LLVM 简析 LLVM 项目是模块化、可重用的编译器以及工具链技术的集合,用于优化以任意程序语言编写的程序的编译时间 (compile-time),链接时间 (link-time),运行时间 (run-time),以及空闲时间 (idle-time)
LLVM 官方文档:https://llvm.org/docs/WritingAnLLVMPass.html
LLVM 的安装:一份关于各种安装LLVM的方法的总结
报错 llvm-config 无法找到:sudo apt install llvm
报错 Failed building wheel for llvmlite:Python安装llvmlite、numba报错解决方案
编译原理 编译可以分为五个基本步骤:
词法分析
语法分析
语义分析
中间代码的生成、优化
目标代码的生成
这是每个编译器都必须的基本步骤和流程,从源头输入高级语言源程序输出目标语言代码
具体流程如下:
1 源代码 ==>[词法分析]==> 词法单元流(token) ==>[语法分析]==> 语法树(AST) ==>[语义分析]==> 语法树(AST) ==>[中间代码的生成,优化]==> 中间代码 ==>[目标代码的生成]==> 目标机器代码
词法分析
词法分析器对构成源程序的字符串从左到右的扫描,逐个字符地读,识别出每个单词符号(识别出的符号一般以二元式形式输出),即包含符号种类的编码和该符号的值
词法分析器一般以函数的形式存在,供语法分析器调用,当然也可以一个独立的词法分析器程序存在,完成词法分析任务的程序称为词法分析程序或词法分析器或扫描器
语法分析
这阶段的任务是在词法分析的基础上,将识别出的单词符号序列组合成各类语法短语,如“语句”,“表达式”等
语法分析程序的主要步骤是判断源程序语句是否符合定义的语法规则,在语法结构上是否正确
语义分析
词法分析注重的是每个单词是否合法,以及这个单词属于语言中的哪些部分,语法分析的上下文无关文法注重的是输入语句是否可以依据文法匹配产生式
中间代码的生成、优化
在进行了语法分析和语义分析阶段的工作之后,有的编译程序将源程序变成一种内部表示形式,这种内部表示形式叫做中间语言或中间表示或中间代码
所谓“中间代码”是一种结构简单、含义明确的记号系统,这种记号系统复杂性介于源程序语言和机器语言之间,容易将它翻译成目标代码
目标代码的生成
根据优化后的中间代码,可生成有效的目标代码,而通常编译器将其翻译为汇编代码,此时还需要将汇编代码经汇编器汇编为目标机器的机器语言
LLVM IR 在开发编译器时,通常的做法是将源代码编译到某种中间表示(Intermediate Representation,一般称为 IR),然后再将 IR 翻译为目标体系结构的汇编(比如 MIPS 或 X86)
LLVM 的流程如下:
1 源代码 ==>[词法分析]==> 词法单元流(token) ==>[语法/语义分析]==> 语法树(AST) ==>[中间代码的生成]==> LLVM IR ==>[中间代码的优化]==> 生成汇编代码 ==>[汇编+链接]==> 目标机器代码
传给 LLVM PASS 进行优化的数据是 LLVM IR,即代码的中间表示,LLVM IR有三种表示形式 :这三种中间格式是完全等价的:
在内存中的编译中间语言(我们无法通过文件的形式得到)
在硬盘上存储的二进制中间语言(格式为 .bc)
人类可读的代码语言(格式为 .ll)
从对应格式转化到另一格式的命令如下:
1 2 3 4 5 .c -> .ll:clang -emit-llvm -S a.c -o a.ll .c -> .bc: clang -emit-llvm -c a.c -o a.bc .ll -> .bc: llvm-as a.ll -o a.bc .bc -> .ll: llvm-dis a.bc -o a.ll .bc -> .s: llc a.bc -o a.s
案例:
1 2 3 4 5 6 7 8 9 #include <stdio.h> #include <unistd.h> int main () char name[0x10 ]; read(0 ,name,0x10 ); write(1 ,name,0x10 ); printf ("bye\n" ); }
运行以下命令:
1 ➜ clang -emit-llvm -S main.c -o main.ll
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ; ModuleID = 'test.c' source_filename = "test.c" target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128" // 数据布局 target triple = "x86_64-pc-linux-gnu" @.str = private unnamed_addr constant [5 x i8] c"bye\0A\00", align 1 ; Function Attrs: noinline nounwind optnone uwtable define dso_local i32 @main() #0 { %1 = alloca [16 x i8], align 16 /* char name[0x10]; */ %2 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i64 0, i64 0 %3 = call i64 @read(i32 0, i8* %2, i64 16) %4 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i64 0, i64 0 %5 = call i64 @write(i32 1, i8* %4, i64 16) %6 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @.str, i64 0, i64 0)) ret i32 0 } declare dso_local i64 @read(i32, i8*, i64) #1 declare dso_local i64 @write(i32, i8*, i64) #1 declare dso_local i32 @printf(i8*, ...) #1 attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } !llvm.module.flags = !{!0} !llvm.ident = !{!1} !0 = !{i32 1, !"wchar_size", i32 4} !1 = !{!"clang version 10.0.0-4ubuntu1 "}
@代表全局标识符(函数,全局变量)
%代表局部标识符(寄存器名称也就是局部变量,类型)
alloca指令:用于分配内存堆栈给当前执行的函数,当这个函数返回其调用者时自动释放
LLVM Pass LLVM 的 pass 框架是 LLVM 系统的一个很重要的部分,LLVM 的优化和转换工作就是由多个 pass 来一起完成的,类似流水线操作一样,每个 pass 完成特定的优化工作,要想真正发挥 LLVM 的威力,掌握 pass 是不可或缺的一环
总的来说,所有的 pass 大致可以分为两类:
分析 (analysis) 和转换分析类的 pass 以提供信息为主
转换类 (transform) 的 pass 优化中间代码
样例文件在 llvm-project/llvm/lib/Transforms/Hello/Hello.cpp 中,源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include "llvm/Pass.h" #include "llvm/IR/Function.h" #include "llvm/Support/raw_ostream.h" #include "llvm/IR/LegacyPassManager.h" #include "llvm/Transforms/IPO/PassManagerBuilder.h" using namespace llvm;namespace { struct Hello :public FunctionPass { static char ID; Hello() : FunctionPass(ID) {} bool runOnFunction (Function &F) override errs() << "Hello: " ; errs().write_escaped(F.getName()) << '\n' ; SymbolTableList<BasicBlock>::const_iterator bbEnd = F.end(); for (SymbolTableList<BasicBlock>::const_iterator bbIter=F.begin(); bbIter!=bbEnd; ++bbIter){ SymbolTableList<Instruction>::const_iterator instIter = bbIter->begin(); SymbolTableList<Instruction>::const_iterator instEnd = bbIter->end(); for (; instIter != instEnd; ++instIter){ errs() << "opcode=" << instIter->getOpcodeName() << " NumOperands=" << instIter->getNumOperands() << "\n" ; } } return false ; } }; } char Hello::ID = 0 ;static RegisterPass<Hello> X ("hello" , "Hello World Pass" ) static RegisterStandardPasses Y (PassManagerBuilder::EP_EarlyAsPossible, [](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) { PM.add(new Hello()); })
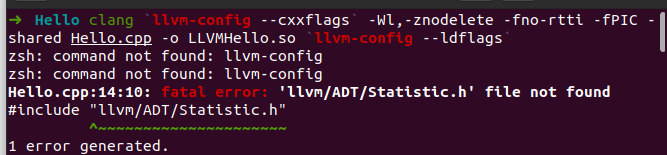
输入一下指令,可以得到编译好的 LLVMHello.so:
1 ➜ Hello clang `llvm-config --cxxflags` -Wl,-znodelete -fno-rtti -fPIC -shared Hello.cpp -o LLVMHello.so `llvm-config --ldflags`
用 LLVMHello.so 来测试 main.ll:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ➜ Hello opt -load ./LLVMHello.so -hello ./main.ll WARNING: You're attempting to print out a bitcode file. This is inadvisable as it may cause display problems. If you REALLY want to taste LLVM bitcode first-hand, you can force output with the `-f' option.Hello: main opcode=alloca NumOperands=1 opcode=getelementptr NumOperands=3 opcode=call NumOperands=4 opcode=getelementptr NumOperands=3 opcode=call NumOperands=4 opcode=call NumOperands=2 opcode=ret NumOperands=1
BogusControlFlow BogusControlFlow 是一个结构体,跟到 runOnFunction
BogusControlFlow 的功能是为函数增加新的虚假控制流和添加垃圾指令
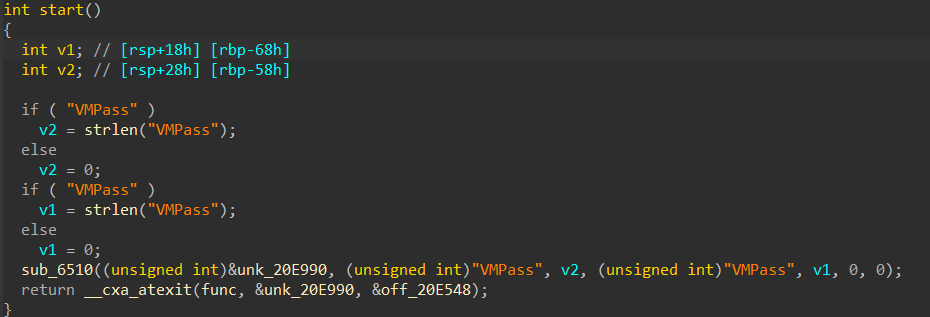
runOnFunction runOnFunction 是入口函数,BogusControlFlow 继承了 FunctionPass,因此它的入口函数即为 runOnFunction
在 IDA7.7 中可以直接搜索 runOnFunction:
如果 IDA 没有找到 runOnFunction,就只能通过调试来寻找它了:
由于模块是动态加载的,并且运行时也不会暂停下来等我们用调试器去Attach,因此我们可以直接使用 IDA 来进行调试
还有另一种方法:
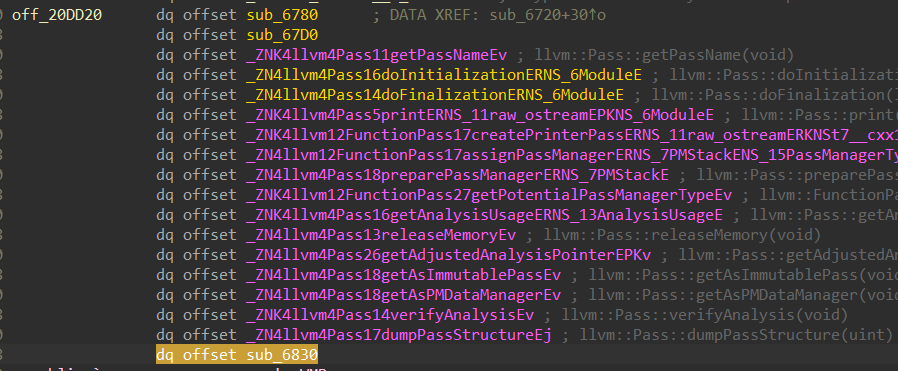
在 IDA 中搜索题目给定的“在代码中注册的名字”,找到对应的函数
在这个函数及其子函数中寻找 off-xxxx 就可能找到虚表(尽量找那些未命名的函数)
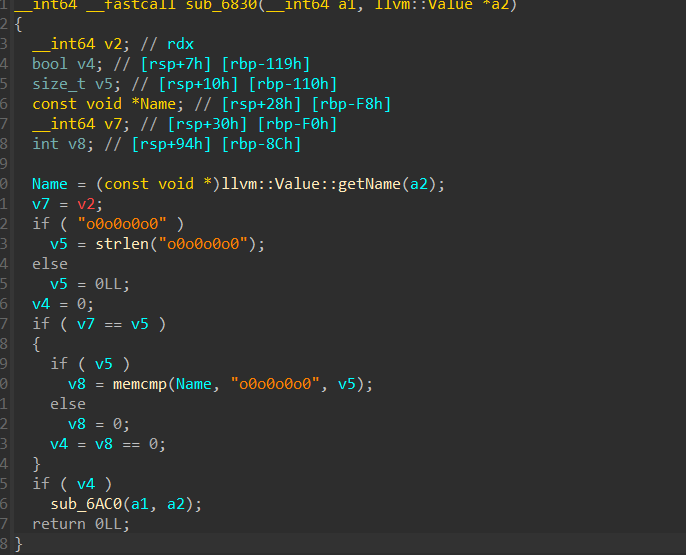
虚表的最后一个条目就是 runOnFunction
LLVM 原理 传统编译器分三个阶段:
前端(Frontend)— 优化器(Optimizer)— 后端(Backend)
前端负责分析源代码,可以检查语法级错误,并构建针对语言的抽象语法树(AST),抽象语法树可以进一步转换为优化,最终转为新的表示方式,然后再交给让优化器和后端处理
最终由后端生成可执行的机器码
LLVM 也分三个阶段,但是设计上略微的有些区别,LLVM 不同的就是对于不同的语言它都提供了同一种中间表示:
前端可以使用不同的编译工具对代码文件做词法分析以形成抽象语法树(AST),然后将分析好的代码转换成 LLVM 的中间表示 IR(intermediate representation)
中间部分的优化器只对中间表示 IR 进行操作,通过一系列的 pass 对 IR 做优化
后端负责将优化好的 IR 解释成对应平台的机器码
LLVM 的优点在于:中间表示 IR 代码编写良好,而且不同的前端语言最终都转换成同一种的 IR
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决
所以 LLVM 就是在执行优化操作之前,先把代码转化为 LLVM 的中间表示 IR,然后对 IR 进行优化,最后交给后端翻译为机器码
使用 LLVM 的对一门语言编译如下所示:
1 源代码 => (词法分析) => Token => (语法分析) => AST => (代码生成) => LLVM IR => (优化) => LLVM IR(已优化) => (生成汇编代码) => 汇编代码 => (汇编) => 目标文件 => (Link) => 可执行文件
PS:至于 LLVM pass,复现 “红帽杯 simpleVM” 会有深刻的理解