Ptmalloc算法:off-by-one
在堆溢出的基础上,只溢出1字节,这就是off-by-one
想了解这个漏洞必须先了解 chunk 的结构
数据结构chunk
什么是chunk?用户申请的内存空间就被称为chunk
在ptmalloc算法中,用户申请的内存空间以chunk为单位进行管理,它的结构入下图:
1 | struct malloc_chunk { |
一共有6个部分,其中最后两个部分是 large chunk 特有的
- prev_size:相邻的前一个堆块大小(该字段不计入当前堆块的大小计算,free状态时:数据为前一个chunk的大小,allocate状态时:用于前一个chunk写入数据)
- size:本堆块的长度(长度计算方式:size字段长度+用户申请的长度+对齐,最后3位标志位)
- fd&bk:双向指针,用于组成一个双向空闲链表
- fd_nextsize:指向前一个与当前 chunk 大小不同的第一个空闲块
- bk_nextsize:指向后一个与当前 chunk 大小不同的第一个空闲块
chunk有两种状态:allocate chunk 和 free chunk
allocate chunk:用户正在使用的chunk,fd&bk处用于存放数据
free chunk:程序中空闲的chunk,fd&bk分别为指向 “后一个free chunk”和“前一个free chunk”
也就是说,只有allocate chunk中会存放数据,而free chunk会以双向链表的形式存储起来
allocate chunk:
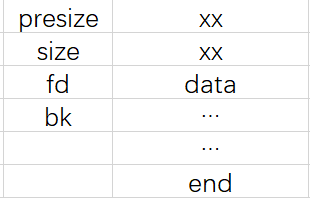
free chunk:

程序该怎样分辨chunk的状态?
在解释这一点之前,先要了解一下内存对齐
内存对齐是为了“程序执行效率”而诞生的一种机制,它可以优化CPU识别地址的效率
glibc的堆内存对齐机制:
32位:
最少分配16字节堆,8字节对齐,每次增加8
其中4字节为头部,申请1-12堆,分配16字节堆
64位:
最少分配32字节堆,16字节对齐,每次增加16
其中8字节为头部,申请1-24堆,分配32字节堆
不管是32位(8字节对齐),还是64位(16字节对齐),chunk的大小都是 8的倍数 ,也就是说,chunk -> size 的最后3位恒为“0”,ptmalloc算法干脆就把这3位当成了标志位,用于描述一些chunk的信息

P位:指示相邻的前一个堆块是alloc还是free
M位:是否属于主进程
N位:是否由 mmap() 分配
chunk分类
除了根据P位进行的分类:allocate chunk & free chunk
还有:top chunk & last remainder chunk
glibc提供给用户的chunk主要就分为这4类
- top chunk:处于一个arena的最顶部(即最高内存地址处)的chunk
- last remainder chunk:unsorted bin中的最后一个chunk
这里引入了“bin”的概念,不过我想在UAF中分析“bin”,这里就先提一下吧:
- small chunk:小于512(1024)字节的chunk
- large chunk:大于512(1024)字节的chunk
chunk合并
先说说off-by-one的效果
两个相邻的chunk中(“chunk1”和“chunk2”),对“chunk1”进行操作(通常要用到UAF)使其溢出一字节到“chunk2”中,而它就会覆盖“chunk2”的presize的最后一字节
看上去好像没什么作用,但它的威力的确很大
因为在free掉“chunk2”后会发生 chunk合并,一共有两种合成方式:
向前合并(将要被free的chunk作为素材,被后一个chunk合并)
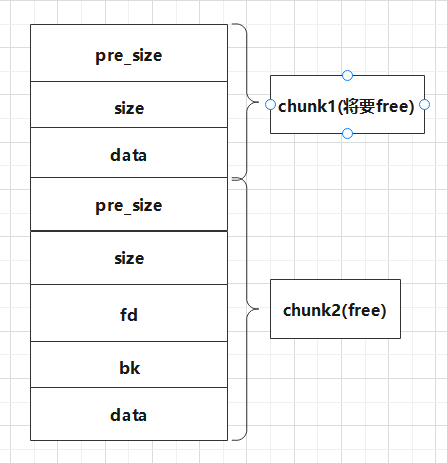
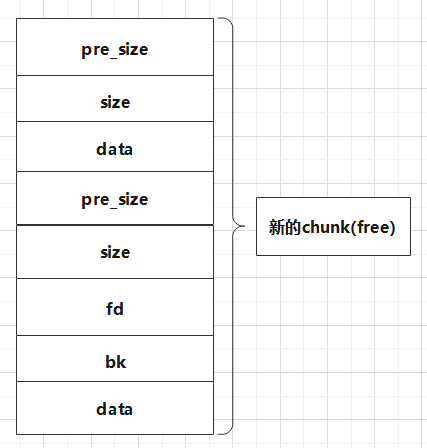
chunk将要被free时,通过 inuse_bit_at_offset 检测 后一个 chunk是否为free,如果是的话,将要被free的chunk会把它自己size加上nextsize(后一个chunk的大小),然后让新的chunk进入 unlink流程
向后合并(将要被free的chunk作为素材,被前一个chunk合并)
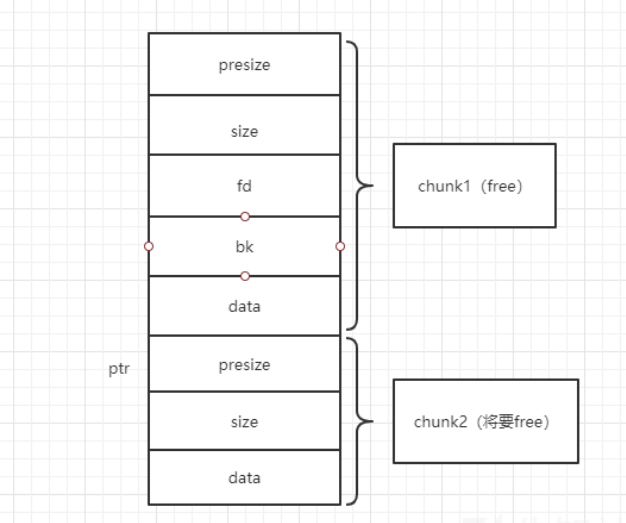
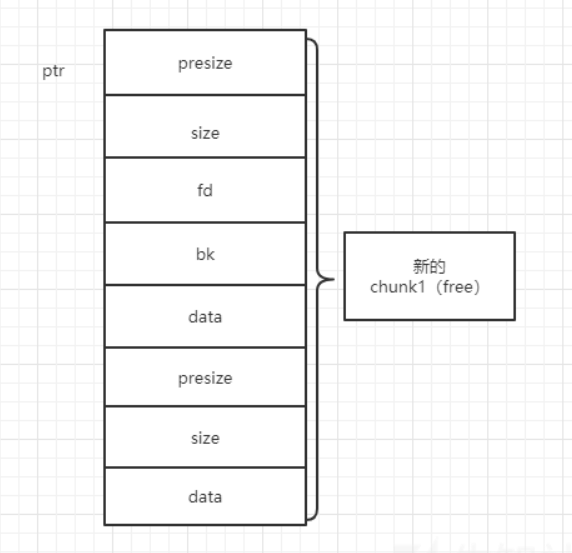
chunk将要被free时,通过 自己的sizeP位 检测 前一个 chunk是否为free,如果是的话,它会把它自己的size加到前一块chunk的size中 ,然后让新的chunk进入 unlink流程
unlink
unlink是一个宏操作,用于将某一个空闲chunk 从其所处的双向链表中脱链
1 | void unlink(malloc_chunk *P, malloc_chunk *BK, malloc_chunk *FD) |
unlink执行之前会先进行一个检查:
- 当前这个chunkP的后一个chunk的fd == chunkP 是否成立
- 当前这个chunkP的前一个chunk的bk == chunkP 是否成立
简单来说,它就是检查了:
- chunkP的下一个chunk的上一个chunk是不是chunkP
- chunkP的上一个chunk的下一个chunk是不是chunkP

解释unlink函数:
- FD->bk = BK:让P结构体的下一个结构体中的 bk 变为 P本身的bk
- BK->fd = FD:让P结构体的上一个结构体中的 fd 变为 P本身的fd
就相当于跳过了P这个结构体,把 FD 和 BK 连接

off-by-one的利用姿势
off-by-one有多种利用方式:
- 覆盖低字节数据(如果是地址,还可以改变其指向)
- 覆盖“size的P位”为“\x00”,伪造上一个为“free chunk”(allocate chunk的“presize”是上一个allocate chunk的数据区,所以可以溢出一字节刚好到P位)
常见的造成off-by-one的原因:
- strlen 和 strcpy 行为不一:strlen 计算字符串长度时是不把结束符
'\x00'计算在内的,但是 strcpy 却会拷贝 ‘\x00’ ,导致了off-by-null - ( (&list + index) + read(0, *(&list + index) , size) ) = 0:在read写入的字节后加一个“\x00”,这种操作可以中断“打印模块”(许多打印函数会被“\x00”中断),但它也溢出了一个“\x00”出去
这里介绍一种特殊的利用姿势,可以实现WAA(又叫做Unlink攻击)
条件:可以利用UAF漏洞编辑free chunk
目的:溢出一字节,改变后一个chunk的presize, 导致其后向合并判断错误
那如果我们在“chunk1”中伪造一个“chunkF”,溢出一字节改变“chunk2”的presize,然后free掉chunk2执行后向合并,就会出现很奇妙的结果

// 注意:这些操作都是在free chunk中进行的,所以有“presize”
伪装的“chunkF”被“chunk2”当成了合并的目标,如果“chunkF”的“ fd&bk ”控制的好,就可以在通过unlink检查的同时实现WAA(write anything anywhere)
//这里先简单提一提,到了分析Unlink攻击的再详细分析
libc版本限制
“libc-2.29.so”及其之后的版本加入了一个chunk检查:
1 | /* consolidate backward */ |
- 需要 prechunk->size == chunk->presize
由于我们难以控制一个真实 chunk 的 size 字段,所以传统的 off-by-null 方法失效,但是,只需要满足被 unlink 的 chunk 和下一个 chunk 相连,所以仍然可以伪造 fake_chunk
最后还要绕过 unlink 的检查,如果我们没法 leak heap_base,就要通过以下的办法进行绕过:
- 伪造的方式就是使用 large bin 遗留的 fd_nextsize 和 bk_nextsize 指针,以 fd_nextsize 为 fake_chunk 的 fd,bk_nextsize 为 fake_chunk 的 bk,这样我们可以完全控制该 fake_chunk 的 size 字段
- 也可以使用 unsorted chunk 或者 large chunk 的 FD BK 指针,就是对堆风水的要求比较高
- PS:伪造的方法在“Unlink攻击”中分析