jemalloc.h> int main () char *foo[20 ]; char *bar[20 ]; int i; printf ("foo >> %p\n" ,foo); foo[0 ] = malloc (8 ); printf ("foo[%d]: size:%d \t%p\n" ,0 ,8 ,(unsigned int )foo[0 ]); for (i=1 ;i<=8 ;i++){ foo[i] = malloc (16 *i); printf (">> foo[%d]-foo[%d]=%d\n" ,i,i-1 ,(foo[i]-foo[i-1 ])/4096 ); printf ("foo[%d]: size:%d\t%p\n" ,i,16 *i,(unsigned int )foo[i]); } for (i=9 ;i<=14 ;i++){ foo[i] = malloc (128 +64 *(i-8 )); printf (">> foo[%d]-foo[%d]=%d\n" ,i,i-1 ,(foo[i]-foo[i-1 ])/4096 ); printf ("foo[%d]: size:%d\t%p\n" ,i,128 +64 *(i-8 ),(unsigned int )foo[i]); } return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ➜ exp ./jemalloc foo >> 0x7ffe3a4b1330 foo[0 ]: size:8 0x91c2d008 >> foo[1 ]-foo[0 ]=25 foo[1 ]: size:16 0x91c47000 >> foo[2 ]-foo[1 ]=-24 foo[2 ]: size:32 0x91c2e020 >> foo[3 ]-foo[2 ]=25 foo[3 ]: size:48 0x91c48000 >> foo[4 ]-foo[3 ]=3 foo[4 ]: size:64 0x91c4b000 >> foo[5 ]-foo[4 ]=1 foo[5 ]: size:80 0x91c4c000 >> foo[6 ]-foo[5 ]=5 foo[6 ]: size:96 0x91c51000 >> foo[7 ]-foo[6 ]=3 foo[7 ]: size:112 0x91c54000 >> foo[8 ]-foo[7 ]=7 foo[8 ]: size:128 0x91c5b000 >> foo[9 ]-foo[8 ]=1 foo[9 ]: size:192 0x91c5c000 >> foo[10 ]-foo[9 ]=3 foo[10 ]: size:256 0x91c5f000 >> foo[11 ]-foo[10 ]=1 foo[11 ]: size:320 0x91c60000 >> foo[12 ]-foo[11 ]=5 foo[12 ]: size:384 0x91c65000 >> foo[13 ]-foo[12 ]=3 foo[13 ]: size:448 0x91c68000 >> foo[14 ]-foo[13 ]=7 foo[14 ]: size:512 0x91c6f000
不管重复多少次后5位始终不变,说明 jemalloc 的分配以 100page 为单位
地址的分配似乎没有什么规律,可能是 jemalloc 的保护机制吧
Jemalloc GDB GDB 可以用来打印 jemalloc 里面的符号(各种全局变量和结构体),前提如下:
在GCC编译时加上 “-ljemalloc”
用 directory 导入对应版本的 jemalloc 源码文件
arena 是 jemalloc 的总的管理块,一个进程中可以有多个 arena,arena 的最大个可以通过静态变量 narenas_total 得知,可以在 GDB 中进行打印:
1 2 3 4 pwndbg> p narenas_total $1 = { repr = 8 }
可通过静态数组 arenas 获取进程中所有 arena 的指针:
1 2 3 4 5 6 pwndbg> p *je_arenas@2 $6 = {{ repr = 0x7ffff757e980 }, { repr = 0x0 }}
1 2 3 4 5 6 7 pwndbg> p (arena_t **)je_arenas $7 = (arena_t **) 0x7ffff7da2a80 <je_arenas> pwndbg> telescope 0x7ffff7da2a80 00 :0000 │ 0x7ffff7da2a80 (je_arenas) —▸ 0x7ffff757e980 ◂— 0x100000001 01 :0008 │ 0x7ffff7da2a88 (je_arenas+8 ) ◂— 0x0 ... ↓ 6 skipped
在结构体 arena_t 中有个类型为 arena_bin_t 的数组 bins(动态分配数组 bins 的大小),数组 bins 的每个条目对应1种大小的 region 和 run
binind 表示 bins 中的偏移,每一个 binind 对应一个固定大小的 region,其对应关系为:
1 2 3 4 5 6 7 8 9 binind = arena_bin_index(chunk->arena, run->bin); bin_info = &arena_bin_info[binind]; static inline szind_t arena_bin_index (arena_t *arena, arena_bin_t *bin) { szind_t binind = (szind_t )(bin - arena->bins); assert(binind < NBINS); return binind; }
在 GDB 中,我们可以通过静态变量 arena_bin_info 获取对应 bin 的其他信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 pwndbg> p je_arena_bin_info $11 = {{ reg_size = 8 , slab_size = 4096 , nregs = 512 , bitmap_info = { nbits = 512 , ngroups = 8 } }, { reg_size = 16 , slab_size = 4096 , nregs = 256 , bitmap_info = { nbits = 256 , ngroups = 4 } }, { reg_size = 32 , slab_size = 4096 , nregs = 128 , bitmap_info = { nbits = 128 , ngroups = 2 } }, { reg_size = 48 , slab_size = 12288 , nregs = 256 , bitmap_info = { nbits = 256 , ngroups = 4 } }, { ...... }, { reg_size = 12288 , slab_size = 12288 , nregs = 1 , bitmap_info = { nbits = 1 , ngroups = 1 } }, { reg_size = 14336 , slab_size = 28672 , nregs = 2 , bitmap_info = { nbits = 2 , ngroups = 1 } }}
可以通过指定 index 来获取对应 size 范围的 arena_bin_info:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 pwndbg> p je_arena_bin_info[2 ] $12 = { reg_size = 32 , slab_size = 4096 , nregs = 128 , bitmap_info = { nbits = 128 , ngroups = 2 } } pwndbg> p je_arena_bin_info[3 ] $13 = { reg_size = 48 , slab_size = 12288 , nregs = 256 , bitmap_info = { nbits = 256 , ngroups = 4 } }
在结构体 arena_bin_t 中有个类型为 arena_run_t 的指针 runcur,指向当前可用于分配的 run
runs 是个红黑树,链接当前 arena 中,所有可用的相同大小 region 对应的 run,如果 runcur 已满,就会从 runs 里找可用的 run
stats 是当前 bin 对应的 run 和 region 的状态信息
Adjacent region corruption(相邻区域冲突) Adjacent region corruption 的核心思想为:利用了堆管理器将用户空间相邻放置的事实,在 jemalloc 中,相同大小类别的区域被放置在同一个 bin 上,如果它们也被放置在 bin 的同一 run 中,则它们之间没有 inline metadata
现在,让我们假设相同大小类新分配的 region 被放置在同一次 run 中:
我可以放置一个 victim object/structure 到某个 object/structure 旁边
我们选择的 object/structure 必须是:在同一个 run 中,相邻的,大小相同的,易受伤害的
唯一的要求是:“受害对象” 和 “易受攻击对象” 的大小必须能够放入它们,并且有相同的 size class,方便我们继续溢出
通常受害区域是可以帮助我们实现任意代码执行的东西,例如函数指针
利用案例一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <stdio.h> #include <jemalloc/jemalloc.h> int main (int argc, char **argv) char *one, *two, *three; char padding[30 ]; printf ("[*] before overflowing\n" ); memset (padding, 0x58 , 30 ); printf ("padding:\t\t%s\n" ,padding); one = malloc (0x10 ); memset (one, 0x41 , 0x10 ); printf ("[+] region one:\t\t0x%x: %s\n" , (unsigned int )one, one); two = malloc (0x10 ); memset (two, 0x42 , 0x10 ); printf ("[+] region two:\t\t0x%x: %s\n" , (unsigned int )two, two); three = malloc (0x10 ); memset (three, 0x43 , 0x10 ); printf ("[+] region three:\t0x%x: %s\n" , (unsigned int )three, three); printf ("[+] copying padding to region two\n" ); strcpy (two, padding); printf ("[*] after overflowing\n" ); printf ("[+] region one:\t\t0x%x: %s\n" , (unsigned int )one, one); printf ("[+] region two:\t\t0x%x: %s\n" , (unsigned int )two, two); printf ("[+] region three:\t0x%x: %s\n" , (unsigned int )three, three); free (one); free (two); free (three); printf ("[*] after freeing all regions\n" ); printf ("[+] region one:\t\t0x%x: %s\n" , (unsigned int )one, one); printf ("[+] region two:\t\t0x%x: %s\n" , (unsigned int )two, two); printf ("[+] region three:\t0x%x: %s\n" , (unsigned int )three, three); return 0 ; }
申请了三片区域:“one”,“two”,“three”
在区域 “two” 中制造溢出
释放这三片区域
执行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ➜ exp gcc test.c -o jemalloc -ljemalloc -g -no-pie ➜ exp ./jemalloc [*] before overflowing [+] padding: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region one: 0x115a7000 : AAAAAAAAAAAAAAAA [+] region two: 0x115a7010 : BBBBBBBBBBBBBBBB [+] region three: 0x115a7020 : CCCCCCCCCCCCCCCC [+] copying padding to region two [*] after overflowing [+] region one: 0x115a7000 : AAAAAAAAAAAAAAAAXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region two: 0x115a7010 : XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region three: 0x115a7020 : XXXXXXXXXXXXXX [*] after freeing all regions [+] region one: 0x115a7000 : AAAAAAAAAAAAAAAAXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region two: 0x115a7010 : XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX [+] region three: 0x115a7020 : XXXXXXXXXXXXXX
关键点1:“one”,“two”,“three” 的数据地址刚好相差 0x10,说明数据连续
关键点2:“two” 中溢出了30字节的“0x58”后,printf 的 “打印边界” 似乎出问题了
关键点3:释放之后,“one”,“two”,“three” 的数据没有置空(UAF预备)
接下来就进行单步调试,分析一下以上这些疑点:
断点在 [3-1] 处:
1 2 3 4 pwndbg> x/20 wx 0x7ffff73a0000 0x7ffff73a0000 : 0x41414141 0x41414141 0x41414141 0x41414141 0x7ffff73a0010 : 0x42424242 0x42424242 0x42424242 0x42424242 0x7ffff73a0020 : 0x43434343 0x43434343 0x43434343 0x43434343
可以发现,“one”,“two”,“three” 的数据真的是连续的
断点在 [3-2] 处:
1 2 3 4 pwndbg> x/20 wx 0x7ffff73a0000 0x7ffff73a0000 : 0x41414141 0x41414141 0x41414141 0x41414141 0x7ffff73a0010 : 0x58585858 0x58585858 0x58585858 0x58585858 0x7ffff73a0020 : 0x58585858 0x58585858 0x58585858 0x43005858
padding 的30个“0x58”完全覆盖了 “two”,并且在 “three” 上持续了15字节(包括最后的“\x00”)
这似乎扰乱了 printf 的打印(不知道是 printf 本身的性质,还是 Regions 的问题),从结果来看,一旦溢出现象发生后,printf 就会分不清楚 Regions 之间的界限,然后用“\x00”来区分 Regions 的范围
利用这个特性,可以溢出一些重要数据
断点在 [3-3] 处:
1 2 3 4 pwndbg> x/20 wx 0x7ffff73a0000 0x7ffff73a0000 : 0x41414141 0x41414141 0x41414141 0x41414141 0x7ffff73a0010 : 0x58585858 0x58585858 0x58585858 0x58585858 0x7ffff73a0020 : 0x58585858 0x58585858 0x58585858 0x43005858
free 执行完成后,heap 上的数据没有收到任何的影响
利用案例二:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <stdio.h> #include <string.h> #include <jemalloc/jemalloc.h> class base { private : char buf[32 ]; public : void copy (const char *str) { strcpy (buf, str); } virtual void print (void ) { printf ("buf: 0x%lx: %s\n" , (char *)buf, buf); } }; class derived_a :public base{ public : void print (void ) { printf ("[+] derived_a: " ); base::print (); } }; class derived_b :public base{ public : void print (void ) { printf ("[+] derived_b: " ); base::print (); } }; int main (uintptr_t argc, char *argv[]) base *obj_a; base *obj_b; char padding1[49 ]; char padding2[11 ]; obj_a = new derived_a; obj_b = new derived_b; memset (padding1, 0x41 , 48 ); printf ("padding1:\t%s\n" ,padding1); memset (padding2, 0x42 , 10 ); printf ("padding2:\t%s\n" ,padding2); printf ("[+] obj_a:\t0x%lx\n" , (uintptr_t )obj_a); printf ("[+] obj_b:\t0x%lx\n" , (uintptr_t )obj_b); printf ("[+] overflowing from obj_a into obj_b\n" ); obj_a->copy (padding1); obj_b->copy (padding2); obj_a->print (); obj_b->print (); return 0 ; }
定义了 base 类:
函数 copy:用于在 buf 中制造溢出
虚函数 print:用于打印 buf
定义了 derived_a,derived_b 类继承 base 类:
执行结果:
1 2 3 4 5 6 7 8 9 ➜ exp gcc test.c -o jemalloc -ljemalloc -g -no-pie ➜ exp ./jemalloc padding1: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA padding2: BBBBBBBBBB [+] obj_a: 0x7f4b750ae000 [+] obj_b: 0x7f4b750ae030 [+] overflowing from obj_a into obj_b [+] derived_a: buf: 0x7f4b750ae008 : AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBB [1 ] 7331 segmentation fault ./jemalloc
derived_b 的 print 一执行就直接报错了,很有可能是虚表的问题
接下来就进行单步调试:
断点一,“new derived_a” 执行前:
1 2 3 4 5 0x4011eb <main+21 > mov rax, qword ptr fs:[0x28 ] 0x4011f4 <main+30 > mov qword ptr [rbp - 0x18 ], rax 0x4011f8 <main+34 > xor eax, eax 0x4011fa <main+36 > mov edi, 0x28 ► 0x4011ff <main+41 > call 0x4010a0 <0x4010a0 >
这个 “0x4010a0” 就是 new 的 PLT 表地址
1 2 3 4 pwndbg> x/20 xg 0x4010a0 0x4010a0 <operator new (unsigned long ) @plt>: 0x7525fff2fa1e0ff3 0x0000441f0f00002f0x4010b0 <memset @plt>: 0x6d25fff2fa1e0ff3 0x0000441f0f00002f 0x4010c0 <strcpy @plt>: 0x6525fff2fa1e0ff3 0x0000441f0f00002f
调用 “0x4010a0” 前,需要把 “它将要创建的对象的大小” 作为参数,即 0x28 字节(buf[32]+VPTR)
可以发现:buf[32] 和 VPTR 是连续的,完全可以把 buf 中的数据溢出到 VPTR 中
断点二,“obj_a->copy(padding1)” 执行前:
1 2 3 4 5 0x4012c4 <main+238 > lea rdx, [rbp - 0x50 ] 0x4012c8 <main+242 > mov rax, qword ptr [rbp - 0x70 ] 0x4012cc <main+246 > mov rsi, rdx 0x4012cf <main+249 > mov rdi, rax ► 0x4012d2 <main+252 > call 0x401330 <0x401330 >
这个 “0x401330” 就是 base::copy() 的代码地址
下面是 heap 的空间排列:
1 2 02 :0010 │ 0x7fffffffde20 —▸ 0x7ffff739d000 —▸ 0x403da0 —▸ 0x401396 (derived_a::print()) ◂— endbr64 03 :0018 │ 0x7fffffffde28 —▸ 0x7ffff739d030 —▸ 0x403d88 —▸ 0x4013c6 (derived_b::print()) ◂— endbr64
“0x7ffff739d000” 就是 new 为 derived_a 申请的 heap 空间:
大小为 0x30(0x28:0x10字节对齐)
“0x403da0” 就是 derived_a 的虚表(只装有 “derived_a::print()”,以“\x00”结尾)
剩下的都是 buf 的空间
“0x7ffff739d030” 就是 new 为 derived_b 申请的 heap 空间:
大小为 0x30(0x28:0x10字节对齐)
“0x403d88” 就是 derived_b 的虚表(只装有 “derived_b::print()”,以“\x00”结尾)
剩下的都是 buf 的空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 pwndbg> telescope 0x7ffff739d000 00 :0000 │ 0x7ffff739d000 —▸ 0x403da0 —▸ 0x401396 (derived_a::print()) ◂— endbr64 01 :0008 │ 0x7ffff739d008 ◂— 0x0 pwndbg> telescope 0x7ffff739d030 00 :0000 │ rbx 0x7ffff739d030 —▸ 0x403d88 —▸ 0x4013c6 (derived_b::print()) ◂— endbr64 01 :0008 │ 0x7ffff739d038 ◂— 0x0 pwndbg> telescope 0x403da0 00 :0000 │ 0x403da0 —▸ 0x401396 (derived_a::print()) ◂— endbr64 01 :0008 │ 0x403da8 ◂— 0x0 pwndbg> telescope 0x403d88 00 :0000 │ 0x403d88 —▸ 0x4013c6 (derived_b::print()) ◂— endbr64 01 :0008 │ 0x403d90 ◂— 0x0
断点三,“obj_a->print()” 执行前:
1 2 3 4 5 RDX 0x401396 (derived_a::print()) ◂— endbr64 .... 0x4012f8 <main+290 > mov rdi, rax ► 0x4012fb <main+293 > call rdx <derived_a::print()> rdi: 0x7ffff739d000 —▸ 0x403da0 —▸ 0x401396 (derived_a::print()) ◂— endbr64
rdx 装有 “0x401396”,就是 derived_a::print() 的代码地址
下面是 heap 的空间排列:
1 2 3 4 5 pwndbg> telescope 0x7ffff739d000 00 :0000 │ rax rdi 0x7ffff739d000 —▸ 0x403da0 —▸ 0x401396 (derived_a::print()) ◂— endbr64 01 :0008 │ 0x7ffff739d008 ◂— 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBB' ... ↓ 5 skipped 07 :0038 │ 0x7ffff739d038 ◂— 'BBBBBBBBBB'
可以发现 derived_a->buf 中溢出的数据,已经把 derived_b->VPTR 覆盖了
执行 derived_a::print() 时没有问题,执行 derived_b::print() 时肯定就会报错
如果 VPTR 被我们控制为 shellcode,就可以 get shell
Heap manipulation(堆风水) 为了能够将 jemalloc 堆安排在可预测的状态,我们需要了解分配器的行为并使用堆操作策略来影响它,使其对我们有利,堆操作策略在 Alexander Sotirov 的推广之后被称为“堆风水”
先看以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #define TSIZE 0x10 #define NALLOC 500 #define NFREE (NALLOC / 10) int main () char *foo[NALLOC]; char *bar[NALLOC]; int i; printf ("step 1: controlled allocations of victim objects\n" ); for (i = 0 ; i < NALLOC; i++) { foo[i] = malloc (TSIZE); printf ("foo[%d]:\t\t%p\n" , i, (unsigned int )foo[i]); } puts ("-------------------------------------------------" ); printf ("step 2: creating holes in between the victim objects\n" ); for (i = (NALLOC - NFREE); i < NALLOC; i += 2 ) { printf ("freeing foo[%d]:\t%p\n" , i, (unsigned int )foo[i]); free (foo[i]); } puts ("-------------------------------------------------" ); printf ("step 3: fill holes with vulnerable objects\n" ); for (i = (NALLOC - NFREE + 1 ); i < NALLOC; i += 2 ) { bar[i] = malloc (TSIZE); printf ("bar[%d]:\t%p\n" , i, (unsigned int )bar[i]); } puts ("-------------------------------------------------" ); return 0 ; }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 ➜ exp gcc test.c -o jemalloc -ljemalloc -g -no-pie ➜ exp ./jemalloc step 1 : controlled allocations of victim objects foo[0 ]: 0xa2ae000 foo[1 ]: 0xa2ae010 foo[2 ]: 0xa2ae020 foo[3 ]: 0xa2ae030 foo[4 ]: 0xa2ae040 foo[5 ]: 0xa2ae050 foo[6 ]: 0xa2ae060 foo[7 ]: 0xa2ae070 foo[8 ]: 0xa2ae080 foo[9 ]: 0xa2ae090 foo[10 ]: 0xa2ae0a0 foo[11 ]: 0xa2ae0b0 foo[12 ]: 0xa2ae0c0 foo[13 ]: 0xa2ae0d0 foo[14 ]: 0xa2ae0e0 foo[15 ]: 0xa2ae0f0 foo[16 ]: 0xa2ae100 ...... foo[489 ]: 0xa2afe90 foo[490 ]: 0xa2afea0 foo[491 ]: 0xa2afeb0 foo[492 ]: 0xa2afec0 foo[493 ]: 0xa2afed0 foo[494 ]: 0xa2afee0 foo[495 ]: 0xa2afef0 foo[496 ]: 0xa2aff00 foo[497 ]: 0xa2aff10 foo[498 ]: 0xa2aff20 foo[499 ]: 0xa2aff30 ------------------------------------------------- step 2 : creating holes in between the victim objects freeing foo[450 ]: 0xa2afc20 freeing foo[452 ]: 0xa2afc40 freeing foo[454 ]: 0xa2afc60 freeing foo[456 ]: 0xa2afc80 freeing foo[458 ]: 0xa2afca0 freeing foo[460 ]: 0xa2afcc0 freeing foo[462 ]: 0xa2afce0 freeing foo[464 ]: 0xa2afd00 ...... freeing foo[486 ]: 0xa2afe60 freeing foo[488 ]: 0xa2afe80 freeing foo[490 ]: 0xa2afea0 freeing foo[492 ]: 0xa2afec0 freeing foo[494 ]: 0xa2afee0 freeing foo[496 ]: 0xa2aff00 freeing foo[498 ]: 0xa2aff20 ------------------------------------------------- step 3 : fill holes with vulnerable objects bar[451 ]: 0xa2aff20 bar[453 ]: 0xa2aff00 bar[455 ]: 0xa2afee0 bar[457 ]: 0xa2afec0 bar[459 ]: 0xa2afea0 bar[461 ]: 0xa2afe80 bar[463 ]: 0xa2afe60 bar[465 ]: 0xa2afe40 ...... bar[487 ]: 0xa2afce0 bar[489 ]: 0xa2afcc0 bar[491 ]: 0xa2afca0 bar[493 ]: 0xa2afc80 bar[495 ]: 0xa2afc60 bar[497 ]: 0xa2afc40 bar[499 ]: 0xa2afc20 -------------------------------------------------
这里有很大的争议,我在网上看到了两种声音:
从 5.0.1 版本的测试来看,jemalloc 采用了 LIFO 队列
但网上有人认为 jemalloc 采用了 FIFO 队列,从他们的数据截图来看也的确是 FIFO 队列,我猜测可能是因为 jemalloc 的版本导致了分配次序的不同
最后说一下我自己的观点:(我只测试了两个版本)
我觉得 jemalloc-2.2.5 既不是 FIFO 也不是 LIFO,它只会在 run 所属的空间中,从低地址到高地址挨个找寻合适的 region 并分配出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 add(0x30 , '0' * 0x30 ) add(0x30 , '1' * 0x30 ) add(0x30 , '2' * 0x30 ) add(0x30 , '3' * 0x30 ) add(0x30 , '4' * 0x30 ) kill(4 ) kill(2 ) kill(3 ) kill(1 ) add(0x30 , 'a' * 0x30 ) add(0x30 , 'b' * 0x30 ) add(0x30 , 'c' * 0x30 ) add(0x30 , 'd' * 0x30 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 pwndbg> x/20 xg 0x7fa34240b040 0x7fa34240b040 : 0x3030303030303030 0x3030303030303030 0x7fa34240b050 : 0x3030303030303030 0x3030303030303030 0x7fa34240b060 : 0x3030303030303030 0x3030303030303030 0x7fa34240b070 : 0x6161616161616161 0x6161616161616161 0x7fa34240b080 : 0x6161616161616161 0x6161616161616161 0x7fa34240b090 : 0x6161616161616161 0x6161616161616161 0x7fa34240b0a0 : 0x6262626262626262 0x6262626262626262 0x7fa34240b0b0 : 0x6262626262626262 0x6262626262626262 0x7fa34240b0c0 : 0x6262626262626262 0x6262626262626262 0x7fa34240b0d0 : 0x6363636363636363 0x6363636363636363 0x7fa34240b0e0 : 0x6363636363636363 0x6363636363636363 0x7fa34240b0f0 : 0x6363636363636363 0x6363636363636363 0x7fa34240b100 : 0x6464646464646464 0x6464646464646464 0x7fa34240b110 : 0x6464646464646464 0x6464646464646464 0x7fa34240b120 : 0x6464646464646464 0x6464646464646464
我还尝试了其他的组合,不管释放的顺序如何改变,“a,b,c,d” 的顺序是不变的
也就是说,jemalloc-2.2.5 的释放和链表没有关系,分配时,就是从低地址到高地址遍历就行了
而 jemalloc-5.0.1 的确是 LIFO 队列,空闲 region 可能是用链表组织起来的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #define TSIZE 0x10 #define NALLOC 10 #define NFREE (NALLOC / 10) #include <stdio.h> #include <string.h> #include <jemalloc/jemalloc.h> int main () char *foo[NALLOC]; char *bar[NALLOC]; int i; printf ("step 1: controlled allocations of victim objects\n" ); for (i = 0 ; i < NALLOC; i++) { foo[i] = malloc (TSIZE); printf ("foo[%d]:\t\t%p\n" , i, (unsigned int )foo[i]); } printf ("step 2: creating holes in between the victim objects\n" ); free (foo[8 ]); free (foo[5 ]); free (foo[7 ]); free (foo[6 ]); free (foo[9 ]); printf ("foo[%d]:\t\t%p\n" , 8 , (unsigned int )foo[8 ]); printf ("foo[%d]:\t\t%p\n" , 5 , (unsigned int )foo[5 ]); printf ("foo[%d]:\t\t%p\n" , 7 , (unsigned int )foo[7 ]); printf ("foo[%d]:\t\t%p\n" , 6 , (unsigned int )foo[6 ]); printf ("foo[%d]:\t\t%p\n" , 9 , (unsigned int )foo[9 ]); printf ("step 3: fill holes with vulnerable objects\n" ); for (i = 0 ; i < NALLOC/2 ; i++) { bar[i] = malloc (TSIZE); printf ("bar[%d]:\t\t%p\n" , i, (unsigned int )bar[i]); } return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ➜ exp ./jemalloc step 1 : controlled allocations of victim objects foo[0 ]: 0x175f9000 foo[1 ]: 0x175f9010 foo[2 ]: 0x175f9020 foo[3 ]: 0x175f9030 foo[4 ]: 0x175f9040 foo[5 ]: 0x175f9050 foo[6 ]: 0x175f9060 foo[7 ]: 0x175f9070 foo[8 ]: 0x175f9080 foo[9 ]: 0x175f9090 step 2 : creating holes in between the victim objects foo[8 ]: 0x175f9080 foo[5 ]: 0x175f9050 foo[7 ]: 0x175f9070 foo[6 ]: 0x175f9060 foo[9 ]: 0x175f9090 step 3 : fill holes with vulnerable objects bar[0 ]: 0x175f9090 bar[1 ]: 0x175f9060 bar[2 ]: 0x175f9070 bar[3 ]: 0x175f9050 bar[4 ]: 0x175f9080
我故意打乱了释放的顺序,但是 jemalloc-5.0.1 还是可以“记住”我的释放顺序
也就是说,jemalloc-5.0.1 中一定有一个结构来我的释放顺序,极有可能是链表(我在源码中没有找到)
从结果上分析,jemalloc-5.0.1 采用了 LIFO
由于 jemalloc 不是基于 freelists(它使用基于宏的红黑树代替),因此无法使用 unlink 和 frontlink 漏洞利用技术,相反,我们将关注如何强制 “malloc()” 返回一个指向已初始化堆区域的指针
Run (arena_run_t)
run 只是一些相同 size 的 regions 的集合,run 的元数据遵循 arena_run_t 的结构,每个
在解除分配时,区域大小是未知的,因此无法直接计算 bin 索引,相反,jemalloc 将首先找到要释放的内存所在的 run,然后取消引用存储在 run 的 header 中的 bin 指针:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static void arena_dalloc_bin_run (arena_t *arena, arena_chunk_t *chunk, arena_run_t *run, arena_bin_t *bin) size_t binind; arena_bin_info_t *bin_info; size_t npages, run_ind, past; assert(run != bin->runcur); assert(arena_run_tree_search(&bin->runs, &chunk->map [ (((uintptr_t )run-(uintptr_t )chunk)>>PAGE_SHIFT)-map_bias]) == NULL ); binind = arena_bin_index(chunk->arena, run->bin); bin_info = &arena_bin_info[binind]; malloc_mutex_unlock(&bin->lock); npages = bin_info->run_size >> PAGE_SHIFT; run_ind = (size_t )(((uintptr_t )run - (uintptr_t )chunk) >> PAGE_SHIFT); past = (size_t )(PAGE_CEILING((uintptr_t )run + (uintptr_t )bin_info->reg0_offset + (uintptr_t )(run->nextind * bin_info->reg_size) - (uintptr_t )chunk) >> PAGE_SHIFT); malloc_mutex_lock(&arena->lock); if ((chunk->map [run_ind-map_bias].bits & CHUNK_MAP_DIRTY) == 0 && past - run_ind < npages) { chunk->map [run_ind+npages-1 -map_bias].bits = CHUNK_MAP_LARGE | (chunk->map [run_ind+npages-1 -map_bias].bits & CHUNK_MAP_FLAGS_MASK); chunk->map [run_ind-map_bias].bits = bin_info->run_size | CHUNK_MAP_LARGE | (chunk->map [run_ind-map_bias].bits & CHUNK_MAP_FLAGS_MASK); arena_run_trim_tail(arena, chunk, run, (npages << PAGE_SHIFT), ((past - run_ind) << PAGE_SHIFT), false ); } #ifdef JEMALLOC_DEBUG run->magic = 0 ; #endif arena_run_dalloc(arena, run, true ); malloc_mutex_unlock(&arena->lock); malloc_mutex_lock(&bin->lock); #ifdef JEMALLOC_STATS bin->stats.curruns--; #endif }
malloc 的分配相当依赖 arena_run_t 结构体,而 jemalloc-2.2.5 分配 region 前,会在目标 run 的范围的头部申请一个 arena_run_t 结构体来管理 run(jemalloc-5.0.1 不会分配)
如果有堆溢出,就可以劫持 arena_run_t 结构体
主要是劫持 arena_run_t->nfree:
1 2 3 4 5 6 7 pwndbg> p (arena_run_t )*0x7fc184808000 $1 = { magic = 944430995 , bin = 0x7fc185000d70 , nextind = 1 , nfree = 49 }
如果 nfree 为初始值,jemalloc.2.2.5 就会认为该 run 没有进行分配,然后无视之前已经在 run 中分配的部分,从头开始申请
这样就可以覆盖一些关键数据