AttributeError: 'NoneType' object has no attribute 'someTag'
那么我们怎么才能避免这两种情形的异常呢?最简单的方式就是对两种情形进行检查:
1 2 3 4 5 6 7 8 9
try: badContent = bsObj.nonExistingTag.anotherTag except AttributeError as e: print("Tag was not found") else: if badContent == None: print ("Tag was not found") else: print(badContent)
from urllib.request import urlopen from bs4 import BeautifulSoup
html = urlopen("https://www.pythonscraping.com/pages/warandpeace.html") bsObj = BeautifulSoup(html,"html.parser")
namelist = bsObj.findAll("span",{"class":"green"}) # Python字典 - {"A":"B"} for name in namelist: print(name.get_text()) # get_text():把你正在处理的HTML文档中所有的标签都清除,返回一个只包含文字的字符串
1 2 3 4 5 6 7 8
C:\Users\ywx813\anaconda3\python.exe D:/PythonProject/Crawler/test.py Anna Pavlovna Scherer Empress Marya Fedorovna Prince Vasili Kuragin Anna Pavlovna ......
BeautifulSoup 里的 find() 和 findAll() 可能是你最常用的两个方法,借助它们,你可以通过标签的不同属性轻松地过滤 HTML 页面,查找需要的标签组或单个标签
<tr class="gift" id="gift1"><td> /* 打印<tr>(内容为<td>) */ Vegetable Basket </td><td> This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td><td> $15.00 </td><td> <img src="../img/gifts/img1.jpg"/> </td></tr>
<tr class="gift" id="gift2"><td> Russian Nesting Dolls </td><td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td><td> $10,000.52 </td><td> <img src="../img/gifts/img2.jpg"/> </td></tr>
<tr class="gift" id="gift3"><td> Fish Painting </td><td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td><td> $10,005.00 </td><td> <img src="../img/gifts/img3.jpg"/> </td></tr>
<tr class="gift" id="gift4"><td> Dead Parrot </td><td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td><td> $0.50 </td><td> <img src="../img/gifts/img4.jpg"/> </td></tr>
<tr class="gift" id="gift5"><td> Mystery Box </td><td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td><td> $1.50 </td><td> <img src="../img/gifts/img6.jpg"/> </td></tr>
进程已结束,退出代码 0
直观来看,下图中的标签就是“giftList”的子标签,程序就打印了对应几个 <tr> 框架
采用 .descendants,则可以打印所有后代标签
1 2 3 4 5 6 7 8
from urllib.request import urlopen from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html") bsObj = BeautifulSoup(html,"html.parser")
for child in bsObj.find("table",{"id":"giftList"}).descendants: print(child)
<tr><th> /* 打印<tr> */ Item Title </th><th> Description </th><th> Cost </th><th> Image </th></tr> <th> /* 打印<th> */ Item Title </th>
Item Title /* 打印<th>框架中的内容 */
<th> Description </th>
Description
<th> Cost </th>
Cost
<th> Image </th>
Image
<tr class="gift" id="gift1"><td> /* 打印<tr> */ Vegetable Basket </td><td> This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td><td> $15.00 </td><td> <img src="../img/gifts/img1.jpg"/> </td></tr> <td> /* 打印<td> */ Vegetable Basket </td>
Vegetable Basket /* 打印<td>框架中的内容 */
<td> /* 打印<td> */ This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td>
This vegetable basket is the perfect gift for your health conscious (or overweight) friends! /* 打印<td>框架中的内容 */
<span class="excitingNote">Now with super-colorful bell peppers!</span> Now with super-colorful bell peppers!
<td> /* 打印<td> */ $15.00/* 打印<td>框架中的内容 */ </td>
$15.00
<td> <img src="../img/gifts/img1.jpg"/> </td>
<img src="../img/gifts/img1.jpg"/>
<tr class="gift" id="gift2"><td> Russian Nesting Dolls </td><td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td><td> $10,000.52 </td><td> <img src="../img/gifts/img2.jpg"/> </td></tr> <td> Russian Nesting Dolls </td>
Russian Nesting Dolls
<td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td>
Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> 8 entire dolls per set! Octuple the presents!
<td> $10,000.52 </td>
$10,000.52
<td> <img src="../img/gifts/img2.jpg"/> </td>
<img src="../img/gifts/img2.jpg"/>
<tr class="gift" id="gift3"><td> Fish Painting </td><td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td><td> $10,005.00 </td><td> <img src="../img/gifts/img3.jpg"/> </td></tr> <td> Fish Painting </td>
Fish Painting
<td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td>
If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> Also hand-painted by trained monkeys!
<td> $10,005.00 </td>
$10,005.00
<td> <img src="../img/gifts/img3.jpg"/> </td>
<img src="../img/gifts/img3.jpg"/>
<tr class="gift" id="gift4"><td> Dead Parrot </td><td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td><td> $0.50 </td><td> <img src="../img/gifts/img4.jpg"/> </td></tr> <td> Dead Parrot </td>
Dead Parrot
<td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td>
This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> Or maybe he's only resting?
<td> $0.50 </td>
$0.50
<td> <img src="../img/gifts/img4.jpg"/> </td>
<img src="../img/gifts/img4.jpg"/>
<tr class="gift" id="gift5"><td> Mystery Box </td><td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td><td> $1.50 </td><td> <img src="../img/gifts/img6.jpg"/> </td></tr> <td> Mystery Box </td>
Mystery Box
<td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td>
If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> Keep your friends guessing!
<tr class="gift" id="gift1"><td> Vegetable Basket </td><td> This vegetable basket is the perfect gift for your health conscious (or overweight) friends! <span class="excitingNote">Now with super-colorful bell peppers!</span> </td><td> $15.00 </td><td> <img src="../img/gifts/img1.jpg"/> </td></tr>
<tr class="gift" id="gift2"><td> Russian Nesting Dolls </td><td> Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span> </td><td> $10,000.52 </td><td> <img src="../img/gifts/img2.jpg"/> </td></tr>
<tr class="gift" id="gift3"><td> Fish Painting </td><td> If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span> </td><td> $10,005.00 </td><td> <img src="../img/gifts/img3.jpg"/> </td></tr>
<tr class="gift" id="gift4"><td> Dead Parrot </td><td> This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span> </td><td> $0.50 </td><td> <img src="../img/gifts/img4.jpg"/> </td></tr>
<tr class="gift" id="gift5"><td> Mystery Box </td><td> If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span> </td><td> $1.50 </td><td> <img src="../img/gifts/img6.jpg"/> </td></tr>
from urllib.request import urlopen from bs4 import BeautifulSoup import re
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon") bsObj = BeautifulSoup(html, "html.parser")
for link in bsObj.find("div", {"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$")): if'href'in link.attrs: print(link.attrs['href'])
from urllib.request import urlopen from bs4 import BeautifulSoup import re
pages = set() defgetLinks(pageUrl): global pages html = urlopen("http://en.wikipedia.org"+pageUrl) bsObj = BeautifulSoup(html,"html.parser") for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")): if'href'in link.attrs: if link.attrs['href'] notin pages: newPage = link.attrs['href'] print(newPage) pages.add(newPage) getLinks(newPage)
from urllib.request import urlopen from bs4 import BeautifulSoup import re
pages = set() defgetLinks(pageUrl): global pages html = urlopen("http://en.wikipedia.org"+pageUrl) bsObj = BeautifulSoup(html,"html.parser") try: print(bsObj.h1.get_text()) print(bsObj.find(id="mw-content-text").findAll("p")[0]) print(bsObj.find(id="ca-edit").find("span").find("a").attrs['href']) except AttributeError: print("The page is missing some properties! But don't worry!")
for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")): if'href'in link.attrs: if link.attrs['href'] notin pages: newPage = link.attrs['href'] print(newPage) pages.add(newPage) getLinks(newPage)
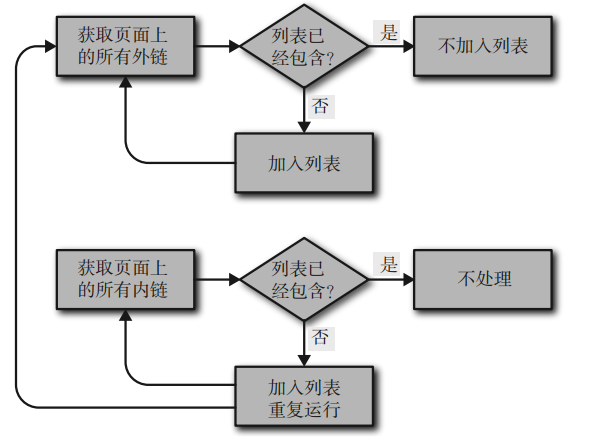
defgetInternalLinks(bsObj, includeUrl):# 获取页面所有内链的列表 internalLinks = [] for link in bsObj.findAll("a", href=re.compile("^(/|.*"+includeUrl+")")): if link.attrs['href'] isnotNone: if link.attrs['href'] notin internalLinks: internalLinks.append(link.attrs['href']) return internalLinks
defgetExternalLinks(bsObj, excludeUrl):# 获取页面所有外链的列表 externalLinks = [] for link in bsObj.findAll("a",href=re.compile("^(http|www)((?!"+excludeUrl+").)*$")): if link.attrs['href'] isnotNone: if link.attrs['href'] notin externalLinks: externalLinks.append(link.attrs['href']) return externalLinks
defgetAllExternalLinks(siteUrl): html = urlopen(siteUrl) bsObj = BeautifulSoup(html) internalLinks = getInternalLinks(bsObj,splitAddress(siteUrl)[0]) externalLinks = getExternalLinks(bsObj,splitAddress(siteUrl)[0]) for link in externalLinks: if link notin allExtLinks: allExtLinks.add(link) print(link) for link in internalLinks: if link notin allIntLinks: print("即将获取链接的URL是:"+link) allIntLinks.add(link) getAllExternalLinks(link) getAllExternalLinks("http://oreilly.com")