Proxy Lab
网络代理是一个在网络浏览器和终端服务器之间充当中间人的程序,而不是直接联系终端服务器以获取网页,浏览器会联系代理,代理会转发请求发送到终端服务器
当终端服务器回复代理时,代理将回复发送到浏览器
代理有很多用途:
- 有时在防火墙中使用代理,因此防火墙只能通过代理与防火墙之外的服务器联系
- 代理也可以充当匿名者:通过剥离所有标识信息的请求
- 代理可以使浏览器对Web匿名服务器
- 代理甚至可以通过存储来自服务器的对象的本地副本来缓存web对象,通过从缓存中读取请求来响应未来的请求,而不是通过再次与远程服务器
在本实验室中,您将编写一个简单的HTTP代理来缓存web对象,在实验室的第一部分,你将设置代理以接受传入连接、读取和分析请求、将请求转发到web服务器、读取服务器的响应,并将这些响应转发给相应的客户端
第一部分:您将学习基本的HTTP操作,以及如何使用套接字编写通信程序通过网络连接
第二部分:您将升级代理以处理多个并发事件连接,这将向您介绍如何处理并发性,这是一个至关重要的系统概念
第三部分:您将使用一个简单的最近访问的内存缓存向代理添加缓存网络内容
实验文件
- proxy.c:启动代理服务器的代码写在此处
- tiny:Tiny web服务器的源代码
- driver.sh:打分文件
在开始实验前,需要一些储备知识:
服务器简析
每个网络应用都是基于客户端—服务器模型的,釆用这个模型,一个应用是由 一个服务器进程 和一个或者多个 客户端 进程组成

个客户端—服务器事务由以下四步组成:
- 当一个客户端需要服务时,它向服务器发送一个请求,发起一个事务,例如,当 Web 浏览器需要一个文件时,它就发送一个请求给 Web 服务器
- 服务器收到请求后,解释它,并以适当的方式操作它的资源,例如,当 Web 服务器收到浏览器发出的请求后,它就读一个磁盘文
- 服务器给客户端发送一个响应,并等待下一个请求,例如,Web 服务器将文件发送回客户端
- 客户端收到响应并处理它,例如,当 Web 浏览器收到来自服务器的一页后,就在屏幕上显示此页
服务器请求
一般的请求消息如下代码所示:
1 | GET /home.html HTTP/1.0 <!-- 请求消息行 --> |
请求消息行:请求消息的第一行为请求消息行
- 例如:GET /test/test.html HTTP/1.1
- GET 为请求方式,请求方式分为:Get(默认)、POST、DELETE、HEAD等
- GET:明文传输 不安全,数据量有限,不超过1kb
- POST:暗文传输,安全,数据量没有限制
- /test/test.html 为URI,统一资源标识符
- HTTP/1.1 为协议版本
请求消息头:从第二行开始到空白行统称为请求消息头
- Accept:浏览器可接受的MIME类型告诉服务器客户端能接收什么样类型的文件
- Accept-Charset:浏览器通过这个头告诉服务器,它支持哪种字符集
- Accept-Encoding:浏览器能够进行解码的数据编码方式,比如 gzip
- Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到,可以在浏览器中进行设置
- Host:初始URL中的主机和端口
- Referrer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
- Content-Type:内容类型告诉服务器浏览器传输数据的MIME类型,文件传输的类型
- If-Modified-Since:利用这个头与服务器的文件进行比对,如果一致,则从缓存中直接读取文件
- User-Agent:浏览器类型
- Content-Length:表示请求消息正文的长度
- Connection:表示是否需要持久连接。如果服务器看到这里的值为“Keep -Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接)
- Cookie:用于分辨两个请求是否来自同一个浏览器,以及保存一些状态信息
- Date:请求时间GMT
消息正文:当请求方式是[POST]方式时,才能看见消息正文,消息正文就是要传输的一些数据,如果没有数据需要传输时,消息正文为空
服务器响应
一般的请求消息如下代码所示:
1 | HTTP/1.0 200 OK <!-- 响应消息行 --> |
- 响应消息行:第一行响应消息为响应消息行
- 例如:HTTP/1.0 200 OK
- HTTP/1.0 为协议版本
- 200 为响应状态码,常用的响应状态码有40余种,这里我们仅列出几种,详细请看:
- 200:一切正常
- 302/307:临时重定向
- 304:未修改,客户端可以从缓存中读取数据,无需从服务器读取
- 404:服务器上不存在客户端所请求的资源
- 500:服务器内部错误
- OK 为状态码描述
- 响应消息头:
- Location:指示新的资源的位置通常和302/307一起使用,完成请求重定向
- Server:指示服务器的类型
- Content-Encoding:服务器发送的数据采用的编码类型
- Content-Length:告诉浏览器正文的长度
- Content-Language:服务发送的文本的语言
- Content-Type:服务器发送的内容的MIME类型
- Last-Modified:文件的最后修改时间
- Refresh:指示客户端刷新频率,单位是秒
- Content-Disposition:指示客户端下载文件
- Set-Cookie:服务器端发送的Cookie
- Expires:-1
- Cache-Control:no-cache (1.1)
- Pragma:no-cache (1.0) 表示告诉客户端不要使用缓存
- Connection:close/Keep-Alive
- Date:请求时间
- 响应正文:即网页的源代码(F12可查看)
网络编程结构体
通用结构体:struct sockaddr,16个字节
1 | /* Generic socket address structure (for connect, bind, and accept) */ |
struct sockaddr 是一个通用地址结构,这是为了统一地址结构的表示方法,统一接口函数,使不同的地址结构可以被bind() , connect() 等函数调用
sockaddr的缺陷:sa_data 把目标地址和端口信息混在一起了
通用结构体:struct sockaddr_storage,128个字节
1 | /* Structure large enough to hold any socket address |
struct sockaddr_storage 被设计为同时适合 struct sockaddr_in 和 struct sockaddr_in6
为了避免试图知道要使用的IP版本,可以使用 struct sockaddr_storage,该版本可以保存其中任何一个,后将通过 connect(),bind() 等函数将其类型转换为 struct sockaddr 并以这种方式进行访问
IPv4:struct sockaddr_in,16个字节
1 | /* IP socket address structure */ |
该结构体解决了 sockaddr 的缺陷,把 port 和 addr 分开储存在两个变量中
IPv6:struct sockaddr_in6,28个字节
1 | struct sockaddr_in6 { |
网络编程中的信号
进程组
进程组就是一系列相互关联的进程集合,系统中的每一个进程也必须从属于某一个进程组,每个进程组中都会有一个唯一的 ID(process group id),简称 PGID,PGID 一般等同于进程组的创建进程的 Process ID,而这个进进程一般也会被称为进程组先导(process group leader),同一进程组中除了进程组先导外的其他进程都是其子进程
进程组的存在,方便了系统对多个相关进程执行某些统一的操作,例如:我们可以一次性发送一个信号量给同一进程组中的所有进程
会话
会话(session)是一个若干进程组的集合,同样的,系统中每一个进程组也都必须从属于某一个会话
- 一个会话只拥有最多一个控制终端(也可以没有),该终端为会话中所有进程组中的进程所共用
- 一个会话中前台进程组只会有一个,只有其中的进程才可以和控制终端进行交互,除了前台进程组外的进程组,都是后台进程组
和进程组先导类似,会话中也有会话先导(session leader)的概念,用来表示建立起到控制终端连接的进程,在拥有控制终端的会话中,session leader 也被称为控制进程(controlling process),一般来说控制进程也就是登入系统的 shell 进程(login shell)
带外数据
带外数据用于迅速告知对方本端发生的重要的事件,它比普通的数据(带内数据)拥有更高的优先级, 不论发送缓冲区中是否有排队等待发送的数据,它总是被立即发送 ,带外数据的传输可以使用一条独立的传输层连接,也可以映射到传输普通数据的连接中,
// 实际应用中,带外数据是使用很少见,有 telnet 和 ftp 等远程非活跃程序
UDP没有没有实现带外数据传输,TCP也没有真正的带外数据,不过TCP利用头部的紧急指针标志和紧急指针,为应用程序提供了一种紧急方式,含义和带外数据类似,TCP的紧急方式利用传输普通数据的连接来传输紧急数据
SIGHUP信号(关闭进程)
SIGHUP 信号在 用户终端连接(正常或非正常)结束 时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业(任务),这时它们与控制终端不再关联
系统对SIGHUP信号的默认处理是:终止收到该信号的进程 ,所以若程序中没有捕捉该信号,当收到该信号时,进程就会退出
SIGHUP会在以下3种情况下被发送给相应的进程:
- 终端关闭时,该信号被发送到 session 首进程以及作为 job 提交的进程(即用 & 符号提交的进程)
- session 首进程退出时,该信号被发送到该 session 中的前台进程组中的每一个进程
- 若父进程退出导致进程组成为孤儿进程组,且该进程组中有进程处于停止状态(收到SIGSTOP或SIGTSTP信号),该信号会被发送到该进程组中的每一个进程
例如:在我们登录Linux时,系统会分配给登录用户一个终端(Session),在这个终端运行的所有程序,包括前台进程组和后台进程组,一般都属于这个 Session,当用户退出Linux登录时,前台进程组和后台有对终端输出的进程将会收到SIGHUP信号,这个信号的默认操作为终止进程,因此前台进程组和后台有终端输出的进程就会中止
// 晦涩难懂,需要在实例中理解分析
SIGPIPE信号(告知中断)
当 往一个写端关闭的管道或 socket 连接中连续写入数据时会引发 SIGPIPE 信号(引发 SIGPIPE 信号的写操作将设置 errno 为EPIPE)
在TCP通信中,当通信的双方中的一方close一个连接时,若另一方接着发数据,根据TCP协议的规定,会收到一个RST(Reset the connection)响应报文,若再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不能再写入数据
- 即使断开还可以进行一次通信,第二次发送数据时才触发SIGPIPE
- 可以用相应的 handle 进行处理SIGPIPE,完成想要的操作
服务器代码:
1 | void handle(int sig) // 处理程序 |
客户端代码:
1 | int main() |
结果:

依次触发:write_msg1,handle,write_msg2
此外,因为SIGPIPE信号的默认行为是结束进程,而我们绝对不希望因为写操作的错误而导致程序退出,尤其是作为服务器程序来说就更恶劣了。所以我们应该对这种信号加以处理,在这里,介绍两种处理SIGPIPE信号的方式:
- 给SIGPIPE设置SIG_IGN信号处理函数,忽略该信号:
1 | signal(SIGPIPE, SIG_IGN); |
前文说过,引发SIGPIPE信号的写操作将设置errno为EPIPE,所以,第二次往关闭的socket中写入数据时,会返回-1,同时errno置为EPIPE,这样,便能知道对端已经关闭,然后进行相应处理,而不会导致整个进程退出
- 使用send函数的MSG_NOSIGNAL标志来禁止写操作触发SIGPIPE信号:
1 | send(sockfd , buf , size , MSG_NOSIGNAL); |
同样,我们可以根据send函数反馈的errno来判断socket的读端是否已经关闭
此外,我们也可以通过IO复用函数来检测管道和socket连接的读端是否已经关闭,以POLL为例,当socket连接被对方关闭时,socket上的POLLRDHUP事件将被触发
SIGURG信号
内核通知应用程序带外数据到达的方式有两种:
- 一种就是利用IO复用技术的系统调用(如select)在接受到带外数据时将返回,并向应用程序报告socket上的异常事件
- 另一种方法就是使用SIGURG信号
参考:网络编程的三个重要信号
套接字接口
套接字接口(socket interface)是一组函数,它们和 Unix I/O 函数结合起来,用以创建网络应用
大多数现代系统上都实现套接字接口,包括所有的 Unix 变种、Windows 和 Macintosh 系统
// 从 Linux 内核的角度来看,一个套接字就是 通信的一个端点 ,从 Linux 程序的角度来看,套接字就是一个 有相应描述符的打开文件
因特网的套接字地址存放在所示的类型为 sockaddr_in 的 16 字节结构中(IP 地址和端口号总是以网络字节顺序(大端法)存放的)
下面将介绍套接字接口中的部分函数:
1 | int socket(int domain, int type, int protocol); |
// 协议族决定了 socket 的地址类型,在通信中必须采用对应的地址
socket 函数 用于来返回一个 套接字描述符 (clientfd)
- 套接字描述符:用来标定系统为当前的进程划分的一块缓冲空间,类似于文件描述符
- 文件描述符:是内核为了高效管理已被打开的文件所创建的索引,用于指代被打开的文件,对文件所有 I/O 操作相关的系统调用都需要通过文件描述符(open的返回值fd)
1 | int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); |
bind 函数 告诉内核将 addr 中的服务器套接字地址和套接字描述符 sockfd 联系起来
// bind函数把一个本地协议地址赋予一个套接字
1 | int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen); |
connect 函数 试图与 “套接字地址为 addr 的服务器” 建立一个因特网连接
如果成功,clientfd 描述符现在就准备好可以读写了(最好用 getaddrinfo 来为 connect 提供参数)
1 | int listen(int sockfd, int backlog); |
listen 函数 将 sockfd 从一个 主动套接字 转化为一个 监听套接字 (listening socket),该套接字可以接受来自客户端的连接请求
1 | int accept(int listenfd, struct sockaddr *addr, int *addrlen); |
accept 函数 等待来自客户端的连接请求到达侦听描述符 listenfd,然后在 addr 中填写客户端的套接字地址,并返回一个 已连接描述符
一个服务器通常通常仅仅只创建一个监听socket描述字,内核为每个由服务器进程接受的客户连接创建了一个已连接socket描述字,当服务器完成了对某个客户的服务,相应的已连接socket描述字就被关闭
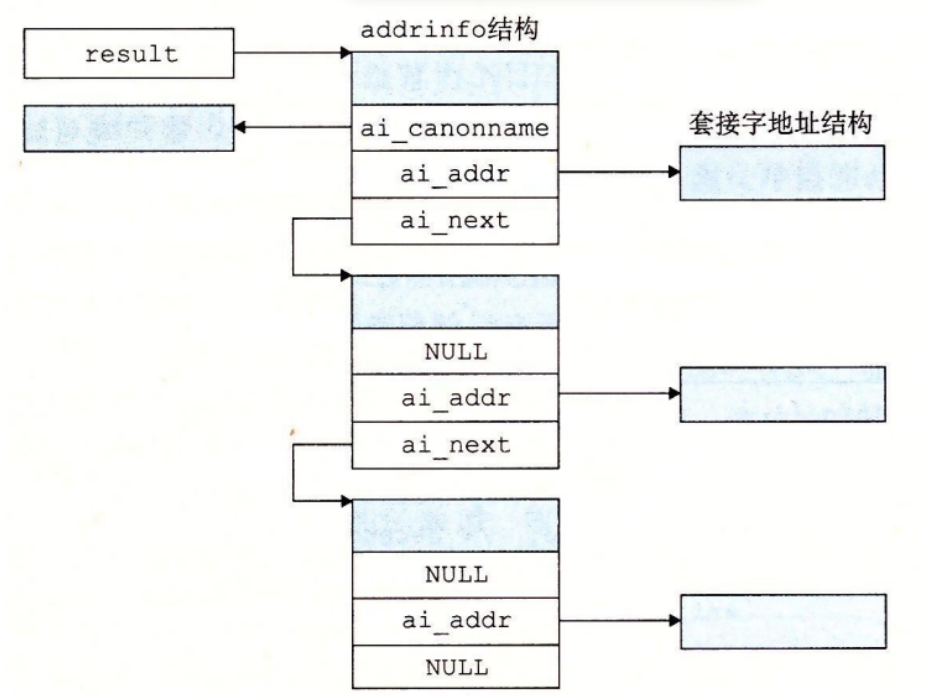
1 | int getaddrinfo(const char *host, const char *service, |
getaddrinfo 函数 将主机名、主机地址、服务名和端口号的字符串表示转化成套接字地址结构,它是已弃用的 gethostbyname 和 getservbyname 函数的新的替代品
在客户端调用了 getaddrinfo 之后,会遍历这个列表,依次尝试每个套接字地址,直到调用 socket 和 connect 成功,建立起连接,类似地,服务器会尝试遍历列表中的每个套接字地址,直到调用 socket 和 bind 成功,描述符会被绑定到一个合法的套接字地址,
- 为了避免内存泄漏,应用程序必须在最后调用 freeaddrinfo,释放该链表
- 如果 getaddrinfo 返回非零的错误代码,应用程序可以调用 gai_streeror,将该代码转换成消息字符串
1 | struct addrinfo { |
1 | int getnameinfo(const struct sockaddr *sa, socklen_t salen, |
getnameinfo 函数 和 getaddrinfo 是相反的,将一个套接字地址结构转换成相应的主机和服务名字符串,它是已弃用的 gethostbyaddr 和 getservbyport 函数的新的替代品
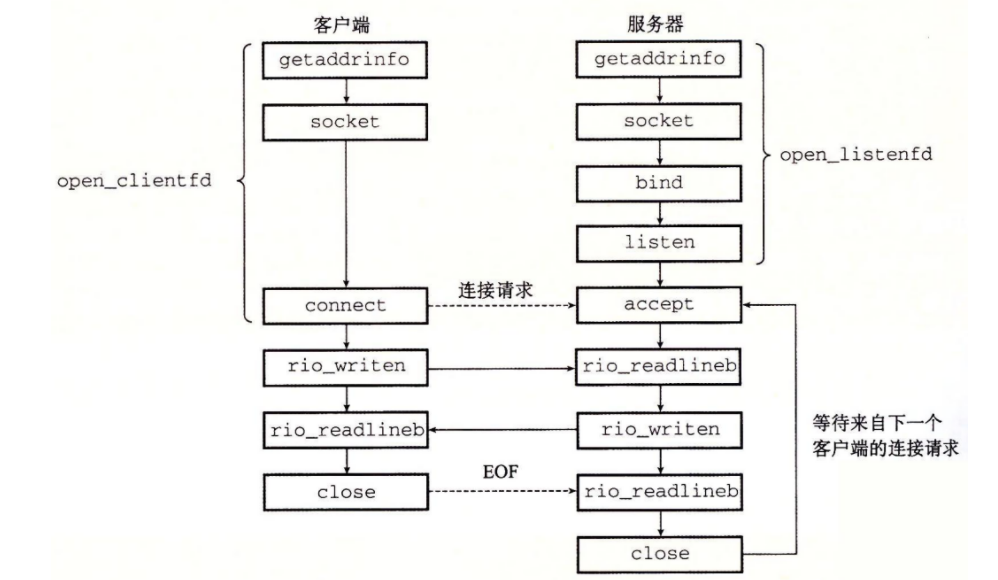
1 | int open_clientfd(char *hostname, char *port); |
客户端调用 open_clientfd 建立与服务器的连接
open_clientfd 函数 建立与服务器的连接,该服务器运行在主机 hostname 上,并在端口号 port 上监听连接请求
1 | int open_listenfd(char *port); |
open_listenfd 函数 打开和返回一个监听描述符,这个描述符准备好在端口 port_h 接收连接请求
echo 客户端案例:
1 |
|
在和服务器建立连接之后,客户端进入一个循环,反复从标准输入读取文本行,发送文本行给服务器,从服务器读取回送的行,并输出结果到标准输出
当 fgets 在标准输入上遇到 EOF 时,或者因为用户在键盘上键入 Ctrl+D,或者因为在一个重定向的输入文件中用尽了所有的文本行时,循环就终止
echo 服务器案例:
1 |
|
在打开监听描述符后,它进入一个无限循环,每次循环都等待一个来自客户端的连接请求,输出已连接客户端的域名和 IP 地址,并调用 echo 函数为这些客户端服务,在 echo 程序返回后,主程序关闭已连接描述符,一旦客户端和服务器关闭了它们各自的描述符,连接也就终止了
echo函数将反复读写文本行,直到rio_readlineb函数遇到EOF
参考:Socket原理讲解
多线程编程
多线程是多任务处理的一种特殊形式,多任务处理允许让电脑 同时 运行两个或两个以上的程序,一般情况下,两种类型的多任务处理:基于进程 和 基于线程
- 基于进程的多任务处理是程序的并发执行
- 基于线程的多任务处理是同一程序的片段的并发执行
多线程程序包含可以同时运行的两个或多个部分,这样的程序中的每个部分称为一个线程,每个线程定义了一个单独的执行路径
C语言中有专门控制线程的函数:
创建新线程
1 | pthread_create (thread, attr, start_routine, arg); |
- thread:指向线程标识符的指针
- attr:一个不透明的属性对象,可以被用来设置线程属性,您可以指定线程属性对象,也可以使用默认值 NULL
- start_routine:线程运行函数起始地址,一旦线程被创建就会执行(通常设置为某个函数)
- arg:运行函数的参数,它必须通过把引用作为指针强制转换为 void 类型进行传递,如果没有传递参数,则使用 NULL
pthread_create 创建一个新的线程,并让它可执行目标函数
终止线程
1 | pthread_exit (status); |
显式地退出一个线程,通常情况下,pthread_exit() 函数是在线程完成工作后无需继续存在时被调用,如果 main() 是在它所创建的线程之前结束,并通过 pthread_exit() 退出,那么其他线程将继续执行,否则,它们将在 main() 结束时自动被终止
连接和分离线程
1 | pthread_join (threadid, status) |
- pthread_join() 阻塞等待线程退出(直到指定的 threadid 线程终止为止),获取线程退出状态
- pthread_detach() 表示主线程与子线程(threadid)分离,两者相互不干涉,子线程结束同时子线程的资源自动回收
当创建一个线程时,它的某个属性会定义它是否是可连接的(joinable)或可分离的(detached),只有创建时定义为可连接的线程才可以被连接,如果线程创建时被定义为可分离的,则它永远也不能被连,pthread_join() 函数来等待线程的完成
// pthread库不是Linux系统默认的库,连接时需要使用库libpthread.a, 在使用pthread_create创建线程时,在编译中要加-lpthread参数:
1 | gcc test.c -lpthread -o test |
案例:pthread_join
1 |
|
1 | ➜ [/home/ywhkkx/桌面] gcc test.c -lpthread -o test |
把“pthread_join(tid, (void **)&retval)”注释掉以后:
1 | ➜ [/home/ywhkkx/桌面] gcc test.c -lpthread -o test |
发现主线程和副线程的执行次序改变了(主副线程同时执行,但是主线程先操作“retval”变量)
添加了“pthread_join”后,主线程就会被阻塞,直到标识符“tid”代表的副线程终止后,主线程才开始执行(需要副线程先给“retval”变量赋值后,主线程才可以打印出来)
案例:pthread_detach
1 |
|
1 | ➜ [/home/ywhkkx/桌面] gcc test.c -lpthread -o test |
线程可以被置为 detach 状态,这样的线程一旦终止就立刻回收它占用的所有资源,而不保留终止状态,不能对一个已经处于detach状态的线程调用pthread_join,这样的调用将返回EINVAL错误
参考:C语言多线程操作
实验一:实现顺序web代理
实现一个顺序执行的代理,它可以处理GET方法并转发,对于其他方法可以不实现
命令行调用 “./proxy < port >” 来启动代理服务器,其中 port 可以通过实验包中的工具 port-for-user 来获取
测试服务器
运行该服务器,指定一个端口,必须是1024–49151之间的端口,其余端口不能使用
1 | ➜ [/home/ywhkkx/proxylab-handout/tiny] ./tiny 1444 |
在运行了TINY 服务器的基础上,打开另一个terminal,在linux shell输入:
1 | ➜ [/home/ywhkkx/proxylab-handout/tiny] telnet localhost 1444 |
此时服务端的内容:
1 | ➜ [/home/ywhkkx/proxylab-handout/tiny] ./tiny 1444 |
理解服务器代码
1 |
|
Tiny是一个迭代服务器,监听在命令行中确定的端口上的连接请求,在通过 open_listenedfd 函数打开一个监听套接字以后,Tiny执行典型的无限服务循环,反复地接受一个连接(accept)请求,执行事务(doit),最后关闭连接描述符(close)
编写代理
网络代理是一个在网络浏览器和终端服务器之间充当中间人的程序,而不是直接联系终端服务器以获取网页,浏览器会联系代理,代理会转发请求发送到终端服务器
用户在代理中输入指令,代理会解析指令并发送到服务器,同时它也会接收服务器上的反馈,并返回给用户
先抄 TINY 的框架:
1 |
|
下面编写两个 改动&新增 的函数:(这两个函数需要按照 “实验要求” 进行编写)
实验要求 消息请求行&消息请求头为:
1 | GET /hub/index.html HTTP/1.0 |
而我们在 Proxy 写入的指令为:(其中“GET”和“HTTP/1.0”已经被处理)
1 | GET http://www.cmu.edu/hub/index.html HTTP/1.0 |
所以这两个函数的作用,就是把 uri(统一资源标识符)转化为请求:
1 | void parse_uri(char *uri,char *hostname,char *path,int *port) { |
1 | void build_requesthdrs(rio_t *rp, char *newreq, char *hostname, char* port) { |
整体逻辑:
- 代理的前半部分和服务器如出一辙,先作为服务器链接用户端,然后调用 doit 启动自身服务,在 doit 中为“用户端的描述符”绑定内存空间,并把用户端信息复制到该空间,接着输入指令装入其中,并调用 parse_uri 进行解析
- 代理的后半部分又将作为客户端与目标服务器进行通信,先连接服务器并生成描述符,接着用类似的操作为“服务端的描述符”绑定内存空间,然后调用 build_requesthdrs 生成对应的服务请求,最后发送服务请求并打印数据
打分:
1 | ➜ [/home/ywhkkx/proxylab-handout] ./driver.sh |
实验二:实现多线程web代理
整体变化不大,直接挂代码了:(我会标记改动的地方)
1 |
|
打分:
1 | *** Concurrency *** |
实验三:缓存web对象
要求实现缓存客户端的请求
- 其中最大的缓存块大小要小于 MAX_OBJECT_SIZE(102400)
- 总的缓存大小 MAX_CACHE_SIZE(1049000)
- cache需要牺牲缓存块时,运用LRU算法
- 在实现过程中需要解决不同线程同时访问cache的问题
定义cache结构体
1 |
|
LRU(基于系统时间)+隐式+暴力获取(直接遍历所有cache)
1 | const int cache_block_size[] = {102, 1024, 5120 ,10240,25600, 102400}; |
关于锁我没有深入学习,这里挂个博客:读写锁函数说明
最后需要把这些函数插入到原来的代码中:
1 |
|
打分:
1 | *** Cache *** |