实验介绍
在本练习中,您将使用支持向量机 (SVM) 来构建垃圾邮件分类器
- ex6.m - 练习前半部分的 Octave/MATLAB 脚本
- ex6data1.mat - 示例数据集 1
- ex6data2.mat - 示例数据集 2
- ex6data3.mat - 示例数据集 3
- svmTrain.m - SVM 训练函数
- svmPredict.m - SVM 预测函数
- plotData.m - 绘制二维数据
- visualizeBoundaryLinear.m - 绘制线性边界
- visualizeBoundary.m - 绘制非线性边界
- linearKernel.m - 支持向量机的线性内核
- [?] gaussianKernel.m - 支持向量机的高斯核
- [?] dataset3Params.m - 用于 ex6data3.mat 的参数
- ex6_spam.m - 练习后半部分的 Octave/MATLAB 脚本
- spamTrain.mat - 用“垃圾邮件训练集”进行训练
- Test.mat - 垃圾邮件测试集
- emailSample1.txt - 示例电子邮件 1
- emailSample2.txt - 示例电子邮件 2
- spamSample1.txt - 示例电子邮件 3
- spamSample2.txt - 示例电子邮件 4
- vocab.txt - 词汇表
- getVocabList.m - 加载词汇表
- porterStemmer.m - 词干功能
- readFile.m - 将文件读入字符串
- submit.m - 将您的解决方案发送到我们的服务器的提交脚本
- [?] processEmail.m - 电子邮件预处理
- [?] emailFeatures.m - 从电子邮件中提取特征
在整个练习中,您将使用脚本 ex6.m,这些脚本为问题设置数据集并调用您将编写的函数,您只需按照本作业中的说明修改其他文件中的功能
Support Vector Machines(支持向量机)
在本练习的前半部分,您将使用支持向量机 (SVM) 和各种示例 2D 数据集,对这些数据集进行试验将帮助您直观地了解 SVM 的工作原理以及如何将高斯核与 SVM 一起使用
在练习的下半部分,您将使用支持向量机来构建垃圾邮件分类器,提供的脚本 ex6.m 将帮助您逐步完成练习的前半部分
Example Dataset 1(示例数据集 1)
我们将从一个可以由线性边界分隔的 2D 示例数据集开始
- 脚本 ex6.m 将绘制训练数据,在这个数据集中,正例(用 + 表示)和负例(用 o 表示)的位置表明了由间隙表示的自然分离
- 但是,请注意,在最左侧大约 (0.1, 4.1) 处有一个异常正例 +
- 在下一部分中,您还将看到这个异常值如何影响 SVM 决策边界
实现过程:
1 | np.set_printoptions(formatter={'float': '{: 0.6f}'.format}) # 用于控制Python中小数的显示精度 |
绘图:
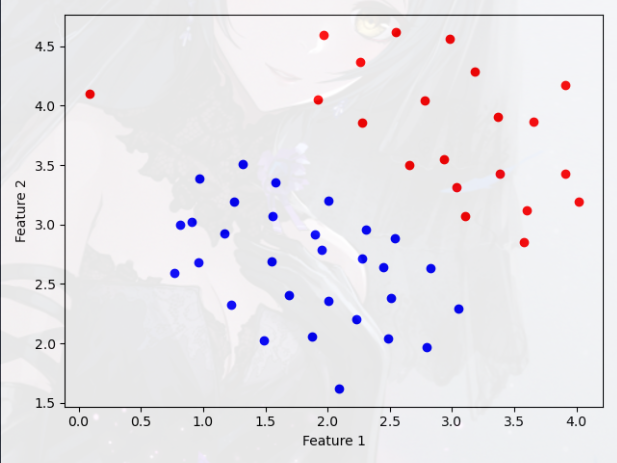
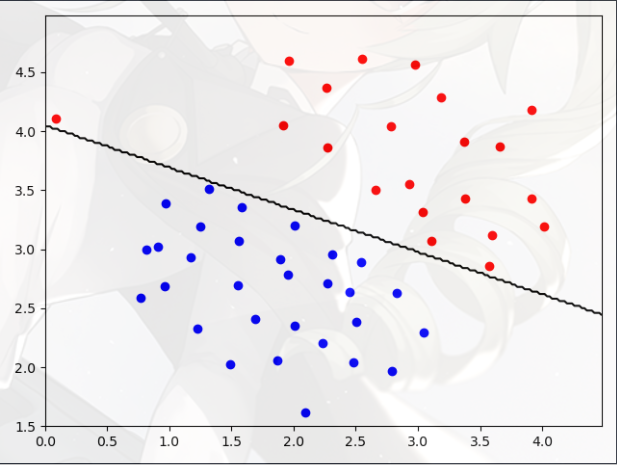
- 观察数据,发现一条直线就可以区分正负样例
- 所以,可以直接使用 SVM
利用 SVM 算法进行拟合:
1 | from sklearn import svm |
函数 visualize_boundary 的实现:绘制决策边界
1 | def visualize_boundary(clf, X, x_min, x_max, y_min, y_max): |
- meshgrid(X , Y):快速生成坐标矩阵 (X , Y)
- arange(x , y):返回一个有终点和起点的固定步长的排列
- predict(x , y):返回样本属于每一个类别的概率(SVM 自带的方法)
绘图:
实现并验证高斯核函数:
1 | # ===================== 3.实现并验证高斯核函数 ===================== |
高斯核函数公式:
代码实现 gaussian_kernel:
1 | import numpy as np |
- 可以类比一下高斯核函数公式
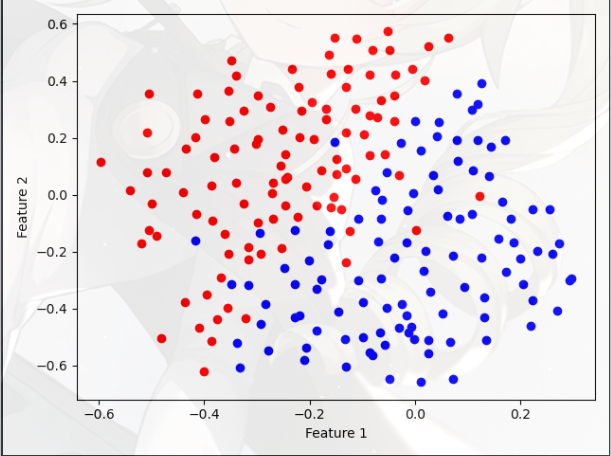
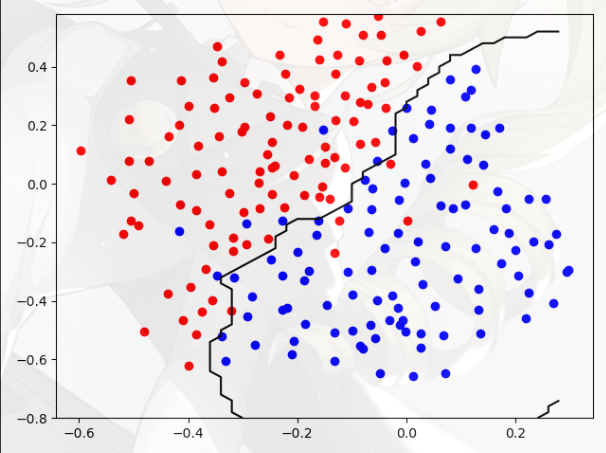
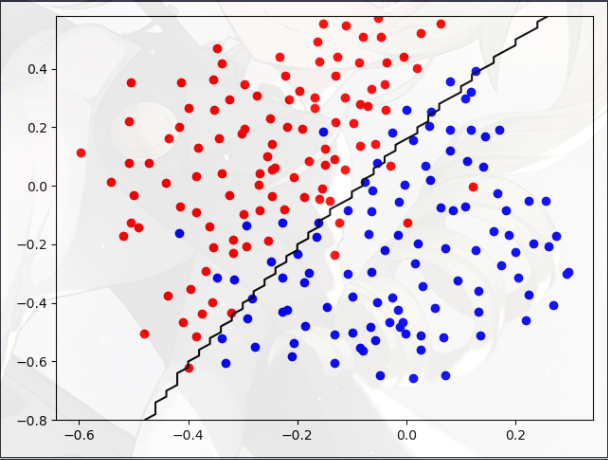
Example Dataset 2(示例数据集 2)
ex6.m 中的下一部分将加载并绘制数据集 2,具体过程:
1 | # ===================== 4.读取数据并可视化2 ===================== |
绘图:
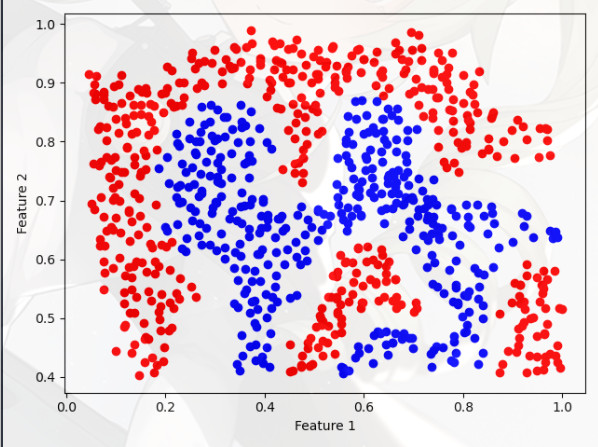
- 从图中可以看出,该数据集没有区分正负样本的线性决策边界
- 这是一个非线性的决策边界,如果像上一部分一样使用只 SVM,拟合的效果就不好
- 但是,通过将高斯核与 SVM 结合使用,您将能够学习一个非线性决策边界,该边界可以对数据集执行得相当好
在这部分练习中,您将使用 SVM 进行非线性分类,特别是,您将在非线性可分的数据集上使用具有高斯核的 SVM
要使用 SVM 找到非线性决策边界,我们需要首先实现一个高斯核,您可以将高斯核视为一个相似度函数,用于测量一对示例之间的“距离”
高斯核函数的公式:
接下来就利用“SVM”和“高斯核”绘制一个非线性区域
1 | # ===================== 5.使用RBF内核训练SVM ===================== |
绘图:
- 只使用 SVM 算法:
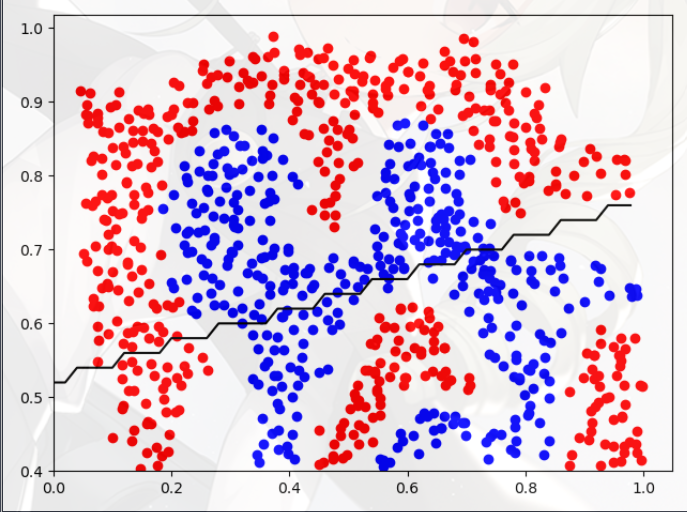
- 同时使用 SVM 算法和高斯核函数:
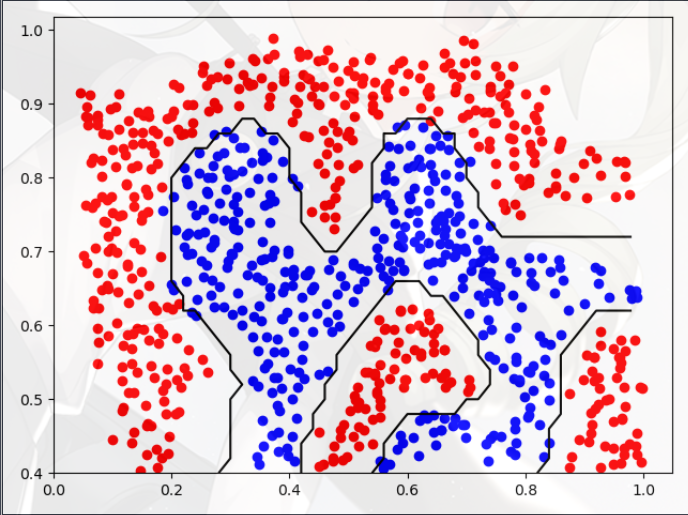
Example Dataset 3(示例数据集 3)
在这部分练习中,您将获得更多关于如何使用具有高斯核的 SVM 的实用技能
ex6.m 的下一部分将加载并显示第三个数据集,您将在此数据集上使用带有高斯核的 SVM
具体过程:
1 | # ===================== 6.读取数据并可视化3 ===================== |
绘图:
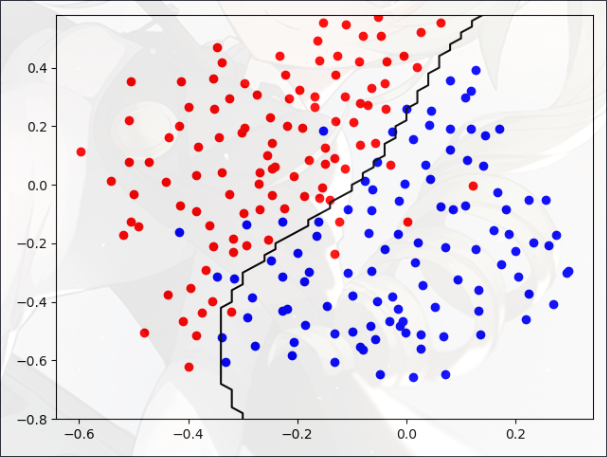
- 看上去是一条线性的决策边界
- 不过我们仍然需要使用高斯核
你的任务是使用交叉验证集 Xval, yval 来确定最佳 C 和 sigma(σ)
- sigma(σ) 过小,会导致方差较大(过拟合)
- sigma(σ) 过大,会导致偏差较大(欠拟合)
1 | # ===================== 7.使用RBF内核训练SVM2 ===================== |
绘图:
- c = 1,sigma = 0.1
- c = 1,sigma = 0.9
- c = 100,sigma = 0.1
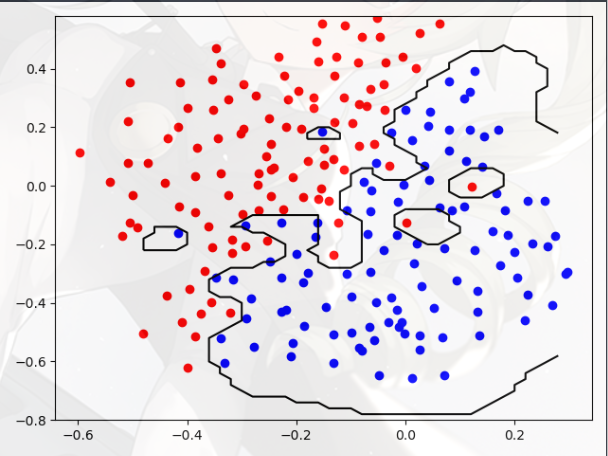
- c = 100,sigma = 0.9
大体的规律如下:
- c 越大,模型的拟合程度越高,过大会导致过拟合
- sigma 越大,决策边界越直,越趋近于“线性核函数”
Spam Classification(垃圾邮件分类)
当今的许多电子邮件服务都提供垃圾邮件过滤器,能够将电子邮件高精度地分类为垃圾邮件和非垃圾邮件
- 在这部分练习中,您将使用 SVM 构建您自己的垃圾邮件过滤器
- 您将训练一个分类器来分类给定的电子邮件 x 是垃圾邮件 (y = 1) 还是非垃圾邮件 (y = 0)
- 特别是,您需要将每封电子邮件转换为一个特征向量 x
- 练习的以下部分将引导您了解如何从电子邮件构建这样的特征向量,在本练习的其余部分,您将使用脚本 ex6_spam.m
- 本练习包含的数据集基于 SpamAssassin 公共语料库的一个子集,在本练习中,您将仅使用电子邮件正文(不包括电子邮件标题)
Preprocessing Emails(预处理电子邮件)
在开始执行机器学习任务之前,查看数据集中的示例通常很有见地
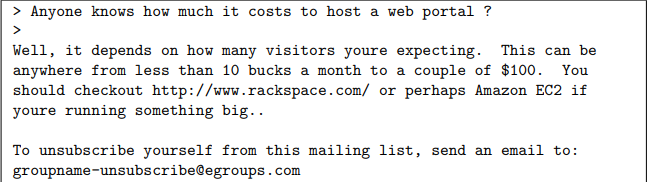
- 上图显示了一个示例电子邮件,其中包含一个 URL、一个电子邮件地址(在末尾)、数字和美元金额,虽然许多电子邮件包含相似类型的实体(例如,数字、其他 URL 或其他电子邮件地址)
- 但几乎每封电子邮件中的特定实体(例如,特定 URL 或特定金额)都会有所不同
- 因此,处理电子邮件时常用的一种方法是“规范化”这些值,以便所有 URL 都被视为相同,所有数字都被视为相同等
- 例如,我们可以将电子邮件中的每个 URL 替换为唯一的字符串 “httpaddr”表示存在 URL
- 这具有让垃圾邮件分类器根据是否存在任何 URL 而不是特定 URL 是否存在来做出分类决定的效果
- 这通常会提高垃圾邮件分类器的性能,因为垃圾邮件发送者通常会随机化 URL,因此在新的垃圾邮件中再次看到任何特定 URL 的几率非常小
预测处理的条目如下:
- 小写:整个电子邮件被转换为小写,因此忽略大写(例如:IndIcaTE 被视为与 Indicate 相同)
- 剥离 HTML:从电子邮件中删除所有 HTML 标记,许多电子邮件通常带有 HTML 格式,我们删除了所有的 HTML 标签,这样就只剩下内容了
- 规范化 URL:所有 URL 都替换为文本 “httpaddr”
- 标准化电子邮件地址:所有电子邮件地址都替换为文本 “emailaddr”
- 规范化数字:所有数字都替换为文本 “数字”
- 标准化美元:所有美元符号 ($) 都替换为文本 “美元”
- 词干:词被简化为词干形式,例如:“discount” 、 “discounts” 、 “discounted” 和 “discounting” 都替换为 “discount”,有时,Stemmer 实际上会从末尾去掉额外的字符,因此“include” 、 “includes” 、 “included” 和 “include” 都替换为 “include”
- 删除非单词:已删除非单词和标点符号,所有空格(制表符、换行符、空格)都已被修剪为单个空格字符
要使用 SVM 将电子邮件分类为垃圾邮件和非垃圾邮件,您首先需要将每封电子邮件转换为特征向量,在这一部分中,您将为每封电子邮件实施预处理步骤,您应该完成 processEmail.py 中的代码以生成给定电子邮件的单词索引向量
预处理函数 processEmail 的实现:
1 | import numpy as np |
具体实现:
1 | # ===================== 1.电子邮件预处理 ===================== |
Extracting Features from Emails(从电子邮件中提取特征)
您现在应该完成 emailFeatures.m 中的代码,以在给定单词索引的情况下为电子邮件生成特征向量
- 您现在将实现将每封电子邮件转换为 Rn 中的向量的特征提取,对于本练习,您将在词汇表中使用 n = # 个单词
- 具体来说,电子邮件的特征 xi(“0” or “1”)对应于字典中的第 i 个单词是否出现在电子邮件中
- 如果电子邮件中存在第 i 个单词,则 xi = 1
- 如果电子邮件中不存在第 i 个单词,则 xi = 0
- 因此,对于典型的电子邮件,此功能看起来像您现在应该完成 emailFeatures.m 中的代码用于生成电子邮件的特征向量,给定单词 indices
特征提取函数 emailFeatures 的实现:
1 | import numpy as np |
- 有点类似于位图
- word_indices 就是邮件的各个单词提取出来后,在单词表中的位置
- 创建数组 features(各个条目初始化为“0”),然后把对应位置的值置为“1”
具体过程:
1 | # ===================== 2.特征提取 ===================== |
Training SVM for Spam Classification(为垃圾邮件分类训练 SVM)
完成特征提取功能后,ex6 spam.m 的下一步将加载一个预处理的训练数据集,该数据集将用于训练 SVM 分类器
- spamTrain.mat 包含 4000 个垃圾邮件和非垃圾邮件的训练示例
- spamTest.mat 包含 1000 个测试示例
- 每封原始电子邮件都使用 processEmail 和 emailFeatures 函数进行处理,并转换为向量 x(i)
- 加载数据集后,ex6 spam.m 将继续训练 SVM 以在垃圾邮件(y=1)和非垃圾邮件(y=0)之间进行分类,训练完成后,您应该看到分类器的训练准确率约为 99.8%,测试准确率约为 98.5%
具体过程:
1 | # ===================== 3.为垃圾邮件分类训练线性SVM ===================== |
接下来进行测试:
1 | # ===================== 4.测试垃圾邮件分类 ===================== |
Top Predictors for Spam(垃圾邮件的主要预测指标)
为了更好地理解垃圾邮件分类器的工作原理,我们可以检查参数以查看分类器认为哪些词最能预测垃圾邮件
- ex6_spam.m 的下一步是在分类器中找到具有最大正值的参数(最高频)并显示相应的单词
- 因此,如果一封电子邮件包含诸如“保证”、“删除”、“美元”和“价格”之类的词(垃圾邮件的高频词汇),它很可能被归类为垃圾邮件
由于我们正在训练的模型是线性 SVM,我们可以检查模型学习的 w 权重,以更好地了解它如何确定电子邮件是否为垃圾邮件,以下代码查找分类器中权重最高的单词,非正式地,分类器“认为”这些词最有可能是垃圾邮件的指标
1 | # ===================== 5.垃圾邮件的主要预测指标 ===================== |
- argsort(arr):返回的是元素值从小到大排序后的索引值的数组
