dl_runtime_resolve源码分析
————深入理解ret2dlresolve
ret2dlresolve是一种高级的ROP技巧,目前我只是见识了一下题目
于是想通过分析 _dl_runtime_resolve 来搞懂 ret2dlresolve 的攻击核心点
前言-链接器&重定位
一般C语言程序到机器语言需要经过以下这些步骤:
1 | 预处理 -> 编译 -> 汇编 -> 链接 |
C语言代码经过编译以后,并没有生成最终的可执行文件(exe 文件),而是生成了一种叫做目标文件(Object File)的中间文件
可重定位目标文件,是目标文件的一种,它里面的代码与数据,都是各个文件独立的代码与数据
需要“链接”这个过程使它们建立联系并融合,而“链接”这个过程由链接器来完成
链接:
其实就是一个“打包”的过程,它将所有二进制形式的目标文件和系统组件组合成一个可执行文件(各个目标文件就会融合为一个可执行文件)
链接器:
1.符合解析:链接器会将重定位条目中的 所有引用 与 符号表中的符号 关联起来(这个符号可能在同一个可重定位目标文件中,也可能在其他可重定位目标文件中)
2.文件合并:将所有目标文件的同类型段合并
3.重定位:当所有目标文件合并完毕后,其各个段的地址都会有偏移,数据段和代码段中的相对地址都被链接器修正为最终的内存位置,这样所有的变量以及函数都确定了其各自位置
参考:
链接器:https://blog.csdn.net/qq_37375427/article/details/84947071
可重定位目标文件:https://blog.csdn.net/qq_45109990/article/details/103397772
重定位:https://segmentfault.com/a/1190000016433947
前言-GUN链接器(ld)
特点:
解决程序内部跨文件引用的链接时重定位
引用外部库文件的装载时重定位(为了加快加载速度还使用了延迟绑定)
链接时重定位(静态链接):在逻辑地址转换为物理地址的过程中,地址变换是在进程装入时一次完成的,以后不再改变
装载时重定位(动态链接):动态运行的装入程序把转入模块装入内存之后,并不立即把装入模块的逻辑地址进行转换,而是把这种地址转换推迟到程序执行时才进行,装入内存后的所有地址都仍是逻辑地址,这种方式需要寄存器的支持,其中放有当前正在执行的程序在内存空间中的起始地址
参考:
装载时重定位:https://zhuanlan.zhihu.com/p/317478523
装载时重定位:https://blog.csdn.net/parallelyk/article/details/42747239
ELF结构- dynamic 段
dynamic段是动态链接中最重要的段,它记录了和动态链接有关的段的类型,地址或者数值,指向了与动态链接相关的段
dynamic段包含了以下结构的一个数组:
1 | typedef struct { |
Elf_Dyn结构体由一个类型值加上一个附加的数值或指针组成
对每一个有该类型的object,d_tag控制着d_un的解释
d_tag类型 |
d_un的定义 |
|---|---|
#define DT_STRTAB 5(0x5) |
动态链接字符串表的地址,d_ptr表示.dynstr的地址 (Address of string table) |
#define DT_SYMTAB 6(0x6) |
动态链接符号表的地址,d_ptr表示.dynsym的地址 (Address of symbol table) |
#define DT_JMPREL 23(0x17) |
动态链接重定位表的地址,d_ptr表示.rel.plt的地址 (Address of PLT relocs) |
#define DT_RELENT 19(0x13) |
单个重定位表项的大小,d_val表示单个重定位表项大小 (Size of one Rel reloc ) |
#define DT_SYMENT 11(0xb) |
单个符号表项的大小,d_val表示单个符号表项大小 (Size of one symbol table entry ) |
32位:
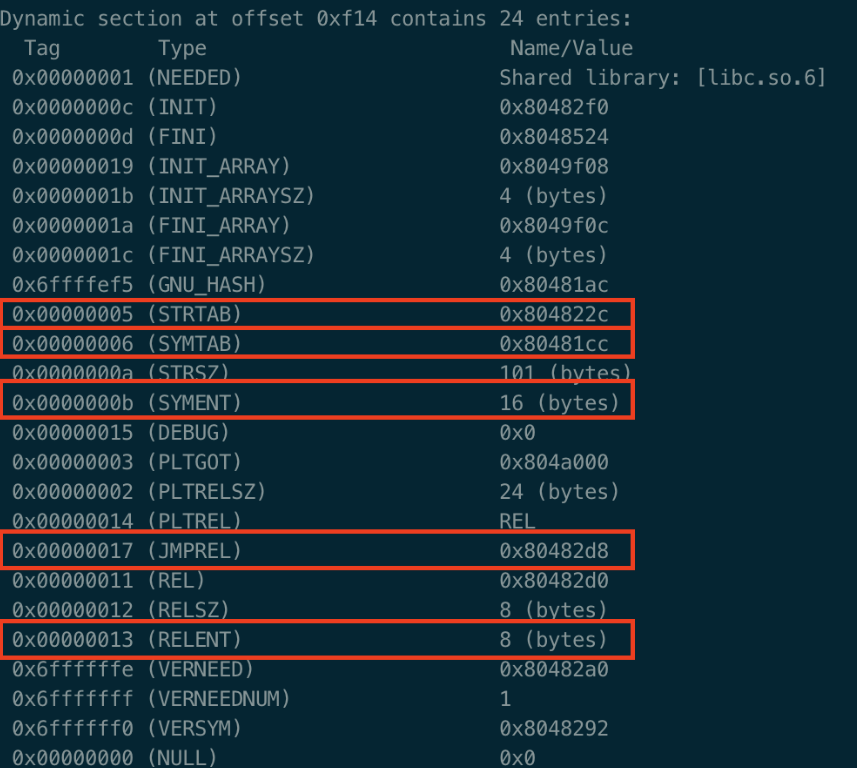
64位:
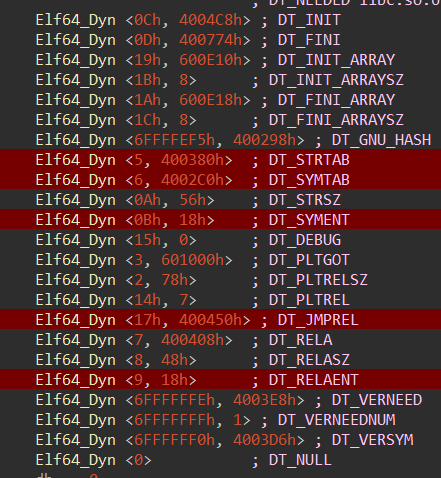
//64位和32位有些许不同:32位,DT_RELENT(0x13);64位,DT_RELAENT(0x9)
现在开始对最为重要的3个表进行介绍:
重定位表(jmprel) :位于rel.plt段,有结构体 Elf_Rel ,中包含了需要 重定位的函数 的信息
1 | typedef struct { |

//程序将对got表进行重定位,所以got表首地址就是“重定位入口”
符号表(symtab) :位于dynsym段,有结构体 Elf_Sym ,用于记录符号的关键信息
1 | typedef struct |

字符串表(strtab):位于dynstr段,无结构体,用于存储存储dysym符号表中的符号
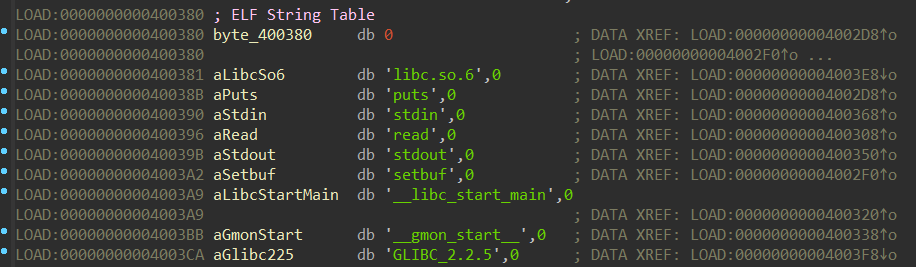
参考:
http://blog.chinaunix.net/uid-1835494-id-2831799.html
延迟绑定
Lazy Binding机制(延迟绑定):即只有函数被调用时,才会对函数地址进行解析,然后将真实地址写入GOT表中,第二次调用函数时便不再进行加载
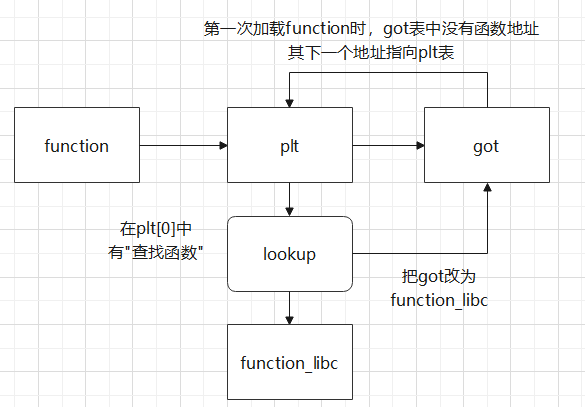
程序第一次识别函数“function”时,跳转plt表,然后跳转got表,接着返回plt[0],执行“lookup”
//检查函数“lookup”可以获取“function_libc”并执行,还会把它写入got表
在IDA中打开公共plt表:(plt[0])

push,jmp指令后就是got表地址

现在看上去这里没有东西,这是因为Lazy Binding在函数调用时才会进行解析


got表地址中:
got[0]:.dynamic段的起始地址
got[1]:link_map
got[2]:_dl_runtime_resolve 函数
got[3-n]:剩余的got表
在jmp指令执行后,相当于执行 _dl_runtime_resolve( link_map,reloc_arg )
注意:在被调用函数 自己的plt表 中会push一个值,然后在 公共plt表 中又会push一个值
//其实dl_runtime_resolve就是检查函数“lookup”
参考:https://www.cnblogs.com/unr4v31/p/15168342.html
分析dl_runtime_resolve
_dl_runtime_resolve用于对动态链接的函数进行重定位,是一段汇编语言
1.link_map_obj:结构体link_map,包含了动态装载器加载ELF对象需要的全部信息
2.reloc_arg:可以找到文件中.rel.plt表 ,标识了解析哪一个导入函数
1 | .text |
_dl_fixup:
1 |
1 | ElfW(Addr) __attribute ((noinline)) _dl_fixup ( struct link_map *__unbounded l, ElfW(Word) reloc_arg) |
简单来说:
1.dl_fixup会根据参数link_map可以找到.dynamic的地址
2.根据.dynamic的地址分别找到.rel.plt,dynsym,dynstr的地址
3.通过“_dl_lookup_symbol_x”计算出libc基地址,计算得目标在libc中的真实地址
4.最后写入got表
参考:
AT&T汇编:https://www.jianshu.com/p/0480e431f1d7
Link Map:https://www.shuzhiduo.com/A/Ae5RgZDrdQ/
重定位入口:https://www.cnblogs.com/fr-ruiyang/p/10457817.html
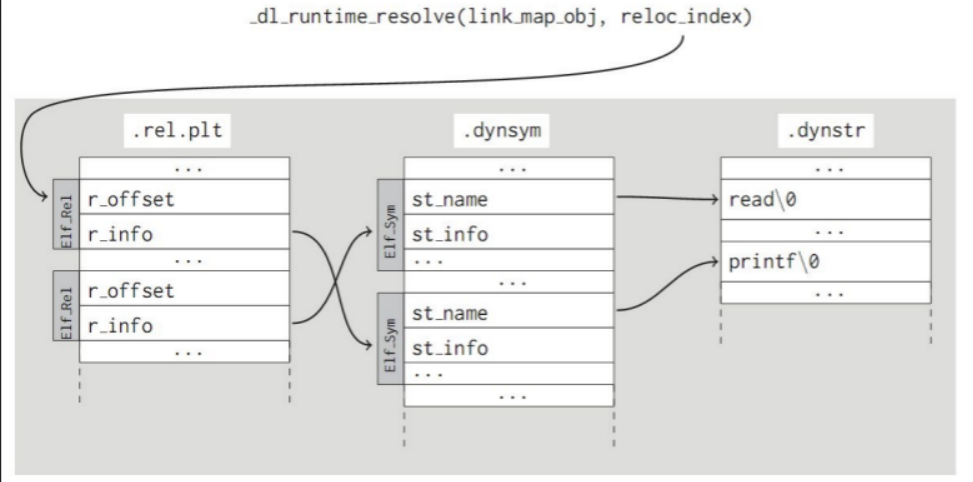
数据索引流程
不管是在dl_runtime_resolve中,还是在_dl_fixup中,都有许多“数据识别”的操作
函数_dl_runtime_resolve执行时,它需要知道搜索哪一个函数,获取对应的 符号 ,真实地址 等信息,这些都需要进行“数据识别”,那么对于每一个函数,必须有可以唯一确定它的身份的标识信息,同样,在“jmprel,symtab,strtab”中也必须有对应的标识信息来索引正确的数据
这个 “标识信息” 就是各个表中,各个元素的下标
然后我们就通过分析dl_runtime_resolve的执行过程来了解下标的作用:
1 | const ElfW(Sym) *const symtab = (const void *) D_PTR (l, l_info[DT_SYMTAB]); |
1.dl_runtime_resolve在搜索某个函数时,首先需要获取它在jmprel中的位置
1 | const PLTREL *const reloc = (const void *) (D_PTR (l, l_info[DT_JMPREL]) + |
这里的“reloc_offset”就是目标函数在jmprel中的下标,同时也是“reloc_arg”
“reloc_offset” + “jmprel” = “目标函数在jmprel中对应的位置”,保存于指针reloc中,指向对应结构体Elf_Rel
2.通过结构体Elf_Rel中的信息,获取dynsym中目标符号的位置:
1 | typedef struct { |
1 | const ElfW(Sym) *sym = &symtab[ELFW(R_SYM) (reloc->r_info)]; |
计算“r_info >> 8”得到目标函数在symtab中的下标(index)
“symtab[index]” = “目标符号在symtab中对应的位置”,保存于指针sym中,指向对应结构体Elf_Sym
3.通过结构体Elf_Sym中的信息,获取关键信息,并计算出 libc基地址:
1 | typedef struct |
1 | result = _dl_lookup_symbol_x (strtab + sym->st_name, l, &sym, l->l_scope,version, ELF_RTYPE_CLASS_PLT, flags, NULL); |
这里的“st_name”就是目标字符串在strtab中的下标
“st_name” + “strtab” = “对应的字符串”,传入_dl_lookup_symbol_x,而这个函数可以根据:link_map,sym(指向结构体Elf_Sym),version(版本信息),flags(标志)等各个信息综合分析,最终获取libc的基地址,保存于指针result中
4.根据libc基地址获取目标函数的真实地址:
1 | value = sym ? (LOOKUP_VALUE_ADDRESS (result)+ sym->st_value) : 0; |
“result” + “st_value” = “目标函数在libc中的真实地址”,存储于value中
5.图表如下:
1 | _dl_runtime_resolve(link_map, reloc_arg) |
总而言之:
传入参数reloc_arg就是重定位表的下标
“Elf32_Rel -> r_info” 的高24字节就是字符表的下标
“Elf32_Sym -> st_name” 就是字符串表的下标
//在上一个表中,存储有下一个表的下标
RELRO保护机制
系统保护机制 RELRO(Relocation Read-Only,重定位只读)
RELRO有3种形式:
1.No RELRO:
没有RELRO,.dynamic段可写,所以我们可以任意修改GOT表/plt表
2.Partial RELRO:
部分RELRO,.dynamic段不可写,不能修改plt表但是可以修改GOT表, 该ELF文件的各个部分被重新排序
3.FULL RELRO:
完全开启RELRO,启后 立即绑定 函数地址,.got段只读不可写,该ELF文件的各个部分被重新排序
FULL RELRO 可以限制 ret2dlresolve ,但是 Partial RELRO 是没有影响的
深入理解ret2dlresolve
ret2dlresolve通常有3种思路:
思路 1 - 控制dynamic(直接修改got表)
思路 2 - 控制重定位表项的相关内容
思路 3 - 伪造 link_map

这里我们重点分析“思路 3”:
函数_dl_runtime_resolve( link_map,reloc_arg )有一个漏洞:


//如果是32位系统,字长就变为4
它的参数都是直接从栈上取的,这样我们伪造栈,就可以伪造参数了
//栈顶为link_map,下一个栈空间就是reloc_arg
为了实现这一点,必须先进行栈转移来实现“完全控制”(输入值可以控制栈顶)
这里我们用经典题目 0ctf2018 babystack(32位)来介绍 ret2dlresolve 的过程:
此题的源文件很简单,就一个read函数,没有任何东西
1 | int main() |
先看常规攻击的exploit:(思路 3 - 伪造 link_map)
1 | from pwn import * |
根据 延迟绑定 机制,程序第一次调用某个函数时会调用函数 _dl_runtime_resolve 来获取它的真实地址,ret2dlresolve 也是在这一步动手脚,通过控制栈中的数据来伪造 _dl_runtime_resolve 的参数
1 | payload = 'a'*0x4 |
ret2dlresolve根据参数reloc_arg可以获取“Elf_Rel”,“Elf_Sym”,“str”等数据的地址
而我们通过栈转移把使SS:SP指向fake_stack,然后伪造“Elf_Rel”,“Elf_Sym”,“str”,最后伪造函数reloc_arg来误导程序把“aaaa”重定位成“system(‘/bin/sh’)”
//为什么这里是“aaaa”,在最后说明
先看正常的调用栈:
1 | 0000| 0xffffcf24 --> 0xf7ffd990 --> 0x0 //link_map |
再看伪造后的调用栈:
1 | 0000| bss_stage+4 --> plt_0 --> 0x0 |
伪造reloc_arg为index_offset,欺骗程序把“bss_stage+28”处的内容识别为Elf_rel
伪造Elf_rel中的r_info,欺骗程序把“bss_stage+36”处的内容识别为Elf_sym
伪造Elf_sym中的st_name,欺骗程序把“bss_stage+52”处的内容识别为str
1 | 0000| bss_stage+20 --> 'aaaa' |
一连串的伪造,最终欺骗程序把“aaaa”重定位为“system”,又因为dl_runtime_resolve会在重定位完成以后重新执行函数,所以可以获取shell
ret2dlresolve的利用过程很复杂,需要伪造相关的数据结构,但又比较固定,所以有许多工具来帮助我们实现ret2dlresolve,避免繁杂重复的过程
1.Pwntools中有专门针对ret2dlresolve的模块 >> Ret2dlresolvePayload
2.roputils就是为ret2dlresolve而生的
利用工具攻击的exploit:
1 | #coding:utf-8 |
注意:
32位依照这样打就可以了,但64位在这种情况下,如果像32位一样依次伪造reloc,symtab,strtab,会出错,原因是在_dl_fixup函数执行过程中,访问到了一段未映射的地址处
本篇博客重点介绍原理,所以就不介绍64位的情况了
今后我会在实战中
参考:
https://www.cnblogs.com/unr4v31/p/15168342.htm
https://www.anquanke.com/post/id/184099#h3-2
https://blog.csdn.net/qq_51868336/article/details/114644569 (核心)
PS:
为什么程序会调用“aaaa”呢?
1 | payload = 'a'*0x28 |
read_plt执行过程中,会输入新的payload到bss_stage中,执行结束后会返回leave_ret
这里的关键就是leave_ret,汇编语言leave本身会“pop ebp”一次,然后ret又一次“pop”控制ip指针
1.leave把bss_stage变为新的ebp,然后重置sp指针,这时bss_stage就是新的栈了
2.ret则会把新的栈中的栈顶弹入ip指针
而read_plt已经提前在它之中写入了数据:(节选)
1 | payload = 'a'*0x4 |
所以指令ret会把 ‘aaaa’ 弹到ip寄存器中,而程序没法识别 ‘aaaa’ ,所以会把它当成一个新的函数,然后会调用 ret2dlresolve 去尝试重定位这个函数,这时伪装就成功了